AI大模型造假并非技术缺陷,而是数据污染、算法偏见与恶意攻击共同作用的结果,目前通过引入多方验证机制、强化数据清洗流程及部署对抗性检测工具,可以有效遏制这一风险。
随着生成式人工智能在2026年的全面普及,内容生产的门槛被极度降低,但随之而来的信任危机也达到了前所未有的高度,当文字、图像甚至视频都能由算法瞬间生成时,辨别真伪成为了用户和企业的核心痛点,这种“造假”现象不再局限于简单的文字拼凑,而是演变成了深伪技术(Deepfake)、逻辑幻觉以及数据投毒等复杂形态,理解其背后的运作逻辑,并掌握相应的防御手段,是当下数字生态中不可或缺的一环。
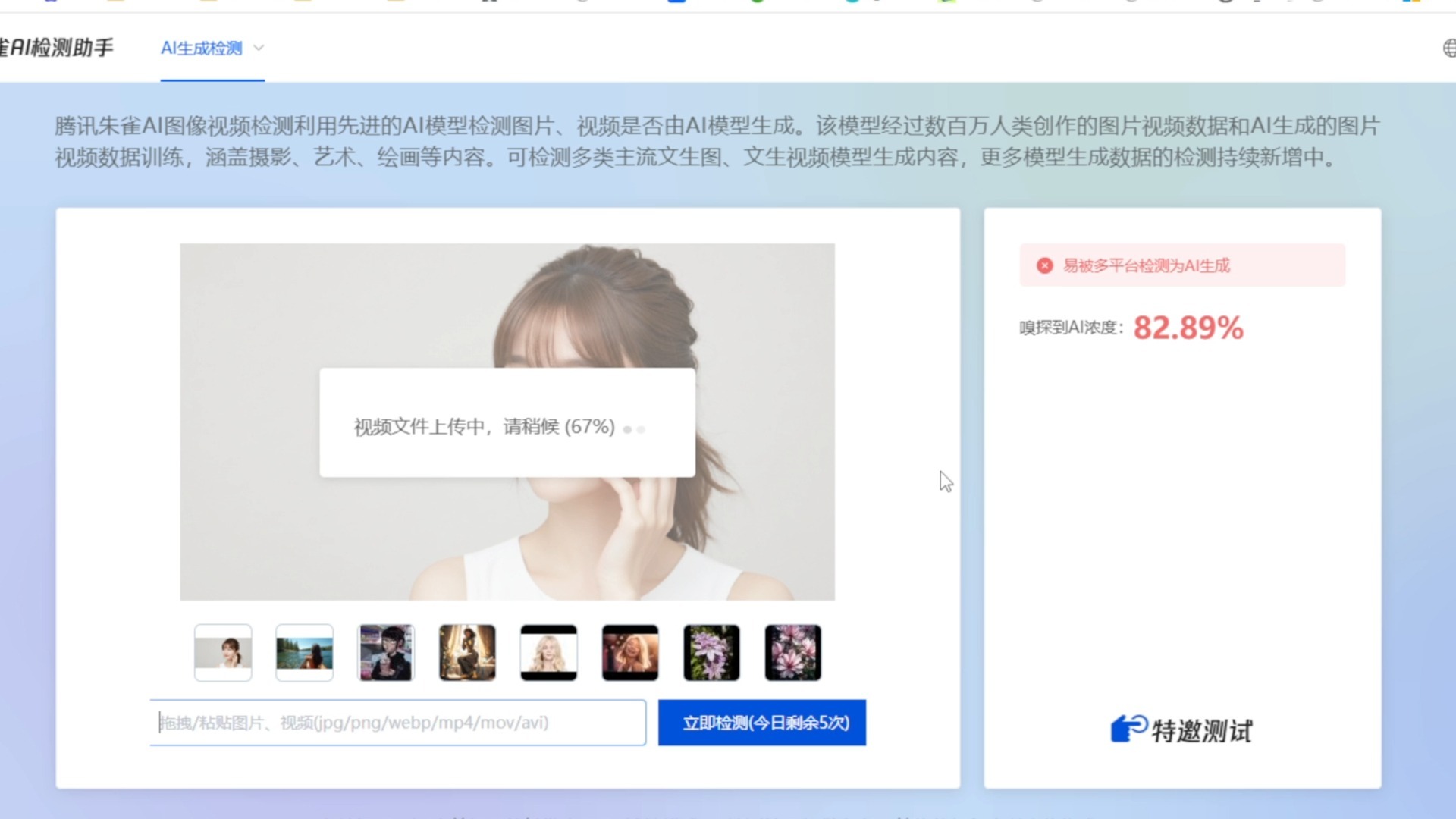
AI造假的三大核心成因解析
要解决造假问题,首先必须厘清其产生的根源,业内专家指出,AI生成内容的不可靠性主要源于训练数据的局限性、模型推理的随机性以及外部环境的恶意干扰。
训练数据中的隐性偏见与污染
大模型的智力上限取决于其训练数据的质量,如果数据集中存在大量虚假信息、偏见观点或经过人工篡改的内容,模型就会将这些“毒素”内化为自己的知识体系。
- 数据源头复杂:互联网上的信息良莠不齐,未经严格过滤的数据被摄入模型后,会形成错误的认知关联。
- 历史偏见固化:模型在学习过程中,会无意识地放大训练数据中存在的性别、种族或地域偏见,导致生成内容带有隐性歧视。
- 反馈循环效应:社交媒体上大量由AI生成的同质化内容被重新用于训练下一代模型,导致错误信息呈指数级扩散,形成“回声室”效应。
模型幻觉与逻辑断裂
所谓的“幻觉”,是指模型自信地生成看似合理但完全虚构的事实,这并非模型故意撒谎,而是其基于概率预测下一个词的本质决定的。
- 概率而非事实:大模型本质上是统计工具,它关注的是词语搭配的合理性,而非客观真理,当缺乏确切数据支持时,它会“脑补”出看似通顺的答案。
- 上下文理解偏差:在处理长篇幅或复杂逻辑任务时,模型容易丢失关键约束条件,导致前后矛盾或逻辑跳跃。
- 过度拟合风险:如果模型在特定领域数据上过度拟合,它在面对新场景时可能会强行套用旧模式,产生荒谬的结论。

恶意攻击与对抗性样本
除了技术本身的局限,人为的恶意干预也是导致AI造假频发的重要原因,攻击者通过精心设计的提示词或输入数据,诱导模型输出有害或虚假信息。
- 提示词注入:攻击者通过隐藏指令绕过安全限制,让模型生成违规内容或泄露敏感信息。
