多模态AI与大模型AI并非对立关系,而是“感知与认知”的互补共生,前者解决“看懂世界”的问题,后者解决“理解与生成”的问题,两者结合才是通往通用人工智能(AGI)的完整路径。
很多人容易把这两个概念混为一谈,觉得都是AI,有什么区别呢?你可以把大模型AI想象成一个博学多才但只有“大脑”的学者,而多模态AI则是这位学者戴上了眼睛、耳朵和手,拥有了感知物理世界的能力。
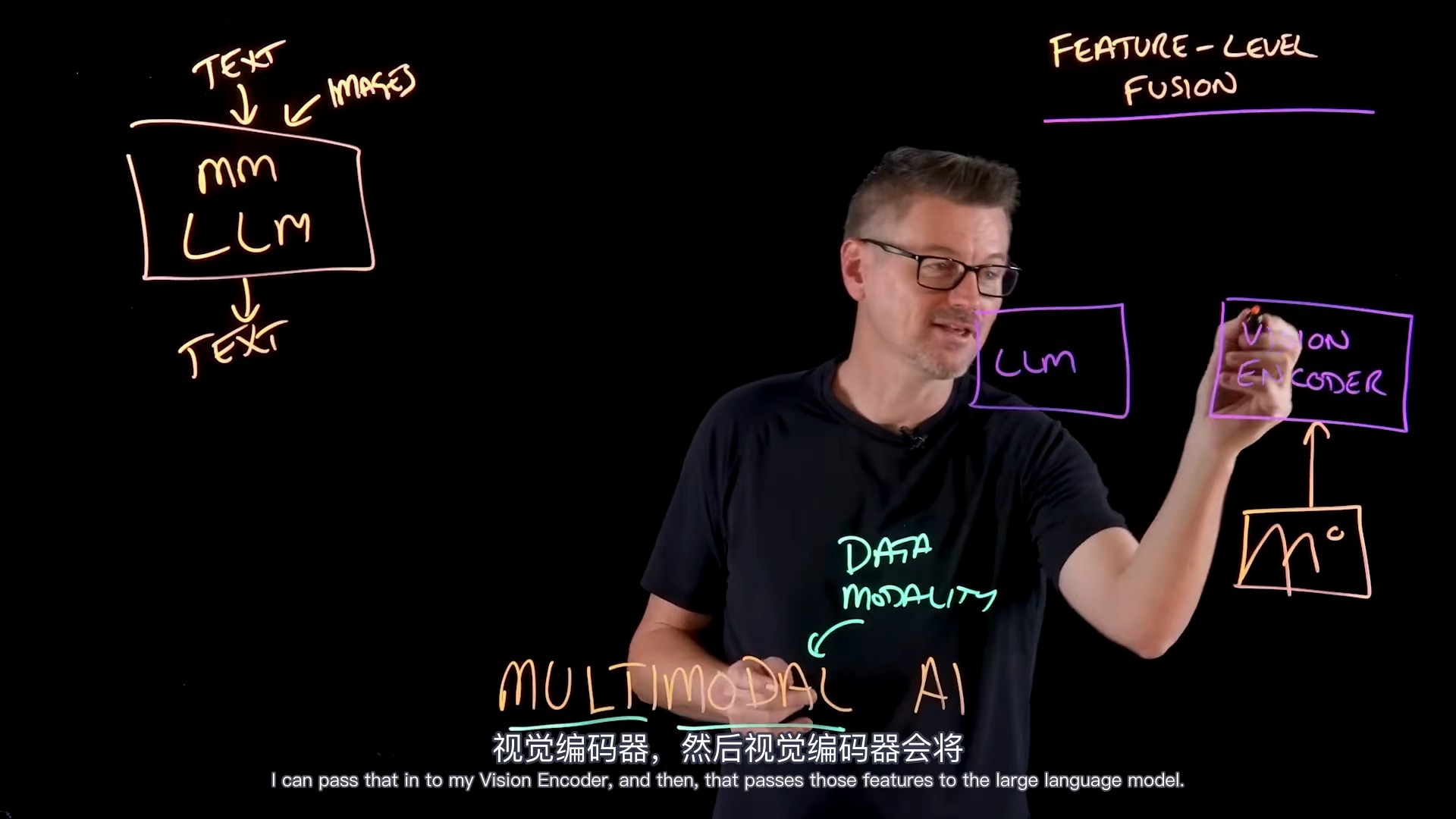
多模态AI与大模型AI的核心差异解析
要理解这两者的区别,我们不能只看技术名词,得看它们在实际工作流中扮演什么角色。
大模型AI:纯粹的逻辑与语言中枢
大语言模型(LLM)的核心优势在于对文本、代码等符号数据的极致处理,它像一个读过图书馆所有书籍的顾问,能写出完美的文案,也能调试复杂的代码。
- 输入限制:主要依赖文本输入,虽然部分早期版本支持简单图片识别,但本质是将图像转化为文本描述后再处理,缺乏对像素级细节的深度理解。
- 输出形式:主要是文字、代码或结构化数据。
- 核心能力:逻辑推理、知识检索、自然语言生成。
业内专家指出,大模型在纯文本任务上的准确率已经接近人类专家水平,但在面对非结构化数据时,往往需要额外的预处理步骤。
多模态AI:全感官的交互体验
多模态AI(Multimodal AI)打破了单一数据的壁垒,它不仅能“读”文字,还能“看”图片、“听”声音、“看”视频。
- 输入多样性:支持文本、图像、音频、视频、3D模型等多种数据格式同时输入。
- 输出多样性:可以生成符合语境的图片、视频片段、语音回复甚至交互式应用。
- 核心能力:跨模态理解、内容生成、实时交互。
举个例子,当你给多模态AI一张餐厅照片并问“这里适合约会吗?”,它不仅能识别出照片中的烛光、桌布和背景音乐(如果视频有声),还能结合氛围感给出建议,而传统大模型可能只能告诉你“这是一张室内照片”。
场景化应用对比:谁更胜一筹?
在不同的业务场景下,两者的价值权重完全不同,选择哪种技术,取决于你的具体需求。
创作领域

在自媒体和视频制作中,多模态AI的优势显而易见。
- 图文生成:输入一段脚本,多模态模型直接生成对应的分镜画面和配音,效率提升数倍。
- 视频剪辑:通过自然语言指令(如“把这段视频剪得更有节奏感”),AI自动调整剪辑点。
相比之下,大模型更适合撰写脚本大纲、SEO文章优化或生成营销文案。
客户服务与交互
智能客服中的多模态大模型应用
传统的智能客服只能处理文字问答,遇到复杂问题容易死循环,多模态大模型则能实现“所见即所得”的服务。
