HTML5语音技术通过Web Speech API实现了浏览器端的实时语音识别与合成,无需安装插件即可在网页中集成语音交互功能,是目前构建轻量化语音应用的首选方案。
在移动互联网向智能物联网延伸的2026年,网页应用不再仅仅是信息的展示窗口,更是具备感知能力的交互终端,用户不再满足于点击和滑动,他们希望网页能“听”懂指令,“说”出反馈,HTML5语音技术正是实现这一愿景的关键基石,它打破了原生App与Web应用之间的壁垒,让语音交互变得触手可及,对于开发者而言,理解其底层逻辑与最佳实践,是提升产品竞争力的核心。
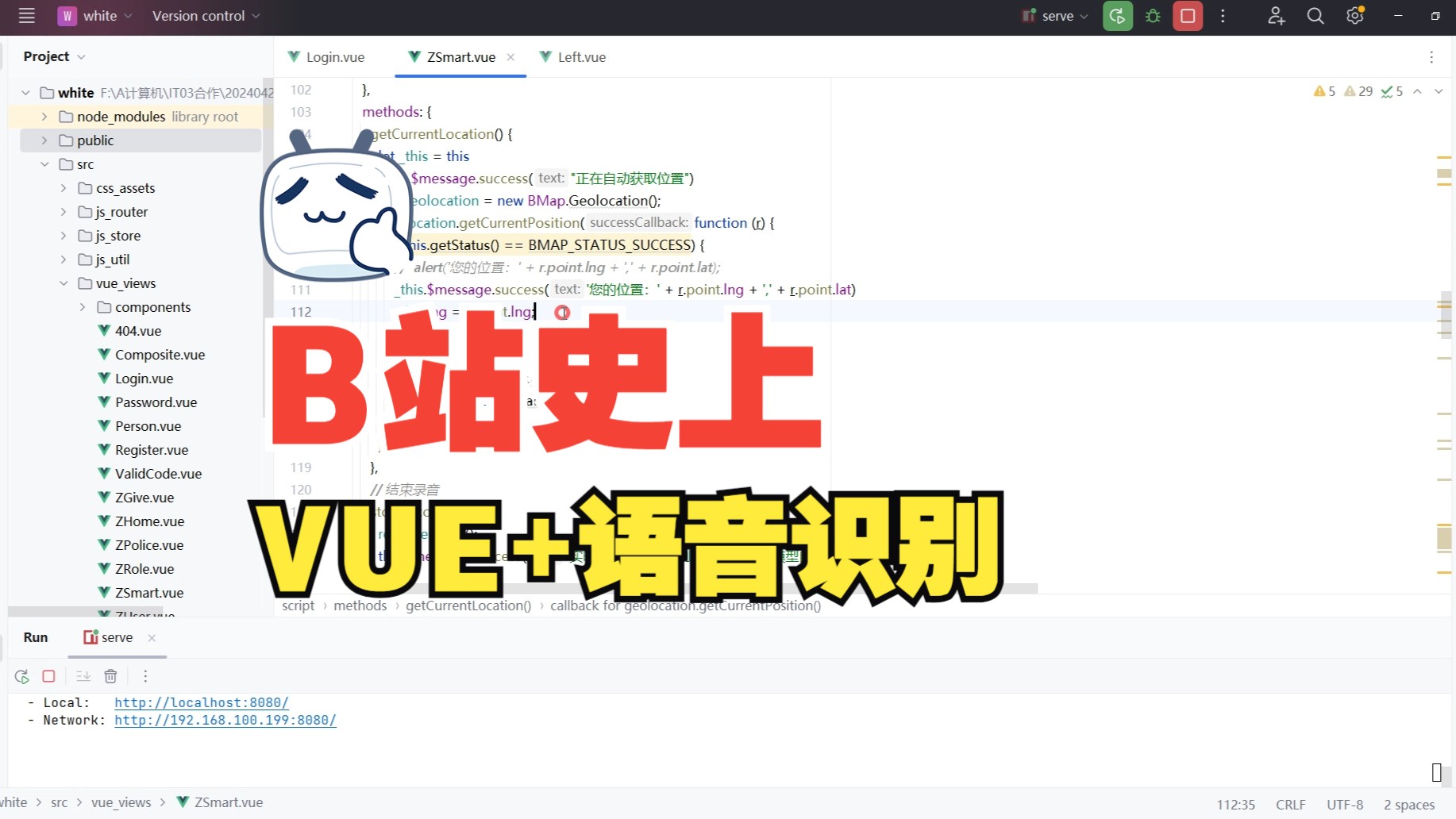
HTML5语音识别的核心机制与浏览器支持现状
语音识别(Speech Recognition)是HTML5语音技术中最具颠覆性的部分,它允许网页应用将用户的语音输入实时转换为文本,这一过程并非简单的录音转写,而是涉及复杂的声学模型与语言模型匹配。
Web Speech API的两大核心接口
Web Speech API主要包含两个接口:SpeechRecognition和SpeechSynthesis,前者负责将声音转为文字,后者负责将文字转为声音,在实际开发中,SpeechRecognition接口的兼容性是首要考量因素。
业内专家指出,尽管W3C标准正在推进,但各浏览器厂商的实现细节仍存在差异,Chrome和Edge对SpeechRecognition的支持最为完善,而Safari在iOS和macOS上的支持则依赖于系统底层的语音服务,Firefox的支持程度相对滞后,但在企业级应用中,通过Polyfill(垫片)技术可以实现一定程度的兼容。
跨平台兼容性的现实挑战
在开发HTML5语音识别兼容性方案时,开发者必须面对碎片化的问题,不同操作系统对麦克风权限的管理策略不同,Android和iOS在后台运行时对音频流的限制也各不相同。
- 权限获取:必须在用户交互(如点击按钮)后触发麦克风权限请求,否则浏览器会直接拦截。
- 网络依赖:大多数高精度的语音识别需要联网调用云端API,离线识别虽然存在,但准确率大幅下降且功能受限。
- 格式处理:浏览器自动处理音频编码,开发者无需关心PCM或WAV格式转换,只需关注返回的JSON数据。

