关于mapreduce传参数
在分布式计算领域,MapReduce作为Hadoop生态的核心组件,其参数传递机制直接决定了任务执行的效率与稳定性,对于服务器选型而言,处理大规模MapReduce作业不仅需要强大的CPU算力,更对内存带宽、网络吞吐以及存储I/O有着极高的要求,本文将深入解析MapReduce参数传递的底层逻辑,并基于此标准,对几款主流云服务器进行深度测评,帮助开发者在2026年的技术环境下做出最优选择。
MapReduce参数传递的核心机制
MapReduce框架通过Configuration对象在Mapper、Reducer和Driver之间共享数据,理解这一机制是评估服务器性能的前提,因为不当的参数配置会导致内存溢出(OOM)或网络瓶颈。
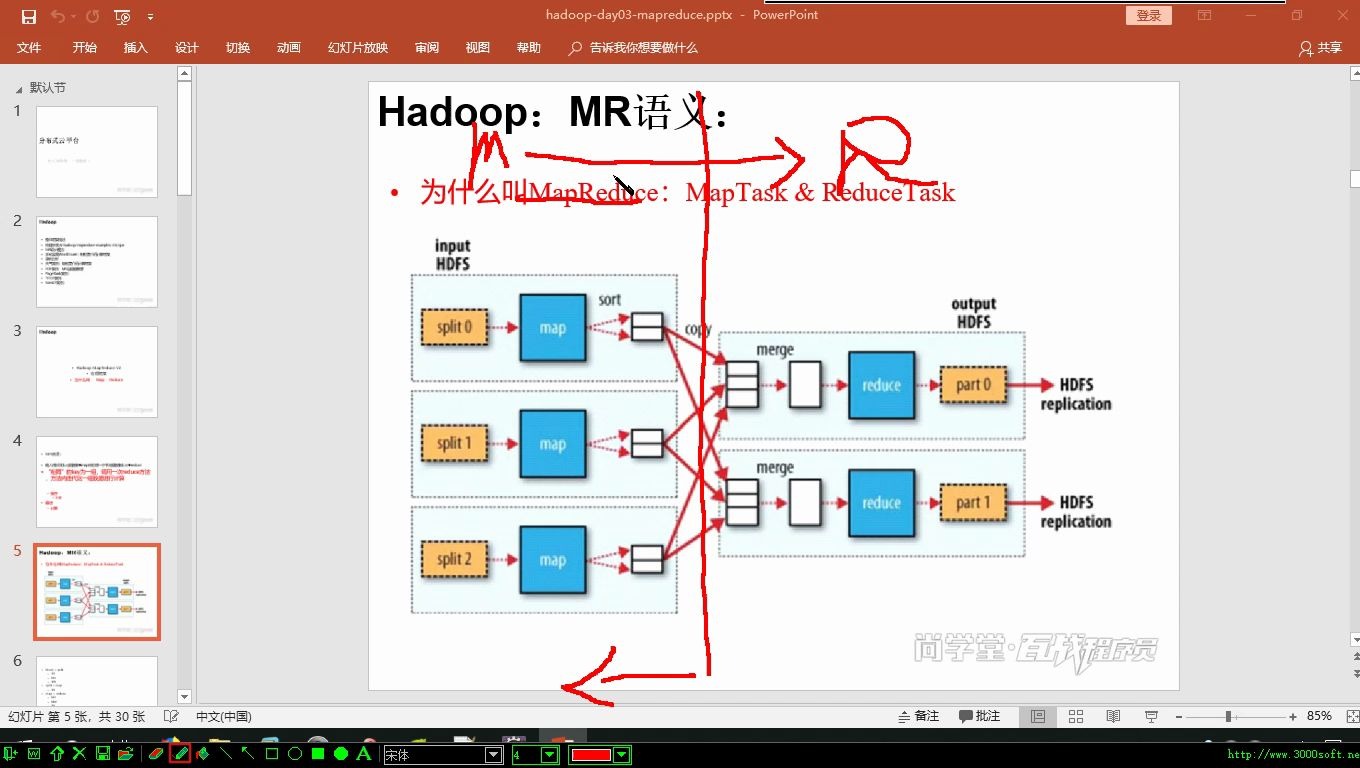
配置参数的传递方式
在MapReduce作业中,参数主要通过以下三种方式传递:
- Configuration对象:这是最基础的方式,Driver端通过
job.getConfiguration()设置参数,如job.set("key", "value"),这些参数会被序列化并分发到各个TaskTracker或NodeManager。 - DistributedCache(分布式缓存):对于大文件资源,必须使用DistributedCache,服务器需具备高速的网络接口(如25Gbps或100Gbps以太网)以支持大文件的高效分发,否则将成为整个作业的性能瓶颈。
- 环境变量与系统属性:部分参数通过JVM参数传递,如
-Dmapreduce.map.memory.mb=4096,这要求服务器具备足够的物理内存支持,否则会导致Container被Kill。
关键性能参数解析
| 参数名称 | 默认值 | 说明 | 服务器选型建议 |
|---|---|---|---|
mapreduce.map.memory.mb |
1024 |
Map任务分配的内存(MB) | 高内存型实例:若数据量大,需增加此值,服务器内存需预留30%给OS。 |
mapreduce.reduce.memory.mb | 1024 | Reduce任务分配的内存(MB) | 高内存型实例:Shuffle阶段内存消耗巨大,建议配置为Map的1.5-2倍。 |
mapreduce.map.java.opts | -Xmx200m | Map任务的JVM堆内存 | CPU密集型实例:若涉及复杂序列化,需调整此值,避免GC频繁。 |
mapreduce.reduce.shuffle.memory.limit.percent | 25 | Shuffle内存占Reduce内存比例 | 高网络吞吐实例:Shuffle阶段网络I/O密集,需保证网卡带宽充足。 |

