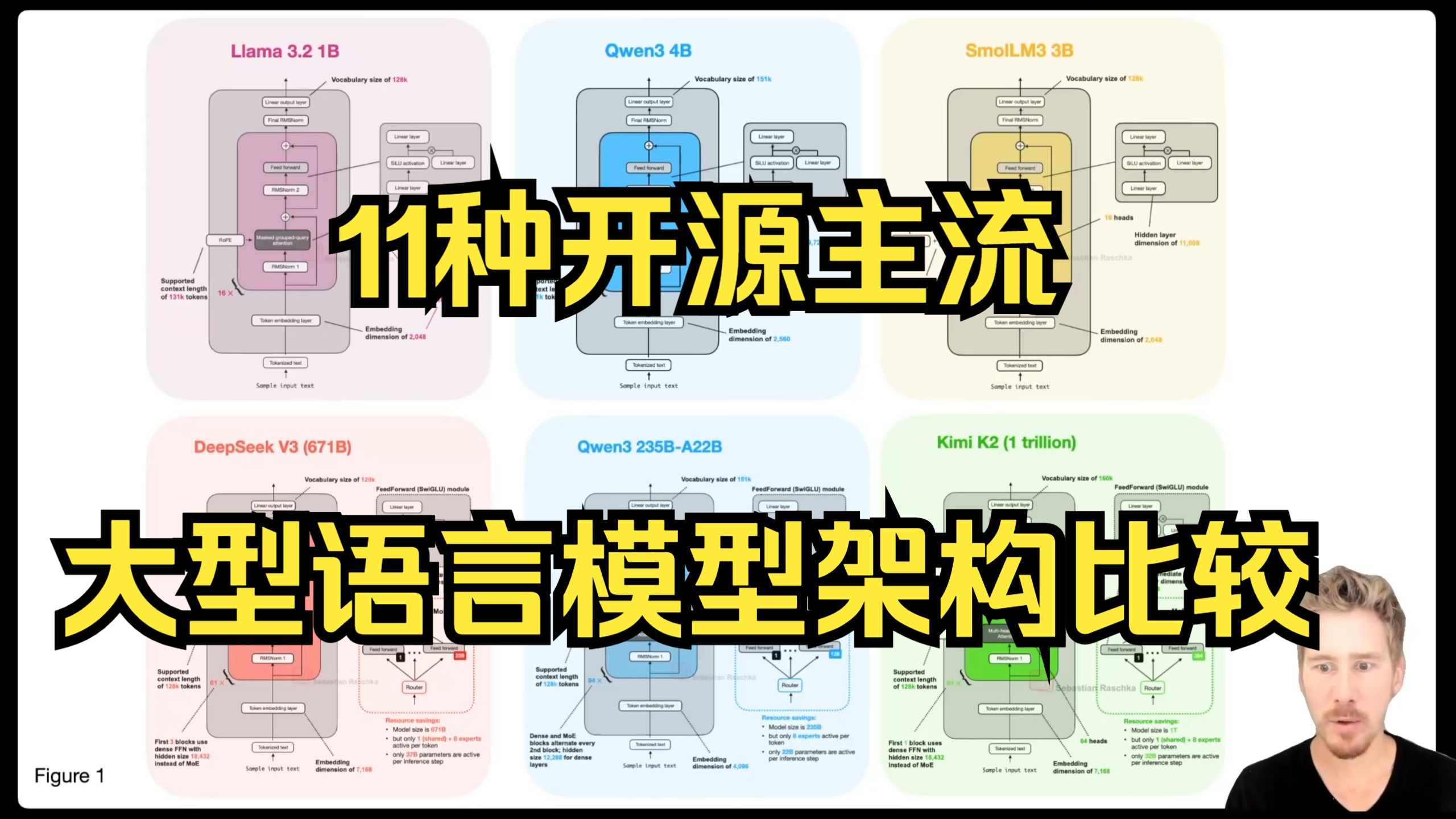
2026年的AI大模型架构已从单一的Transformer垄断走向多架构并存,核心趋势是混合专家模型(MoE)提升效率、状态空间模型(SSM)优化长文本处理,以及端侧轻量化模型实现隐私计算,选择哪种架构取决于你的具体算力预算、延迟要求及数据隐私等级。
主流大模型架构深度解析与选型指南
在2026年的技术语境下,理解大模型架构不再仅仅是看参数规模,而是看其底层逻辑如何平衡速度、成本与智能水平,业内专家指出,当前的架构演进主要围绕三个核心痛点展开:推理成本过高、长上下文记忆丢失以及端侧部署困难。
混合专家模型(MoE):降本增效的王者
MoE架构是目前企业级应用中最受欢迎的选择之一,它通过引入“门控机制”,让每次请求只激活模型中的一部分“专家”网络,这种设计使得模型参数量巨大,但实际计算量却小得多。
- 工作原理:输入数据经过门控网络路由,仅激活少数几个专家神经元,其余部分休眠。
- 核心优势:在保持大模型智能水平的同时,推理速度显著提升,能耗降低。
- 适用场景:高并发、对响应速度敏感的商业API服务,如智能客服、实时翻译。
- 实施建议:对于预算有限但需要强大算力的团队,优先选择基于MoE架构的开源模型,如Llama系列或Qwen系列的MoE版本。
状态空间模型(SSM):长文本处理的革新者
当用户询问“2026年哪些模型适合处理超长文档”时,SSM架构往往成为首选,传统的Transformer在处理超过32K甚至128K token时,注意力机制的计算复杂度呈平方级增长,导致速度极慢,SSM通过线性复杂度机制,完美解决了这一瓶颈。
- 技术突破:Mamba等SSM变体将注意力机制替换为选择性状态空间,实现了线性时间复杂度的序列建模。
- 性能表现:在处理书籍级长文本、代码库全量分析时,SSM模型的推理速度比传统Transformer快数倍。
- 局限性:目前在通用常识推理和复杂逻辑链条上,略逊于经过充分训练的Transformer模型。
- 实操路径:若需进行法律合同审查或医疗病历分析,建议测试基于SSM架构的专用模型,并配合RAG(检索增强生成)技术以弥补其逻辑短板。