- 数据投毒:在模型训练阶段植入恶意样本,使模型在特定触发条件下输出预设的错误信息。
- 深度伪造滥用:利用AI生成逼真的虚假视频或音频,用于诈骗、诽谤或制造社会恐慌,这类造假具有极强的迷惑性。
如何识别与防范AI生成内容
面对日益复杂的AI造假手段,用户和企业需要建立多维度的防御体系,这不仅涉及技术手段,更包括流程管理和人员意识提升。
技术层面的检测与验证
市场上已出现多种专门用于检测AI生成内容的工具,但没有任何一种工具能够保证100%的准确率,建议采用组合策略。
- 数字水印技术:越来越多的主流AI平台开始在生成内容中嵌入不可见的数字水印,用户可以通过专用插件检测这些水印,以初步判断内容来源。
- 元数据分析:检查文件的元数据(Metadata),如创建时间、编辑软件版本等,AI生成的文件往往缺乏真实的创作轨迹或元数据信息异常。
- 一致性校验:利用图像分析工具检测像素级的不一致性,例如光影方向错误、纹理重复或边缘模糊等深伪技术常见的破绽。

人工审核与交叉验证
技术手段存在局限,人工审核依然是最后一道防线,建立标准化的审核流程,可以有效降低误判率。
- 多方信源比对:对于关键信息,务必通过至少两个独立且权威的信源进行交叉验证,不要轻信单一来源,尤其是社交媒体上的突发新闻。
- 逻辑漏洞排查:仔细审查内容的逻辑连贯性,AI生成的内容可能在细节上非常逼真,但在宏观逻辑或常识判断上往往存在明显漏洞。
- 专家复核机制:在医疗、法律等专业领域,引入领域专家对AI生成的内容进行复核,确保其符合行业规范和事实标准。
建立企业级AI治理框架
对于企业而言,防范AI造假不仅是技术问题,更是合规与风险管理问题。
- 制定使用规范:明确员工在使用AI工具时的行为准则,禁止将敏感数据输入公共模型,并要求所有AI生成内容必须经过人工审核后方可发布。
- 定期安全审计:定期对内部使用的AI模型进行安全评估,检测是否存在数据泄露风险或生成有害内容的漏洞。
- 员工培训与意识提升:定期开展AI伦理与安全意识培训,提高员工对AI造假的识别能力和防范意识。
未来趋势与行业共识
随着技术的演进,AI造假与反造假的博弈将持续升级,行业共识认为,未来的解决方案将更加注重透明性、可追溯性与多方协作。
可验证的内容溯源
