attrjquery _ 并非原生 jQuery 方法,而是开发者在自定义插件或特定框架封装中常见的命名约定,主要用于处理 DOM 元素的自定义属性读写,其核心逻辑是调用 jQuery 的 .attr() 或 .data() 方法并配合下划线命名规范来实现数据隔离。
在 Web 前端开发的实际场景中,很多初学者甚至中级工程师都会遇到类似 $('#id').attrjquery_() 这样的代码片段,这往往不是 jQuery 官方库自带的标准 API,而是一个被广泛使用的自定义封装或者特定 UI 框架(如某些基于 jQuery 的后台管理系统模板)内部的私有方法,理解这一概念的关键,在于厘清 jQuery 原生属性操作与自定义属性扩展之间的边界。
attrjquery _ 的技术本质与常见应用场景
为什么会出现这种命名方式
业内专家指出,这种带有下划线后缀或特殊前缀的方法名,通常源于开发者为了避免与 jQuery 核心方法冲突而采取的命名隔离策略,在早期的 jQuery 生态中,attr 方法主要用于获取或设置 HTML 标准属性,如 id、class、src 等,随着单页应用(SPA)和复杂交互界面的兴起,开发者需要一种方式来存储非 HTML 属性的数据,比如用户的临时状态、表单验证标记等。
直接使用 attr 存储这些数据虽然可行,但会导致 DOM 节点变得臃肿,且不利于后续的数据清理,一种常见的做法是创建一个名为 attrjquery_ 或类似名称的包装函数,这个函数内部通常会做两件事:一是判断目标元素是否已存在该自定义属性;二是如果不存在,则通过 jQuery 的 .data() 方法将数据绑定到元素对象上,而不是直接写入 HTML 标签。
典型业务场景解析
在后台管理系统开发中,这种模式尤为常见,在一个复杂的表格组件中,每一行数据可能包含大量的元数据,如“是否已审核”、“最后修改人 ID”、“关联订单号”等,如果将这些信息全部放在 HTML 的 data- 属性中,页面体积会显著增加,且不利于 SEO 和首屏渲染速度。
使用 attrjquery_ 这样的封装方法,可以实现以下优势:
- 数据隔离:将业务数据与展示数据分离,保持 HTML 结构的简洁。
- 性能优化:利用 jQuery 内部的缓存机制,避免频繁的 DOM 读写操作。
- 易于维护:统一的命名规范让代码更具可读性,后续开发者能快速识别哪些数据是用于业务逻辑而非页面展示的。

原生 jQuery 操作与自定义封装的对比分析
为了更清晰地理解 attrjquery _ 的作用,我们需要将其与 jQuery 原生的属性操作方法进行对比,很多开发者容易混淆 .attr()、.prop() 和 .data() 的区别,而自定义封装往往是对这些原生方法的进一步抽象。
核心差异对比
| 操作方式 | 作用对象 | 数据持久性 | 适用场景 | 性能表现 |
|---|---|---|---|---|
| .attr() | HTML 属性 | 持久,直接写入 DOM | 获取或设置标准 HTML 属性 | 中等,涉及 DOM 操作 |
