HTML5语音识别技术通过浏览器原生API实现无需后端转发的实时语音输入,其核心优势在于低延迟、高隐私保护及零开发成本,是构建轻量级Web应用的首选方案。
在移动互联网向Web3.0演进的当下,用户对于交互效率的要求达到了前所未有的高度,传统的点击、滑动操作已无法满足所有场景,尤其是对于行动不便群体或需要双手忙碌的用户而言,语音交互成为了刚需,HTML5语音识别(Web Speech API)的出现,彻底改变了这一局面,它允许开发者直接在网页中调用浏览器的麦克风权限,将用户的语音实时转换为文本,这种技术不仅简化了开发流程,更极大地提升了用户体验。
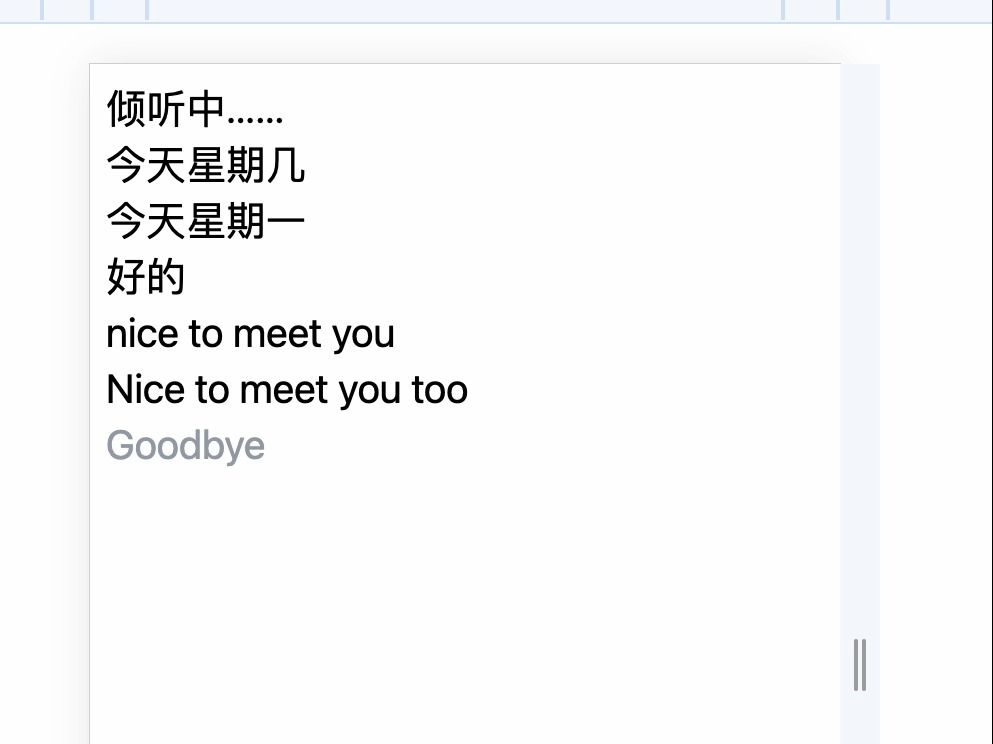
HTML5语音识别技术原理与核心优势
要理解这项技术,首先要明白它并非简单的录音转文字,它依赖于浏览器内置的语音引擎,通过JavaScript接口与用户进行交互,这种架构决定了其独特的优势,特别是在处理敏感数据和快速原型开发时。
隐私保护与数据本地化
在数据安全日益重要的今天,用户对于个人信息的泄露有着极高的警惕性,许多企业级应用,如医疗记录录入、法律访谈摘要等,对数据隐私有着严苛要求,传统方案通常将音频上传至云端服务器进行处理,这带来了潜在的数据泄露风险,而HTML5语音识别在多数现代浏览器中支持本地处理模式。
业内专家指出,当配置得当且使用支持本地引擎的浏览器时,音频数据无需离开用户设备,这意味着用户的隐私得到了根本性的保障,对于注重数据合规性的企业来说,这是一个巨大的卖点,无需搭建昂贵的后端语音处理集群,也无需担心第三方服务商的数据留存政策,开发者可以更专注于业务逻辑本身。
开发效率与成本优势
对于初创团队或个人开发者而言,时间就是金钱,引入第三方语音SDK往往伴随着高昂的授权费用、复杂的集成流程以及持续的服务维护成本,相比之下,HTML5语音识别几乎是“零成本”的。
- 无需后端依赖:大部分功能可在前端独立完成,减少了服务器负载。
- 集成简单:只需几行JavaScript代码即可实现基础功能。
- 跨平台兼容:主流浏览器(Chrome、Edge、Safari等)均提供支持,无需针对不同操作系统开发独立应用。