- 故障排查:用户上传设备损坏的照片,AI直接识别故障点并提供维修指南。
- 情感分析:通过用户的语音语调判断情绪,调整回复策略,从“机械回答”变为“共情沟通”。
据统计,多数情况下,引入多模态交互后,客户满意度提升了较大比例,因为沟通路径更短、更直观。
教育与医疗专业领域
- 教育:学生上传一道几何题的照片,AI不仅给出答案,还能通过语音讲解解题思路,甚至画出辅助线动画。
- 医疗:医生上传X光片,AI辅助识别病灶,并结合病历文本生成初步诊断报告,供医生复核。
这里需要明确,AI只是辅助工具,最终决策权仍在人类专家手中。
技术融合趋势:从“单点突破”到“全面进化”
2026年的技术现状显示,纯粹的“文本大模型”或“图像生成器”正在消失,取而代之的是“多模态大模型”(Multimodal Large Language Models, MLLMs)。
多模态大模型的技术架构优势
现在的头部模型大多采用统一的编码器,将文本、图像、音频映射到同一个向量空间,这意味着模型真正实现了“理解”而非简单的“拼接”。
- 统一表征:文字和图片在数学空间中被视为同一类信息,模型能理解“苹果”这个词和苹果图片之间的深层关联。
- 指令跟随:用户可以用自然语言混合指令,如“把这张图里的红色换成蓝色,并写一首关于蓝色的诗”。
性能提升的具体表现

- 推理能力增强:多模态输入为模型提供了更多上下文线索,显著降低了幻觉率。
- 泛化能力提高:模型能将在一个模态学到的知识迁移到另一个模态,通过阅读大量描述,模型能更好地理解从未见过的艺术风格图片。
落地成本与选择建议
对于企业和个人开发者来说,如何选择合适的方案是关键。
多模态AI与大模型AI价格对比分析
| 维度 | 纯大模型API | 多模态大模型API | 本地部署多模态模型 |
|---|---|---|---|
| 计算资源 | 低(CPU/低端GPU即可) | 中(需中高端GPU) | 高(需多卡集群) |
| 单次调用成本 | 极低 | 中等 | 固定硬件投入高 |
| 响应速度 | 快(毫秒级) | 较慢(秒级) | 取决于硬件配置 |
| 适用场景 | 文本处理、代码生成 | 图像理解、视频生成、复杂交互 | 数据隐私要求极高的场景 |
- 初创团队:建议优先使用云端多模态大模型API,无需维护基础设施,按量付费,灵活应对业务波动。
- 大型企业:若涉及敏感数据(如医疗、金融),需考虑私有化部署,近年来,开源多模态模型(如Llama系列的多模态版本)性能大幅提升,降低了部署门槛。
