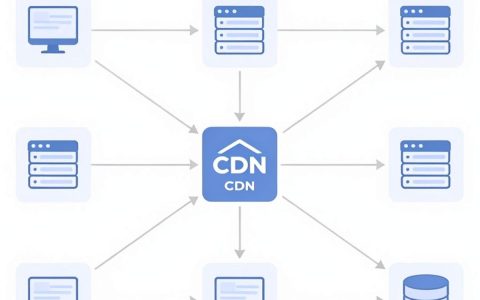
分布式数据库中间件开源是解决海量数据读写瓶颈、实现水平扩展的核心方案,其本质是在应用层与数据库层之间充当智能路由与事务协调器,而非替代底层存储引擎。
在2026年的技术语境下,企业面临的不再是简单的“存不下”问题,而是“高并发下的数据一致性”与“运维复杂度”之间的博弈,开源分布式数据库中间件通过屏蔽底层异构数据库的差异,让开发者像操作单机数据库一样操作集群,这已成为金融、电商及物联网领域的标准实践。

开源中间件的核心价值与选型逻辑
过去,开发者习惯直接连接MySQL或PostgreSQL,但在数据量突破TB级后,单节点性能触顶,分库分表成为必然,引入中间件并非为了炫技,而是为了解决具体的工程痛点。
业内专家指出,中间件的价值主要体现在三个维度:
- 透明化路由:应用无需关心数据存在哪个物理节点,中间件根据分片键自动将请求分发至正确节点。
- 全局事务支持:解决跨库事务的一致性难题,提供类似XA或TCC的分布式事务能力。
- 弹性伸缩:在不中断业务的前提下,动态增加或减少数据节点,实现存储与计算资源的解耦。
选型时,团队常纠结于“自研”还是“开源”,自研可控但维护成本极高,开源方案成熟度高但需评估社区活跃度,对于大多数中小企业而言,选择经过大规模生产验证的开源中间件是更理性的选择。
主流开源中间件对比分析
目前市场上主流的开源方案主要分为两类:一类是紧耦合的专用中间件,另一类是基于Proxy协议的通用代理。
| 特性维度 | 专用中间件 (如ShardingSphere) | 通用Proxy (如Vitess, ProxySQL) |
|---|---|---|
| 部署复杂度 |
中,需集成SDK或配置中心 | 低,纯透明代理,无侵入 |
| 功能丰富度 | 极高,支持读写分离、分库分表、加密 | 基础,侧重连接管理与负载均衡 |
| 适用场景 | 复杂业务逻辑,需精细控制SQL | 高并发读多写少,标准化SQL场景 |
| 运维成本 | 较高,需监控中间件状态 | 低,架构扁平,故障点少 |

据工信部相关数据显示,近年来采用透明代理架构的企业比例逐年上升,特别是在互联网大厂的非核心业务中,低侵入性成为首选。
分布式数据库中间件开源技术的落地实操
理论再好,不如落地一次,在实际项目中,部署开源中间件通常遵循标准化的路径,以下以常见的Java生态为例,梳理关键步骤。
环境准备与配置初始化
第一步是确定分片策略,这是整个架构的基石,一旦确定,后期迁移成本极高,常见的分片算法包括哈希取模、范围区间和日期分片。
- 定义逻辑库与表:在配置文件中声明逻辑表名,例如
order_table。 - 配置数据源:指定真实的物理数据源,如
ds_0,ds_1。 - 设置分片规则:定义分片键(如
user_id)和算法(如mod 2)。
配置文件示例结构
rules:
- !SHARDING
tables:
order_table:
actualDataNodes: ds_${0..1}.order_table_${0..1}
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: mod-algorithm
shardingAlgorithms:
mod-algorithm:
type: MOD
props:
sharding-count: 4

数据迁移与双写策略
从单体数据库迁移到分布式架构,最怕的是数据丢失或业务中断,业内共识认为,采用“双写+校验”的平滑迁移方案最为稳妥。
- 旁路监听,部署中间件,但不修改应用代码,仅通过Binlog同步工具将新数据写入新集群。
- 双写开启,修改应用代码,同时向旧库和新集群写入数据,此时以旧库为准,新集群作为冗余。
- 数据校验,使用专业工具对比新旧集群数据一致性,修复差异。
- 切流,将读请求切换至新集群,观察稳定性后,关闭旧库写入。
分布式数据库中间件开源方案的常见误区
许多团队在引入中间件后,性能反而下降,甚至出现数据不一致,这通常源于对技术边界的误解。
SQL兼容性的陷阱
分布式环境对SQL的支持远不如单机数据库全面。
- 禁止跨分片Join:除非中间件支持全局Join优化,否则跨节点Join会导致全表扫描,性能极差。
- 避免复杂聚合:
COUNT,SUM等聚合操作在分片后需要全局合并,增加网络开销。 - 分页难题:
LIMIT 1000000, 10这类深分页在分布式环境下效率极低,需通过游标或业务ID过滤优化。
运维监控的盲区
中间件引入了新的故障点,如果只监控数据库,而忽略中间件的健康状态,一旦中间件挂掉,整个应用将不可用。
- 连接池监控:监控中间件与后端数据库的连接数,防止连接泄露。
- 慢SQL追踪:开启慢SQL日志,分析路由效率,优化分片键选择。
- 流量整形:在高峰期限制非核心业务的查询,保护核心数据节点。
分布式数据库中间件开源的未来趋势
随着云原生技术的普及,中间件也在向无服务器化、智能化演进。

存算分离架构的融合
传统中间件往往与存储层绑定较紧,未来的趋势是中间件完全无状态化,存储层采用对象存储或分布式文件系统,这种架构下,计算节点可以无限弹性伸缩,存储成本大幅降低。
AI辅助的SQL优化
利用机器学习算法,中间件可以自动分析历史查询模式,动态调整索引策略和路由规则,自动识别热点数据,将其缓存至本地内存,减少网络IO。
多模态数据支持
除了关系型数据,中间件开始支持JSON、图数据等非结构化数据的分布式存储与查询,这对于物联网、社交网络等场景具有重要意义。
Q&A:分布式数据库中间件开源常见问题
分布式数据库中间件开源方案的价格是多少?
开源中间件本身通常免费,无需支付授权费用,但企业需承担硬件成本、运维人力成本以及潜在的商业支持服务费,对于大型金融机构,购买厂商的商业支持版本(如ShardingSphere-Proxy的商业版)是常见选择,价格根据集群规模和SLA等级而定,通常从数万元到数十万元不等。
分布式数据库中间件开源与云数据库有什么区别?
云数据库是托管服务,厂商负责底层运维、备份和扩容,用户无需关心中间件细节,适合快速起步,开源中间件需要用户自行部署、配置和维护,灵活性高,适合有强大运维团队、追求数据主权或混合云部署的企业,两者并非对立,云厂商也提供基于开源中间件的托管服务。
分布式数据库中间件开源适合中小型企业吗?
如果企业数据量在千万级以下,单机数据库配合读写分离即可满足需求,引入中间件会增加复杂度,得不偿失,但当数据量突破千万,且并发量持续增长时,中间件的价值显现,对于中小型企业,建议初期采用云厂商提供的Serverless数据库或轻量级分库分表方案,待规模扩大后再迁移至成熟的开源中间件架构,以平衡成本与技术风险。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/460045.html