| .prop() | DOM 对象属性 | 持久,内存中 | 获取布尔值属性(如 checked, selected) | 较高,直接访问对象属性 |
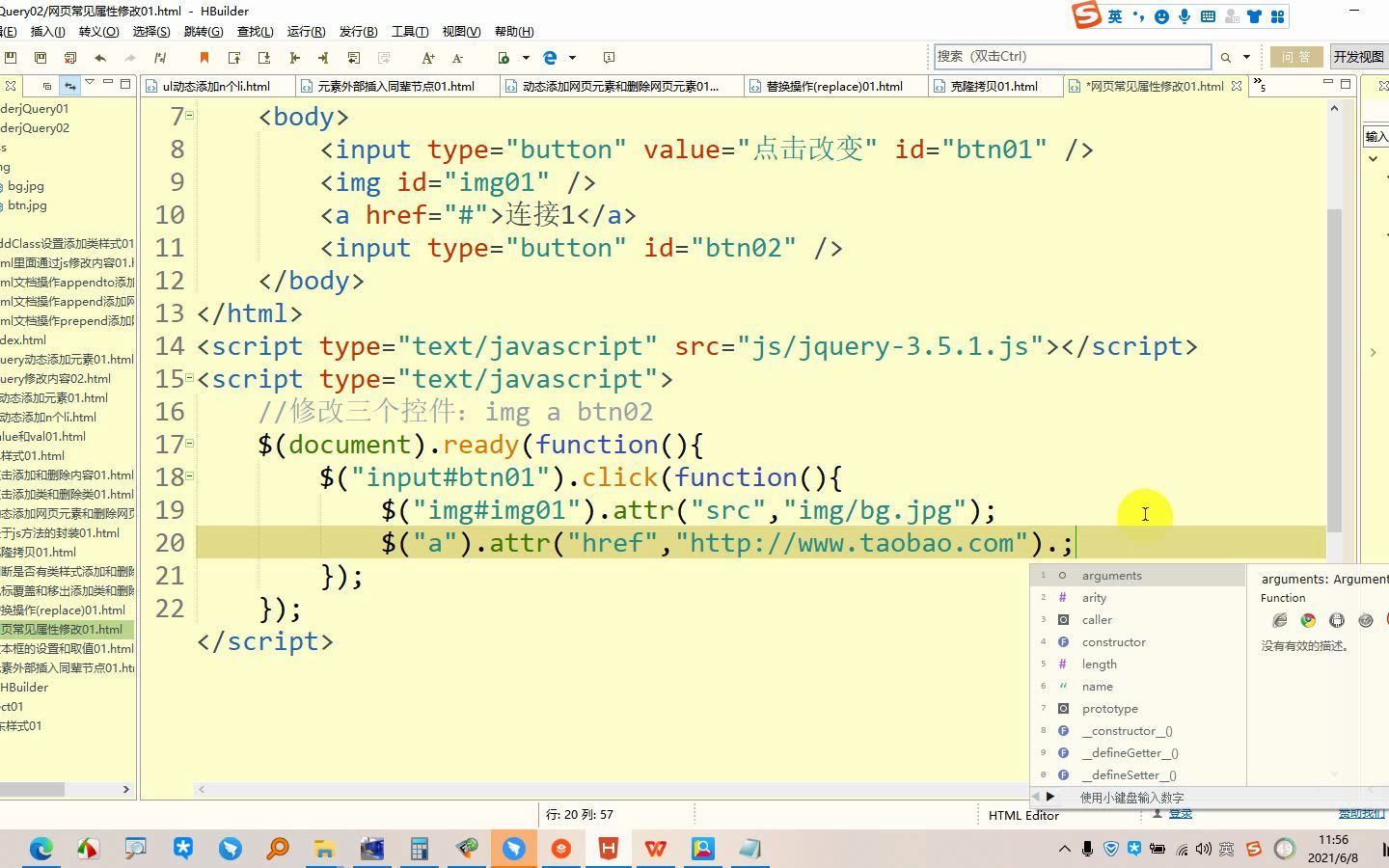
| .data() | jQuery 内部缓存 | 非持久,随元素移除而清除 | 存储非 HTML 相关的业务数据 | 最高,无 DOM 操作 |
| attrjquery_ | 自定义封装 | 取决于内部实现 | 复杂业务状态管理 | 取决于实现,通常优化过 |
从表中可以看出,attrjquery _ 的设计初衷往往是为了弥补原生方法在复杂场景下的不足,当需要存储大量结构化数据时,直接使用 .attr() 会导致 HTML 标签过长,难以阅读;而使用 .data() 虽然性能更好,但缺乏对数据格式的校验和默认值处理,自定义封装通常会结合两者的优点,既提供类似

.data() 的性能,又提供类似 .attr() 的可见性(可选)。
如何实现类似的自定义封装
如果你正在开发一个基于 jQuery 的项目,并希望实现类似 attrjquery _ 的功能,可以参考以下代码结构,这种实现方式能够确保数据的安全性和一致性。
jQuery.fn.extend({
attrjquery_: function(key, value) {
// 获取模式
if (value === undefined) {
// 尝试从 jQuery 缓存中获取
var data = this.data(key);
if (data !== undefined) {
return data;
}
// 回退到 HTML 属性
return this.attr(key);
}
// 设置模式
else {
// 优先写入 jQuery 缓存,避免污染 DOM
this.data(key, value);
// 可选:同步写入 HTML 属性,以便调试工具可见
// this.attr(key, JSON.stringify(value));
return this;
}
}
});
在上述代码中,我们利用了 jQuery 的 extend 方法扩展了原型链,这种写法不仅保持了链式调用的特性,还通过 data 和 attr 的协同工作,实现了数据的灵活管理,对于需要频繁读写状态的前端组件来说,这种封装能显著减少代码量并提高执行效率。
2026年前端开发趋势下的最佳实践建议
随着前端技术的演进,虽然原生 JavaScript 和现代框架(如 React、Vue)逐渐占据主导地位,但在维护遗留系统或开发轻量级插件时,jQuery 依然有着广泛的应用,对于 attrjquery _ 这类自定义方法,以下几点建议有助于提升代码质量。
避免过度封装
并非所有场景都需要自定义封装,如果仅仅是为了存储一个简单的字符串或数字,直接使用 .data() 即可,过度封装会增加代码的复杂度,导致后续维护成本上升,只有当业务逻辑涉及复杂的状态管理、数据校验或跨组件通信时,才建议引入类似 attrjquery _ 的抽象层。
