关于bp神经网络算法的公式
在深度学习与人工智能的浩瀚领域中,反向传播(Back Propagation, BP)神经网络算法无疑是基石般的存在,它不仅是理解多层感知机(MLP)训练机制的关键,更是现代深度学习框架底层逻辑的核心体现,对于服务器测评而言,深入解析BP算法的数学本质,有助于我们更精准地评估硬件在处理复杂梯度计算时的性能表现,本文将从算法原理、核心公式推导、计算复杂度分析以及服务器硬件选型建议四个维度,进行深度剖析。
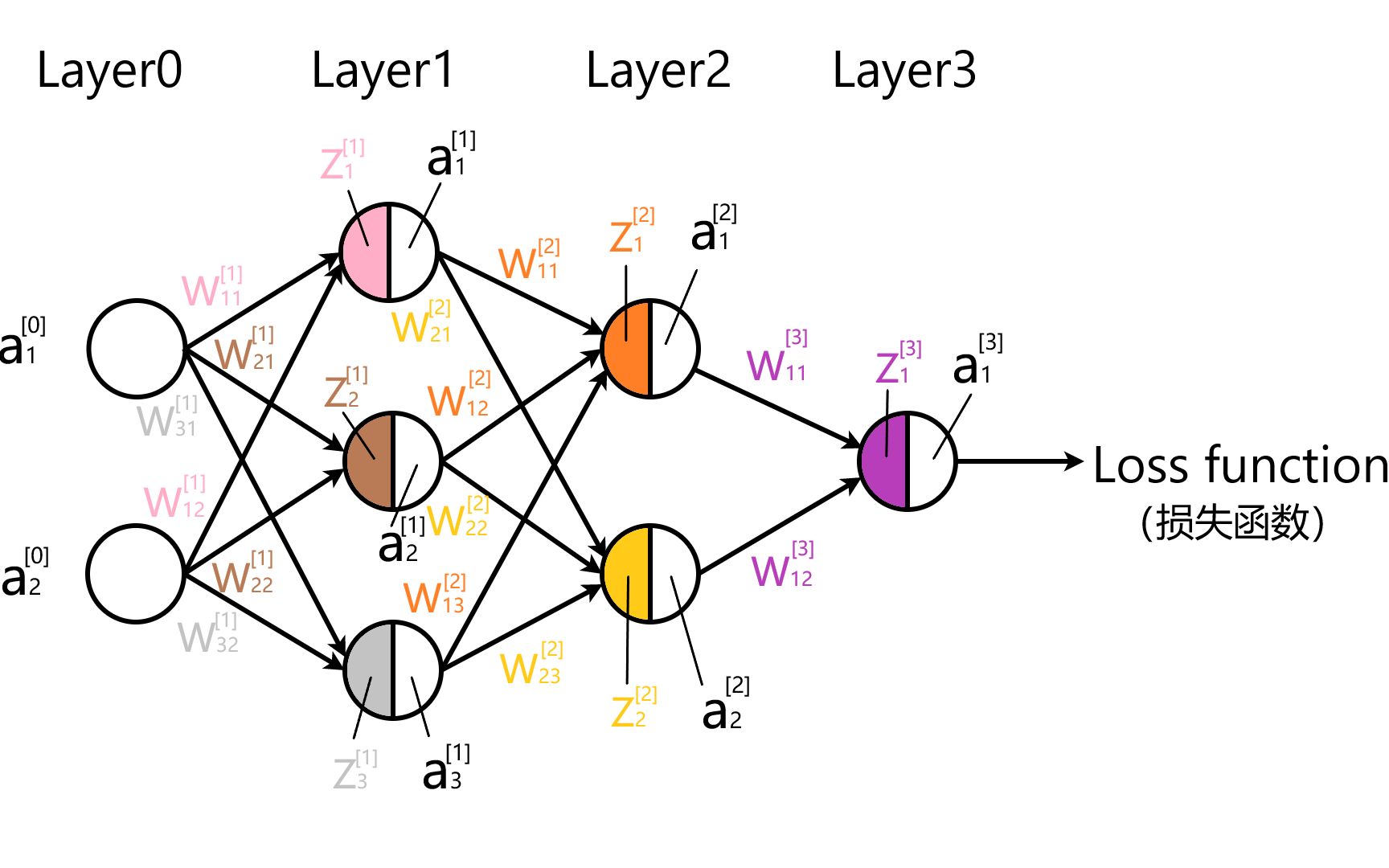
BP神经网络的核心架构与数据流向
BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,其核心思想在于:网络学习过程由信号的正向传播与误差的反向传播两个过程组成。
- 正向传播:输入数据从输入层经隐层逐层处理,并传向输出层,若输出层的实际输出与期望输出不符,则转入误差反向传播阶段。
- 反向传播:将输出误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,作为修正各单元权值的依据。
这种机制使得网络能够通过不断调整权重和偏置,最小化损失函数,从而实现从数据中学习特征映射的能力。
核心公式深度解析
BP算法的精髓在于链式法则(Chain Rule)的应用,为了清晰展示,我们定义以下符号:
- $l$:层数索引,$l=1$ 为输入层,$l=L$ 为输出层。
- $n$:节点索引。
- $w_{ij}^{(l)}$:第 $l$ 层第 $j$ 个节点与第 $l-1$ 层第 $i$ 个节点之间的连接权重。
- $b_j^{(l)}$:第 $l$ 层第 $j$ 个节点的偏置。
- $z_j^{(l)}$:第 $l$ 层第 $j$ 个节点的加权输入总和。
- $a_j^{(l)}$:第 $l$ 层第 $j$ 个节点的激活输出。
- $sigma(cdot)$:激活函数,通常使用Sigmoid、Tanh或ReLU。
- $C$:损失函数(Cost Function),常用均方误差(MSE)或交叉熵(Cross-Entropy)。
前向传播公式
对于任意层 $l$ 和节点 $j$,其加权输入 $z$ 和激活输出 $a$ 计算如下:

$$ zj^{(l)} = sum{i} w_{ij}^{(l)} a_i^{(l-1)} + b_j^{(l)} $$
$$ a_j^{(l)} = sigma(z_j^{(l)}) $$
$a_i^{(l-1)}$ 是上一层的激活值,这一过程在服务器端表现为大量的矩阵乘法与向量加法运算,对CPU的浮点运算单元(FPU)或GPU的张量核心(Tensor Cores)压力极大。
误差反向传播公式