实操建议:如何快速集成多模态能力?
- 选择模型:根据任务类型选择,若侧重理解,选视觉编码器强的模型;若侧重生成,选扩散模型或生成式模型。
- 数据预处理:确保输入数据的格式标准化,对于视频,需提取关键帧或音频波形;对于图片,需进行分辨率归一化。
- 提示词工程:针对多模态优化Prompt,明确指定“请重点分析图片中的文字内容”或“忽略背景噪音,聚焦人声”。
- 迭代优化:建立反馈机制,收集用户纠错数据,微调模型以提高特定场景的准确率。

无缝交互的终极形态
随着算力的提升和算法的优化,多模态AI与大模型AI的界限将进一步模糊,未来的AI将不再区分“文本”或“图像”,而是直接处理“信息”。
- 实时交互:延迟将降低到人类感知阈值以下,实现真正的实时视频通话辅助、实时翻译和实时创作。
- 具身智能:多模态AI将驱动机器人,使其能在物理世界中自主导航、操作物体,实现从“数字世界”到“物理世界”的跨越。
据工信部数据显示,我国在人工智能多模态领域的专利申请量位居全球前列,产业链日益完善,这意味着,无论是开发者还是普通用户,都能更容易地享受到多模态AI带来的红利。
常见问题解答
多模态AI与大模型AI在技术实现上有何本质不同?
大模型AI主要基于Transformer架构处理序列数据,核心是预测下一个token的概率分布,多模态AI则引入了额外的编码器(如ViT处理图像,Whisper处理音频),将不同模态的数据映射到共享的语义空间,再通过统一的解码器生成输出,简言之,大模型是“语言专家”,多模态AI是“全科医生”。
多模态AI是否完全取代了传统大模型?
不会,在纯文本处理、代码生成、逻辑推理等场景中,传统大模型依然具有极高的性价比和速度优势,多模态AI更多是扩展了大模型的能力边界,两者是互补关系,对于只需要文本处理的任务,使用纯大模型更经济高效。
企业部署多模态AI面临的最大挑战是什么?
主要挑战在于算力成本和数据隐私,多模态模型参数量巨大,推理成本高,且对GPU资源依赖性强,图像、视频等数据往往包含敏感信息,如何在保证数据安全的前提下进行模型训练和推理,是企业需要重点解决的问题,边缘计算和模型量化技术正在逐步缓解这一难题。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/385652.html





评论列表(1条)
笑死,只有我懂吗?就像那个博学大脑的学者,看着温柔其实根本不懂我的心,说到我心坎里了,为什么男生都这样😭