注重数据序列化与反序列化
在使用自定义方法存储对象或数组时,务必注意数据的序列化问题,jQuery 的 .data() 方法会自动处理简单类型,但对于复杂对象,建议手动进行 JSON 序列化,以确保数据在不同会话或页面刷新后的完整性。
// 存储对象 $('#element').attrjquery_('userData', JSON.stringify({ name: 'Alice', age: 25 })); // 读取对象 var userData = JSON.parse($('#element').attrjquery_('userData'));

这种处理方式虽然略显繁琐,但能有效避免数据类型转换错误,特别是在处理跨域数据或本地存储时尤为重要。
结合现代构建工具进行优化
在现代前端工程化体系中,即使使用 jQuery,也建议结合 Webpack 或 Vite 等构建工具进行代码分割和压缩,对于 attrjquery _ 这样的自定义方法,可以通过 Tree Shaking 机制剔除未使用的代码,从而减小最终打包体积,使用 TypeScript 或 JSDoc 对自定义方法进行类型定义,能显著提升开发体验,减少运行时错误。
常见问题解答
attrjquery _ 方法在 jQuery 3.x 版本中是否兼容?
jQuery 3.x 版本完全支持自定义方法的扩展,attrjquery _ 这类自定义封装在 3.x 版本中是可以正常运行的,但需要注意的是,jQuery 3.x 移除了一些废弃的 API,如 .size() 和 .andSelf(),如果你的自定义封装依赖这些方法,需要进行相应的调整,jQuery 3.x 对 .data() 的行为进行了优化,更加严格地遵循 HTML5 data- 属性规范,因此在存储复杂数据时,建议显式使用 JSON 序列化。
如何判断项目中是否使用了 attrjquery _ 这种自定义方法?
可以通过浏览器开发者工具的 Console 面板进行快速检测,选中一个 DOM 元素,然后在 Console 中输入 jQuery.fn.attrjquery_ 或 $.fn.attrjquery_,如果返回一个函数定义,则说明项目中存在该自定义方法,也可以通过全局搜索项目源码,查找 attrjquery_ 字符串,通常能在插件文件或工具库中找到其定义。
使用 attrjquery _ 相比直接使用 data- 属性有什么优势?
使用 attrjquery _ 的主要优势在于数据管理的灵活性和性能,直接操作 data- 属性会直接修改 DOM 结构,可能导致页面重绘和回流,影响性能,而 attrjquery _ 通常会将数据存储在 jQuery 的内部缓存中,避免了频繁的 DOM 操作,自定义方法可以提供默认值、数据校验和事件触发等功能,使得数据管理更加智能化,对于需要高性能交互的复杂应用来说,这种封装能显著提升用户体验。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/385989.html