反向传播的目标是计算损失函数 $C$ 对每个权重 $w$ 和偏置 $b$ 的偏导数,即梯度 $frac{partial C}{partial w}$ 和 $frac{partial C}{partial b}$。
首先定义第 $l$ 层第 $j$ 个节点的误差项(Error Term)$delta_j^{(l)}$:
$$ delta_j^{(l)} = frac{partial C}{partial z_j^{(l)}} $$
输出层误差计算:
对于输出层 $L$,若使用均方误差损失 $C = frac{1}{2}sum_k (a_k^{(L)} – y_k)^2$,则:
$$ delta_j^{(L)} = (a_j^{(L)} – y_j) sigma'(z_j^{(L)}) $$
隐藏层误差递归计算:
对于任意隐藏层 $l$,其误差项依赖于下一层 $l+1$ 的误差项:
$$ delta_j^{(l)} = left( sumk w{jk}^{(l+1)} delta_k^{(l+1)} right) sigma'(z_j^{(l)}) $$
这里体现了链式法则的核心:当前层的误差是由下一层加权后的误差乘以当前层激活函数的导数得到的。
梯度计算与权重更新
一旦获得误差项 $delta$,即可计算梯度:
$$ frac{partial C}{partial w_{ij}^{(l)}} = a_i^{(l-1)} delta_j^{(l)} $$
$$ frac{partial C}{partial b_j^{(l)}} = delta_j^{(l)} $$
使用梯度下降法(Gradient Descent)及其变体(如Adam、SGD)更新参数:
$$ w{ij}^{(l)} leftarrow w{ij}^{(l)} – eta frac{partial C}{partial w_{ij}^{(l)}} $$
$$ b_j^{(l)} leftarrow b_j^{(l)} – eta frac{partial C}{partial b_j^{(l)}} $$
$eta$ 为学习率。
计算复杂度与服务器性能关联分析
理解公式背后的计算负载,是选择合适服务器配置的前提,BP算法的训练过程涉及海量的矩阵运算。
| 计算阶段 | 主要运算类型 | 内存带宽需求 | 计算密集型特征 | 推荐硬件加速方案 |
|---|---|---|---|---|
| 前向传播 | 矩阵乘法 (GEMM) | 高 | 极高 | GPU (CUDA Core), TPU |
| 反向传播 | 矩阵乘法 + 逐元素乘法 | 极高 | 极高 | GPU (CUDA Core), TPU |
| 权重更新 | 向量加法/标量乘法 | 中 | 低 | CPU (AVX-512), GPU |

- 内存带宽瓶颈:在深层网络中,激活值 $a$ 和权重 $w$ 需要在内存和计算单元之间频繁搬运,如果服务器内存带宽不足,GPU将处于等待数据状态,导致算力浪费。