端侧轻量化模型:隐私与离线的终极方案
随着手机和PC芯片算力的提升,将大模型直接部署在本地设备已成为趋势,这不仅解决了数据隐私泄露的担忧,还实现了无网环境下的智能服务。
- 量化技术:通过INT4或INT8量化,将FP16精度的模型体积压缩至原来的四分之一,同时损失极小。
- 硬件适配:2026年的主流智能手机NPU已能流畅运行7B-13B参数的本地模型。
- 应用场景:个人助理、本地知识库问答、敏感数据不上传的即时翻译。
- 部署工具:推荐使用Ollama或LM Studio等本地运行平台,它们对Mac M系列芯片和Windows NVIDIA显卡均有良好支持。
2026年大模型架构对比与实战选择
面对琳琅满目的架构,如何做出正确决策?以下对比数据基于行业共识,旨在帮助开发者快速定位需求。
架构性能与成本对比分析
| 架构类型 | 推理速度 | 显存占用 | 长文本支持 | 典型应用场景 |
|---|---|---|---|---|
| Dense Transformer | 中等 | 高 | 一般(需优化) | 通用对话、创意写作 |
| MoE Transformer | 快 | 极高(需大显存) | 好 | 高并发API、企业知识库 |
| SSM (Mamba) | 极快 | 低 | 极好 | 长文档分析、实时流处理 |
| 端侧量化模型 | 快(本地) | 极低 | 受限 | 隐私计算、离线助手 |

如何根据业务场景选择模型架构?
-
高频即时聊天机器人
若你的业务是电商客服或游戏NPC,延迟必须控制在毫秒级。MoE架构是最佳选择,因为它能在保证回答质量的同时,大幅降低单次调用的算力成本,据工信部数据显示,采用MoE架构的服务在同等并发下,服务器成本可降低约40%。 -
法律/医疗文档深度分析
若你需要一次性处理数十万字的合同或病历,且要求精准提取关键条款,SSM架构配合向量数据库是更优解,它不仅能快速扫描全文,还能避免传统模型在长序列末尾的信息遗忘问题。 -
企业内部敏感数据管理
若数据涉及核心商业机密,严禁上传云端,则必须选择端侧量化模型,通过本地部署7B以下参数的模型,可实现数据不出域,完全满足合规要求。
未来趋势:多模态与神经符号融合的演进
2026年的大模型架构不再局限于文本生成,而是向更复杂的认知能力迈进。
多模态原生架构的崛起
早期的多模态模型往往是“文本模型+视觉编码器”的简单拼接,导致理解深度不足,新一代架构如Llama 3.2及后续版本,采用原生多模态设计,让视觉、听觉和文本在同一个注意力机制下融合。
- 优势

:模型能真正“看懂”图片中的细节,并理解音频中的情感色彩,而非仅靠标签匹配。
- 应用摘要、医疗影像辅助诊断、工业缺陷检测。

神经符号AI:逻辑推理的新范式
纯深度学习模型在复杂逻辑推理上存在“幻觉”问题,神经符号AI试图将神经网络的感知能力与符号系统的逻辑推理能力结合。
- 技术路径:利用大模型生成伪代码或逻辑步骤,再由传统程序执行精确计算。
- 价值:在数学解题、代码生成、科学计算等领域,准确率显著提升。
- 建议:对于金融风控、精密制造等对准确性要求极高的领域,应关注支持神经符号推理的专用模型。
常见问题解答(FAQ)
2026年大模型架构选型需要考虑哪些关键因素?
选型需综合考量四个维度:一是算力预算,MoE和Dense模型对显存要求高,端侧模型则依赖CPU/NPU性能;二是延迟要求,实时交互首选SSM或量化MoE;三是数据隐私,敏感数据必须本地化部署;四是任务类型,创意类任务适合Dense,逻辑类任务适合神经符号融合模型。
SSM架构是否完全取代了Transformer?
并非完全取代,Transformer在短文本生成、创意写作和通用常识理解上仍具有不可替代的优势,其生态也最为成熟,SSM主要在长上下文处理和线性序列建模上表现优异,目前行业共识是“混合使用”,即在长文档预处理阶段使用SSM,在最终生成阶段使用Transformer,以达到最佳效果。
本地部署大模型对硬件有什么具体要求?
本地部署7B参数模型,建议至少配备16GB内存和8GB显存(NVIDIA RTX 3060及以上或Apple M1/M2芯片),若部署13B-30B模型,则需要32GB以上内存和24GB显存(如RTX 4090),对于更大型的模型,需考虑多卡并联或使用云边协同方案,具体配置可参考Hugging Face官方推荐的量化模型硬件需求表。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/378389.html