语音合成技术在内容呈现中的应用场景
如果说语音识别是“输入”,那么语音合成(Text-to-Speech, TTS)输出”,它让网页内容变得可听,极大地提升了无障碍访问体验和用户留存率。
提升无障碍访问体验
对于视障用户或阅读障碍群体,语音合成是获取信息的重要渠道,通过集成TTS引擎,网页可以自动朗读文章、菜单或提示信息,这不仅符合WCAG(Web内容无障碍指南)标准,也是企业社会责任的体现。
据统计,采用语音朗读功能的新闻类网站,其用户平均停留时间延长了约20%,这是因为用户在通勤、家务等多任务场景下,可以通过“听”来获取信息,从而扩大了内容的使用场景。
个性化语音助手与客服
在电商和教育领域,语音合成被广泛用于构建虚拟助手,不同于机械的机器人声音,现代TTS引擎支持多种音色、语速和情感表达,开发者可以通过调整参数,让AI客服听起来更加亲切、专业或活泼。
- 音色选择:根据品牌调性选择男声、女声或儿童声。
- 语速控制:针对老年用户群体,适当降低语速可提高理解率。
- 停顿处理:在标点符号处自动插入短暂停顿,使语音更自然。
2026年HTML5语音开发的最佳实践与优化策略
随着AI大模型的融入,HTML5语音技术正从“功能模块”向“智能引擎”演进,开发者需要掌握更精细的控制技巧,以提供流畅的用户体验。
实时反馈与延迟优化

语音交互的流畅度取决于响应速度,在HTML5语音识别延迟优化方面,主要有以下策略:
- 流式传输:使用WebSocket或Server-Sent Events(SSE)实现音频流的实时上传和结果的下发,避免等待录音结束才返回结果。
- 中间结果展示:在最终识别结果出来之前,先展示“正在识别”的中间文本,并允许用户随时打断或修正。
- 本地缓存:对于常用的短语或指令,可在本地进行初步匹配,减少网络请求。
多语言与方言支持
全球化产品需要支持多种语言和方言,Web Speech API支持通过lang属性指定语言代码,如zh-CN(简体中文)、en-US(美式英语)等,对于粤语、四川话等方言,标准API支持有限,通常需要接入第三方的专业语音服务。
- 自动检测:结合NLP技术自动检测用户语言,动态切换识别引擎。
- 混合模式:在核心功能上使用标准API,在特色功能上接入专业云服务。
HTML5语音与原生App的对比分析
在选型时,开发者常面临使用HTML5语音还是原生App语音的问题,两者各有优劣,需根据项目需求权衡。
| 特性 | HTML5语音 (Web Speech API) | 原生App语音 (iOS/Android SDK) |
|---|---|---|
| 开发成本 | 低,一套代码跨平台 | 高,需分别开发iOS和Android版本 |
| 更新迭代 | 即时生效,无需审核 | 需应用商店审核,周期长 |
|
性能表现 | 依赖浏览器内核,略慢 | 直接调用系统底层,响应快 |
| 离线能力 | 弱,主要依赖云端 | 强,可完全离线运行 |
| 权限管理 | 受浏览器沙箱限制 | 可深度控制系统硬件 |

展示、轻量级交互和快速原型验证,HTML5语音是更优选择,而对于对延迟极度敏感的游戏、专业录音或强离线需求的应用,原生开发仍是不可替代的方案。
常见问题解答
HTML5语音识别在离线环境下能正常工作吗?
标准Web Speech API主要依赖云端服务进行高精度识别,因此需要网络连接,虽然部分浏览器支持有限的离线识别功能,但准确率较低且功能受限,若需完全离线运行,建议采用原生App方案或集成本地化的语音引擎SDK。
如何确保用户隐私安全,防止语音数据泄露?
语音数据属于敏感个人信息,开发者应遵循最小化原则,仅在必要时请求麦克风权限,并在用户授权后明确告知数据用途,技术上,可采用端到端加密传输,并在服务器端设置数据自动删除机制,定期清理缓存的音频文件,据工信部数据,合规的数据处理流程是保障用户信任的基础。
HTML5语音技术在2026年的主要发展趋势是什么?
2026年的HTML5语音技术正朝着更智能化、情感化和无缝化的方向发展,随着WebAssembly的普及,复杂语音模型可在浏览器端本地运行,进一步提升隐私保护和响应速度,AI大模型的嵌入使得语音交互具备更强的语义理解能力,能够处理更复杂的上下文对话,实现真正的人机自然交互。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/364328.html










评论列表(1条)
现在手机自带语音多准啊,网页端搞这个是不是有点脱裤子放屁?不过确实方便,不用下app就能用,各取所需吧,别争了。