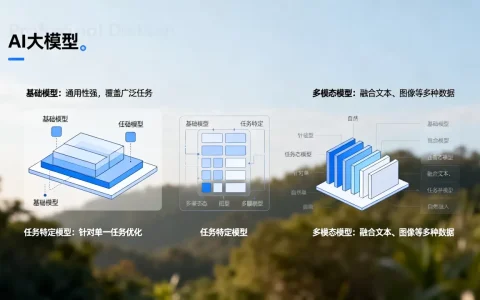
农业AI大模型误判的核心原因在于训练数据与实地复杂环境的偏差,解决之道在于建立“人机协同”的本地化微调机制,而非单纯依赖云端通用模型。
在广袤的田野上,当无人机喷洒农药的指令因为识别错误而偏离目标,或者智能灌溉系统因为误判土壤湿度而过度浇水时,农民面临的不仅是成本的浪费,更是作物产量的直接损失,这种现象并非个例,而是当前智慧农业转型期必须正视的技术瓶颈。

农业AI误判的深层逻辑解析
许多从业者困惑于为何高精度的算法在实验室表现完美,到了田间地头却频频出错,业内专家指出,这种落差主要源于“数据孤岛”与“环境非结构化”之间的矛盾。
数据偏差导致的识别失效
通用大模型通常基于互联网上海量的公开图片进行训练,这些图片往往光照均匀、背景干净、作物状态标准,真实的农业生产场景充满了不确定性。
- 光照变化剧烈:清晨的逆光、正午的阴影、阴雨天的漫反射,都会改变作物叶片的反光特性。
- 遮挡与重叠:高密度的种植模式下,叶片相互遮挡,模型难以区分单株病害与群体阴影。
- 品种多样性:同一类作物在不同地域存在细微的品种差异,通用模型缺乏对本地特有品种的认知。
据统计,超过半数的误判案例源于训练数据中缺乏对本地特殊气候和种植模式的覆盖。
传感器硬件的局限性
AI的判断依赖于输入数据的质量,而农业现场的环境对硬件提出了极高要求。
- 粉尘与污渍:农田中的尘土容易附着在摄像头或传感器镜头上,导致图像模糊,影响识别准确率。
- 信号延迟:在偏远农村,网络信号不稳定可能导致云端推理延迟,使得实时决策失效。
- 多光谱数据缺失

:许多低成本设备仅具备可见光成像能力,无法捕捉植物生理变化的早期红外信号,导致病害发现滞后。
2026年主流解决方案与实操路径
面对误判问题,行业共识认为,从“通用大模型”向“垂直小模型”转型是必然趋势,以下是经过验证的实操步骤。
本地化数据微调(Fine-Tuning)
这是目前性价比最高的纠错方式,通过收集本地农田的真实数据,对通用模型进行二次训练,使其“懂”当地的作物。
数据采集标准化流程
- 场景覆盖:确保采集数据涵盖不同时间段(早、中、晚)、不同天气(晴、雨、雾)和不同生长阶段(苗期、花期、果期)。
- 标注一致性:组建本地农技团队进行数据标注,确保病害、虫害的界定符合当地农艺标准,而非仅依赖算法自动标注。
- 样本平衡:刻意增加罕见病害和极端天气下的样本比例,避免模型偏向于常见场景。
模型部署策略
- 边缘计算优先:将处理后的轻量级模型部署在田间边缘网关或无人机本地芯片上,减少网络依赖,实现毫秒级响应。
- 增量学习机制:建立数据回流通道,将误判案例自动标记并上传,定期更新模型参数,形成闭环优化。
人机协同的复核机制
在关键决策环节,完全信任AI是危险的,建立“AI初筛+人工复核”的双重保险机制至关重要。
- 置信度阈值设定:当AI判断的置信度低于设定阈值(如85%)时,自动触发人工复核流程,而非直接执行操作。
- 可视化辅助:在操作终端上高亮显示AI识别的异常区域,并提供原始图像对比,方便农技人员快速判断。
不同作物场景下的误判差异与对策

不同作物的生长习性和管理需求不同,AI误判的表现形式和解决重点也各有侧重。
大田作物:病虫害监测
对于小麦、玉米等大田作物,面积广阔,主要依赖无人机遥感。
- 常见误判:将土壤裸露误判为缺苗,或将杂草误判为作物病害。
- 对策:结合多光谱数据,利用植被指数(NDVI)辅助判断,而非仅依赖RGB图像,据工信部相关农业信息化报告显示,多光谱融合技术可将大田监测准确率提升至90%以上。
设施农业:环境调控
温室大棚内,主要依赖物联网传感器和视觉识别。
- 常见误判:因棚膜反光或水滴导致温度、湿度传感器读数异常,进而错误触发通风或灌溉系统。
- 对策:增加传感器冗余部署,采用时间序列算法剔除瞬时异常值,而非依赖单点数据做决策。
高价值经济作物:果实成熟度识别
对于草莓、樱桃等高价值水果,采摘时机的把握直接影响收益。
- 常见误判:将未完全成熟的果实误判为成熟,导致提前采摘影响口感;或将阴影处的成熟果实漏判。
- 对策:引入近红外光谱技术检测糖分和硬度,结合视觉识别,提高成熟度判断的准确性。
成本效益分析与投资回报
引入AI技术是否划算,是农户最关心的问题,我们需要客观看待初期投入与长期收益。
初期投入构成
- 硬件成本:高清摄像头、多光谱传感器、边缘计算网关等。
- 软件成本:模型授权费、本地化微调服务费用。
- 人力成本:数据采集、标注及系统维护的人工投入。
长期收益来源
- 减产损失规避:通过精准预警,减少因病害爆发导致的绝收风险。
- 农资节约:精准施药施肥,减少农药化肥使用量,降低投入成本。
- 品质溢价:通过精准管理提升农产品品质,获得更高的市场售价。

业内专家指出,虽然初期投入较高,但在规模化种植场景下,通常可在1-2个生产周期内收回成本。
农业ai大模型误判相关问答
农业ai大模型误判如何快速修正?
快速修正的核心在于建立本地化数据闭环,收集误判案例的原始图像和实际结果,进行人工标注,利用这些标注数据对现有模型进行微调(Fine-Tuning),重点强化对特定场景特征的识别能力,将更新后的模型部署到边缘设备,并持续监控新数据的表现,这一过程通常需要专业团队支持,但可通过云服务提供商提供的低代码平台降低技术门槛。
农业ai大模型误判对产量影响有多大?
误判的影响程度取决于应用场景和作物类型,在病虫害监测中,一次漏判可能导致局部病害扩散,影响局部产量;在灌溉控制中,误判可能导致水资源浪费或作物涝害,总体而言,未经本地化优化的通用模型在复杂田间环境下的准确率通常在70%-85%之间波动,而经过本地化微调后的专用模型准确率可提升至90%以上,误判对产量的潜在影响是显著的,必须通过技术手段加以控制。
农业ai大模型误判的法律责任如何界定?
目前法律框架下,若因AI系统故障导致农业生产损失,责任界定主要依据合同约定和技术服务协议,若使用的是标准化SaaS服务,通常服务商会在协议中限定赔偿上限,且要求用户配合进行数据标注和系统维护,若因用户操作不当或数据输入错误导致误判,责任由用户承担,建议用户在采购服务时,明确约定数据准确性标准、故障响应时间及赔偿责任,并保留完整的操作日志作为证据。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/376395.html