HTML字体字符之间的转换本质是将视觉上的字形编码映射为计算机可识别的Unicode或实体编码,核心在于理解字符集标准与浏览器渲染机制的差异,而非简单的文字替换。
在日常网页开发中,开发者经常遇到“为什么我写的字符在屏幕上显示为乱码”或者“如何确保特殊符号在所有设备上显示一致”的问题,这背后涉及的是HTML字符编码、字体回退机制以及字符实体引用等多重技术环节,解决这一问题的关键,不在于寻找一个万能转换工具,而在于掌握底层编码逻辑与前端渲染规范。
理解HTML字符编码的基础逻辑
字符在计算机中并非以“样子”存储,而是以数字编码存在,HTML作为一种标记语言,其核心任务是将这些数字编码正确地传递给浏览器,再由浏览器调用系统字体进行渲染。
字符集与编码标准的演变
早期的网页开发中,开发者常陷入ISO-8859-1、GBK、UTF-8等编码标准的迷雾中,业内专家指出,随着全球化互联网的普及,UTF-8已成为事实上的标准编码格式,它兼容ASCII,并能覆盖全球绝大多数语言的字符。
- ASCII码:仅包含英文字母、数字及基本符号,占用1个字节。
- GBK/GB2312:主要针对中文环境,包含简体中文字符,占用2个字节。
- UTF-8:可变长编码,兼容ASCII,支持全球几乎所有字符,是现代Web开发的首选。
当你在HTML文件中声明<meta charset="UTF-8">时,你实际上是在告诉浏览器:“请用UTF-8标准来解读我文件里的每一个字节。”如果声明错误,或者服务器返回的Content-Type头信息与文件实际编码不一致,浏览器就会尝试用错误的解码方式去解析字节流,从而导致“乱码”。
Unicode与UTF-8的关系辨析
许多初学者混淆Unicode和UTF-8,Unicode是一个字符集(Character Set),它给每个字符分配一个唯一的编号(Code Point),例如汉字的“中”对应的Unicode编号是U+4E2D,而UTF-8是一种编码方案(Encoding Scheme),它规定了如何将这个编号转换为二进制字节序列,以便在网络传输和文件存储中使用。

理解这一区别至关重要,因为不同的编码方案对同一字符的存储长度不同,UTF-8对英文字符使用1字节,对中文通常使用3字节,这种差异直接影响了文件的大小和传输效率,也是进行字符转换时需要考虑的性能因素。
HTML实体编码与特殊字符处理
在HTML源码中,某些字符具有特殊含义,如<、>、&,如果直接输入这些字符,浏览器会将其误认为是标签的开始或结束,导致解析错误,HTML提供了实体编码(Entity Codes)机制。
常见特殊字符的转换规则
处理特殊字符是前端开发的基本功,以下是几种常见的转换场景:
- 小于号与大于号:使用
<代表<,使用>代表>,这在显示代码示例时尤为重要,例如<div>在源码中必须写为<div>才能正确显示。 - 与符号:使用
&代表&,如果直接在URL或文本中使用&,在某些严格的XML解析器中会导致错误。 - 空格处理:HTML默认会忽略多余的空格,如果需要保留多个连续空格,需使用
(不换行空格)或 、 (不同宽度的空格)。
数字实体与十六进制实体的选择
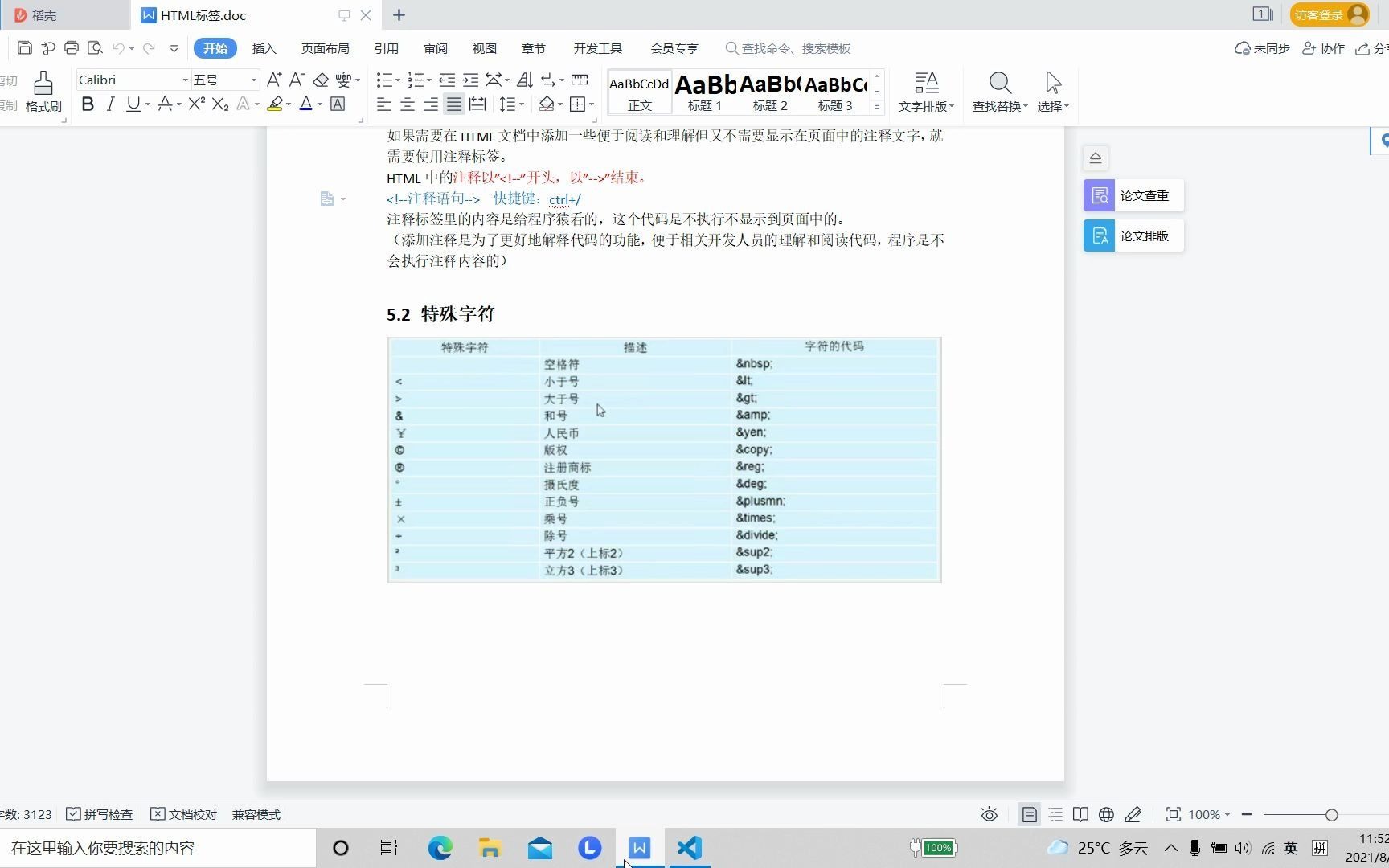
除了常见的命名实体(如©),HTML还支持数字实体,版权符号©可以写成©(十进制)或©(十六进制)。
- 命名实体:可读性强,易于记忆,如
。 - 数字实体:适用范围更广,对于没有命名实体的特殊符号,必须使用数字实体。
在构建html字体字符之间的转换工具或库时,通常建议优先使用命名实体,以提高代码的可维护性,但对于动态生成的内容,数字实体往往更具通用性,因为它不依赖于特定的字符集命名规范。
字体回退机制与跨平台显示一致性
即使编码正确,字符的显示效果仍可能因用户设备的字体配置不同而产生差异,这就是字体回退(Font Fallback)机制的作用。

CSS字体栈的配置策略
为了确保中文字体在不同操作系统上显示美观,开发者通常会在CSS中定义字体栈(Font Stack)。
body {
font-family: "PingFang SC", "Microsoft YaHei", "Helvetica Neue", Arial, sans-serif;
}
- PingFang SC:优先调用macOS和iOS系统的苹方字体。
- Microsoft YaHei:次选Windows系统的微软雅黑。
- Helvetica Neue:英文字体回退。
- Arial:通用无衬线字体。
- sans-serif:最后的兜底方案,调用系统默认无衬线字体。
这种层层递进的配置方式,确保了无论用户处于何种环境,都能获得相对一致的视觉体验,值得注意的是,不同系统对中文字体的渲染引擎存在差异,可能导致字重、字间距的细微差别,这在UI设计中需要预留足够的容错空间。
Web字体(Web Fonts)的应用
对于品牌一致性要求极高的场景,开发者会选择使用Web字体,通过@font-face规则,可以将自定义字体文件嵌入网页。
- 格式选择:WOFF2是目前压缩率最高、兼容性较好的格式,其次是WOFF。
- 加载优化:使用
font-display: swap;策略,确保在字体加载完成前,文本内容可见,避免FOIT(字体不可见文本)问题。
虽然Web字体解决了显示一致性问题,但也增加了HTTP请求和文件大小,仅对关键标题或品牌Logo使用Web字体,正文仍建议使用系统字体栈,以平衡视觉效果与性能。