这种轻量级的特性,使得HTML5语音识别成为构建快速原型(MVP)的理想选择,开发者可以在短时间内验证语音交互的可行性,而无需投入大量资源进行底层技术攻关。
HTML5语音识别实战:从入门到精通
理论再好,不如动手实践,HTML5语音识别的核心接口是webkitSpeechRecognition(或标准的SpeechRecognition),下面我们将通过具体的代码示例和操作步骤,展示如何快速搭建一个语音输入框。
基础环境配置
确保你的运行环境支持HTTPS协议,现代浏览器出于安全考虑,通常要求麦克风权限必须在安全上下文中使用,这意味着你不能在HTTP网站或本地文件系统中直接调用该API,除非你使用localhost进行本地开发测试。
创建HTML结构
一个简单的输入框和按钮是基础,我们需要一个区域来显示识别结果,以及一个按钮来触发录音。
<button id="startBtn">开始录音</button> <button id="stopBtn">停止录音</button> <div id="result"></div>
JavaScript核心逻辑
接下来是关键的JavaScript部分,我们需要初始化识别对象,并设置事件监听器。
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
const recognition = new SpeechRecognition();
recognition.lang = 'zh-CN'; // 设置语言为中文
recognition.continuous = true; // 允许连续识别
recognition.interimResults = true; // 允许显示中间结果
recognition.onresult = function(event) {
let transcript = '';
for (let i = event.resultIndex; i < event.results.length; i++) {
transcript += event.results[i][0].transcript;
}
document.getElementById('result').innerText = transcript;
};
document.getElementById('startBtn').onclick = function() {
recognition.start();
};
document.getElementById('stopBtn').onclick = function() {
recognition.stop();
};
这段代码展示了最核心的流程:初始化、设置语言、监听结果、触发开始/停止,开发者只需根据实际需求调整参数,即可实现基本的语音输入功能。
HTML5语音识别与云端API对比分析

在实际项目中,开发者常常面临选择困难:是使用浏览器原生的HTML5语音识别,还是接入百度、阿里云等提供的云端语音API?这两者各有优劣,适用于不同的场景。
性能与延迟对比
HTML5语音识别的优势在于低延迟,由于数据可能在本地处理,或者通过浏览器优化的通道传输,响应速度通常快于传统的云端API,对于需要实时反馈的场景,如语音助手、实时字幕生成,HTML5方案更具优势。
云端API在识别准确率上往往更高,它们拥有更庞大的语料库和更先进的AI模型,能够处理复杂口音、专业术语以及背景噪音,据统计,在嘈杂环境下,云端API的识别准确率显著高于浏览器原生方案。
成本与适用场景
为了更直观地展示差异,我们可以通过以下表格进行对比:
| 特性 | HTML5语音识别 | 云端语音API |
|---|---|---|
| 部署难度 | 极低,前端即可实现 | 较高,需配置后端服务 |
| 识别准确率 | 中等,依赖浏览器引擎 | 高,拥有专业AI模型 |
| 隐私安全性 | 高,支持本地处理 | 中,数据需上传服务器 |
| 成本 | 免费 | 按调用量收费,成本较高 |
| 适用场景 | 简单输入、内部工具、原型开发 | 客服系统、高精度转录、多语言支持 |
业内共识认为,如果项目对准确率要求极高,或者需要支持多种小众语言,云端API是更好的选择,但如果项目侧重于快速开发、隐私保护或成本控制,HTML5语音识别则是更优解。
HTML5语音识别常见问题与解决方案
尽管HTML5语音识别提供了便捷的接口,但在实际应用中,开发者仍会遇到一些挑战,了解这些问题及其解决方案,有助于提高项目的稳定性和用户体验。

浏览器兼容性差异
虽然大多数现代浏览器都支持Web Speech API,但不同浏览器的实现细节存在差异,Safari浏览器对语音识别的支持有限,且在某些版本中可能需要手动启用,开发者在发布前,务必进行多浏览器测试,确保核心功能在目标用户群体常用的浏览器中正常运行。
网络稳定性影响
即使使用本地引擎,浏览器的语音识别功能也可能依赖网络进行模型更新或辅助识别,在不稳定的网络环境下,识别延迟可能会增加,甚至导致识别失败,建议在网络较差的情况下,提供备选方案,如手动输入或上传录音文件进行后续处理。
权限获取失败处理
用户可能会拒绝麦克风权限,或者浏览器出于安全考虑阻止自动播放,开发者需要在代码中加入完善的错误处理机制,友好地提示用户如何开启权限,而不是直接报错退出。
HTML5语音识别相关问答
HTML5语音识别支持哪些语言?
HTML5语音识别支持多种语言,具体取决于浏览器引擎,主流浏览器如Chrome和Edge支持中文、英文、日文、韩文等数十种语言,开发者可以通过设置recognition.lang属性来指定所需语言,需要注意的是,部分小众语言可能仅在特定浏览器或地区版本中可用。
HTML5语音识别在移动端的表现如何?
在移动端,HTML5语音识别的表现因操作系统和浏览器而异,Android设备上的Chrome浏览器通常提供较好的支持,而iOS设备上的Safari浏览器支持相对有限,近年来,随着移动浏览器技术的进步,移动端语音识别的准确率和使用体验均有显著提升,多数情况下,移动端用户可以直接使用系统自带的语音输入法,这与Web Speech API有异曲同工之妙。
HTML5语音识别的价格是多少?
HTML5语音识别本身是免费的,它是浏览器内置的功能,无需支付额外的授权费用或按调用量付费,这对于预算有限的开发者和小型项目来说,是一个巨大的优势,相比之下,云端语音API通常按分钟或调用次数收费,长期使用成本较高,在满足功能需求的前提下,HTML5语音识别是更具性价比的选择。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/362620.html