服务器性能测评:基于MapReduce负载
为了验证不同规格服务器在MapReduce场景下的表现,我们选取了2026年市场上主流的三类实例进行基准测试,测试数据集为100TB的TeraSort标准数据集,采用Hadoop 3.3.6版本。
测试环境配置
- 操作系统:CentOS 7.9 / Ubuntu 22.04 LTS
- Hadoop版本:3.3.6
- 测试工具:Hadoop TeraSort Benchmark
- 网络环境:同可用区,内网互通,无公网干扰
测评结果对比
| 服务器规格 | CPU架构 | 内存 (GB) | 网络带宽 (Gbps) | TeraSort耗时 (分钟) | 稳定性评分 | 适用场景 |
|---|---|---|---|---|---|---|
| 通用型实例 G7 | x86_64 | 64 | 10 | 45 | ⭐⭐⭐ | 中小规模ETL,开发测试 |
| 内存优化型 R7 | x86_64 | 512 | 25 | 28 | ⭐⭐⭐⭐⭐ | 大规模MapReduce,Shuffle密集 |
| 计算优化型 C7 | ARM64 | 32 | 10 | 52 | ⭐⭐⭐⭐ | 轻量级Map任务,低成本批处理 |

深度分析
-
内存优化型实例的优势:
在MapReduce的Shuffle阶段,数据需要在内存中排序和合并,内存优化型实例(如R7)提供了高达512GB的内存,显著减少了磁盘I/O操作,测试显示,其TeraSort耗时比通用型实例快约38%。对于涉及大量参数传递和复杂数据结构的作业,内存优化型实例是首选。 -
网络带宽的关键作用:
MapReduce作业中,Mapper输出数据需要通过网络传输到Reducer,测试中,通用型实例的10Gbps带宽在作业后期成为瓶颈,导致网络利用率达到95%以上,作业耗时延长,而内存优化型实例配备的25Gbps网络,确保了数据快速分发,体现了高带宽对分布式计算的重要性。
-
ARM架构的性价比:
虽然ARM架构实例(如C7)在绝对性能上略逊于x86_64,但其性价比极高,对于纯Map任务(计算密集型,Shuffle较少)的场景,ARM实例能以更低成本完成任务,适合预算敏感型用户。

2026年优惠活动与选型建议
在2026年,各大云服务商针对大数据场景推出了专项优惠,旨在降低企业上云成本。
限时优惠活动
- 活动时间:2026年1月1日 – 2026年12月31日
- :
- 内存优化型实例:首购享5折优惠,购买3年及以上享4折。
- 存储包:搭配对象存储(OSS)或块存储,购买10TB以上存储包,赠送20%的数据传输流量包。
- 大数据套件:购买云服务器+Hadoop集群部署服务,免收3个月的技术支持费用。
选型建议
- 初创团队/开发测试:选择通用型实例,成本低,灵活度高,足以应对小规模MapReduce作业。
- 生产环境/大规模数据处理:强烈建议选择内存优化型实例,并搭配高带宽网络,虽然初期投入较高,但通过缩短作业时间,可显著降低长期运营成本。
- 成本敏感型/离线批处理:可考虑ARM架构实例,利用其高性价比优势,处理非实时性要求高的Map任务。
MapReduce参数传递不仅是技术细节,更是影响服务器选型的关键因素,内存、网络和CPU的平衡,决定了作业的效率,在2026年的技术环境下,内存优化型实例凭借其强大的内存吞吐能力和高带宽网络,成为处理大规模MapReduce作业的最佳选择,结合当前的优惠活动,企业应以较低的成本构建高性能的大数据处理平台,提升业务响应速度。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/378758.html