常见误区与实操建议
在处理HTML字符转换时,开发者常陷入一些误区,导致问题复杂化。
过度依赖第三方转换工具
许多开发者习惯使用在线工具将中文转换为Unicode编码或HTML实体,这种做法在静态页面中可行,但在动态内容生成中往往适得其反,直接存储原始字符(UTF-8格式),让后端或前端在渲染时处理编码,是更灵活且易于维护的方案。

忽视HTTP头部的编码声明
仅在HTML文件中声明<meta charset="UTF-8">是不够的,如果服务器返回的HTTP响应头中Content-Type未指定charset,或者指定了错误的编码,浏览器可能会优先遵循HTTP头,导致HTML中的声明失效,确保服务器配置(如Nginx、Apache)与HTML元数据一致至关重要。
实操步骤:排查乱码问题
- 检查文件编码:使用编辑器(如VS Code)右下角查看并保存为UTF-8无BOM格式。
- 验证HTML声明:确保
<head>中包含<meta charset="UTF-8">。 - 检查HTTP头:使用浏览器开发者工具的Network面板,查看Response Headers中的Content-Type是否包含charset=UTF-8。
- 测试特殊字符:在页面中插入
、©及生僻汉字,观察渲染结果。
FAQ:html字体字符之间的转换常见问题
为什么我的中文网页在服务器上显示乱码,本地却正常?
这通常是由于服务器返回的HTTP响应头编码与HTML文件实际编码不一致导致的,本地开发时,浏览器可能默认使用UTF-8解析,而服务器(如Nginx或Apache)可能配置了GBK或其他编码,解决方法是在服务器配置中强制指定charset=utf-8,或在HTML头部明确声明,并确保两者统一。
如何将特殊符号转换为HTML实体?
手动转换效率低下且易出错,建议使用现代前端构建工具(如Webpack、Vite)配合插件自动处理,对于少量字符,可直接使用HTML实体命名(如&)或数字实体(如&),在JavaScript中,可以使用document.createTextNode()方法自动转义特殊字符,避免XSS攻击风险。
UTF-8和GBK编码下,同一个汉字占用的字节数一样吗?
不一样,在UTF-8编码中,常用汉字通常占用3个字节,而GBK编码中,汉字固定占用2个字节,这意味着UTF-8文件体积通常比GBK大,但换来了全球字符的兼容性和Unicode标准的统一支持,在存储和传输成本敏感的移动端场景,需权衡体积与兼容性。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/362200.html