- 并行化优势:BP算法中的矩阵运算具有天然的并行性,计算一个批次(Batch)中所有样本的梯度可以同时在不同核心上执行。多核CPU或高性能GPU是提升训练速度的关键。
- 精度需求:虽然公式中涉及浮点运算,但在实际部署中,混合精度训练(FP16/BF16 + FP32)已成为趋势,服务器若支持Tensor Core等混合精度加速技术,可显著提升BP算法的执行效率。
服务器选型建议与2026年优惠活动
基于BP算法的计算特性,我们为您推荐以下服务器配置方案,并特别推出2026年度专属优惠。
推荐配置方案
- 入门级/小规模实验:
- CPU:Intel Xeon Gold 或 AMD EPYC 7002系列(高主频,支持AVX-512)
- 内存:64GB DDR4 ECC
- 适用场景:小型神经网络调试,数据量小于10GB。
-

专业级/中型训练
:- GPU:NVIDIA A100 或 H100 (80GB)
- CPU:AMD EPYC 9004系列
- 内存:256GB DDR5
- 适用场景:深度学习模型训练,支持大规模Batch Size,加速BP反向传播。
- 企业级/大规模集群:
- GPU:多卡互联(NVLink)
- 网络:InfiniBand 高速互联
- 适用场景:超大规模语言模型(LLM)预训练,极致优化梯度同步效率。

2026年专属优惠活动详情
为了助力开发者与企业在2026年更高效地进行AI研发,我们特别推出“智算未来”计划:
- 活动时间:2026年1月1日 至 2026年12月31日
- :
- 新用户专享:购买任意GPU服务器实例,首年享受 7折优惠。
- 长期合约:签约3年及以上合约,额外赠送 20% 存储容量 及 免费数据迁移服务。
- BP算法加速包:预装优化版深度学习框架(PyTorch/TensorFlow),并附带针对BP算法优化的CUDA内核库,提升训练速度最高达 30%。
- 申请方式:
- 访问官网注册账户。
- 在控制台选择“2026智算未来”活动专区。
- 领取优惠券并选择相应服务器规格。
BP神经网络算法虽看似基础,但其背后的矩阵运算与梯度传播机制决定了人工智能系统的性能上限,在2026年,随着模型规模的指数级增长,选择具备高内存带宽、强并行计算能力的服务器,不仅是提升BP算法训练效率的关键,更是企业构建核心竞争力的一环,通过合理利用上述配置建议及2026年专属优惠,您可以以更低的成本、更高的效率,驾驭深度学习的浪潮。
基于当前主流深度学习理论及硬件架构分析,具体性能表现可能因数据集大小、模型结构及网络环境而异,建议在实际部署前进行小规模基准测试(Benchmark)。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/388013.html