区块链技术有望在内容溯源领域发挥重要作用,通过将内容生成过程中的关键步骤上链,可以构建不可篡改的内容指纹,确保用户能够追溯到内容的真实来源和修改历史。
标准化认证体系
政府和行业协会正在推动建立AI生成内容的标准化认证体系,合规的AI平台可能需要通过第三方认证,并在生成内容中提供明确的标识,以便用户区分真实与生成内容。

人机协作的新范式
未来的工作模式将是人机协作,而非完全替代,人类负责创意、判断和伦理把关,AI负责效率提升和数据处理,在这种模式下,造假风险将被控制在人类可管理的范围内。
法律监管的完善
各国政府正在加快制定针对AI生成内容的法律法规,明确AI生成内容的法律责任归属,打击恶意造假行为,将是维护数字秩序的关键。
常见问题解答
如何判断一篇新闻文章是否由AI生成?
判断新闻文章是否由AI生成,可以从以下几个维度入手,检查文章是否存在明显的逻辑断裂或事实错误,AI常会在细节上出现幻觉,观察语言风格是否过于平铺直叙或缺乏情感色彩,AI生成的文本往往缺乏个性化的表达,利用专业的AI检测工具进行辅助判断,但需注意这些工具的准确率并非百分之百,应结合人工审核综合评估,据工信部数据,目前主流的检测工具在特定领域内的识别率已提升至较高水平,但仍需人工复核。
企业使用AI生成营销内容有哪些合规风险?
企业使用AI生成营销内容面临的主要合规风险包括虚假宣传、侵犯知识产权以及数据隐私泄露,AI可能生成包含虚假数据或夸大功效的内容,违反广告法,AI生成的图像或文本可能无意中侵犯他人的版权,若将用户敏感数据输入公共AI模型,可能导致数据泄露,企业在使用AI时,必须建立严格的内容审核机制,确保生成内容符合法律法规要求,并避免使用敏感数据。
AI造假技术是否会随着模型升级而变得无法识别?
虽然AI造假技术会随模型升级而变得更加逼真,但完全无法识别的情况在短期内难以出现,随着检测技术的同步发展,如更精细的元数据分析、多模态一致性检测以及区块链溯源技术的应用,识别难度虽然增加,但并非不可逾越,关键在于建立动态更新的防御体系,结合技术手段与人工审核,持续对抗不断演进的造假手段。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/390457.html









评论列表(1条)
不过话说回来,数据清洗真能清干净?我上次用某开源模型生成的新闻,连地名都编得挺像,结果一搜发现是十年前老新闻换皮…诶,检