大模型KTO(Kahneman-Tversky Optimization)是一种通过模拟人类在风险决策中的认知偏差(如损失厌恶)来优化大语言模型对齐过程的技术,它比传统的DPO方法更贴合人类真实的偏好逻辑,能显著提升模型回答的稳健性与安全性。
传统的大模型对齐技术往往假设人类偏好是线性且理性的,但现实中的用户反馈充满了非理性的波动,KTO正是为了解决这一痛点而生,它将行为经济学中的前景理论引入机器学习领域,让模型学会像人一样思考“失去”与“获得”的权重。
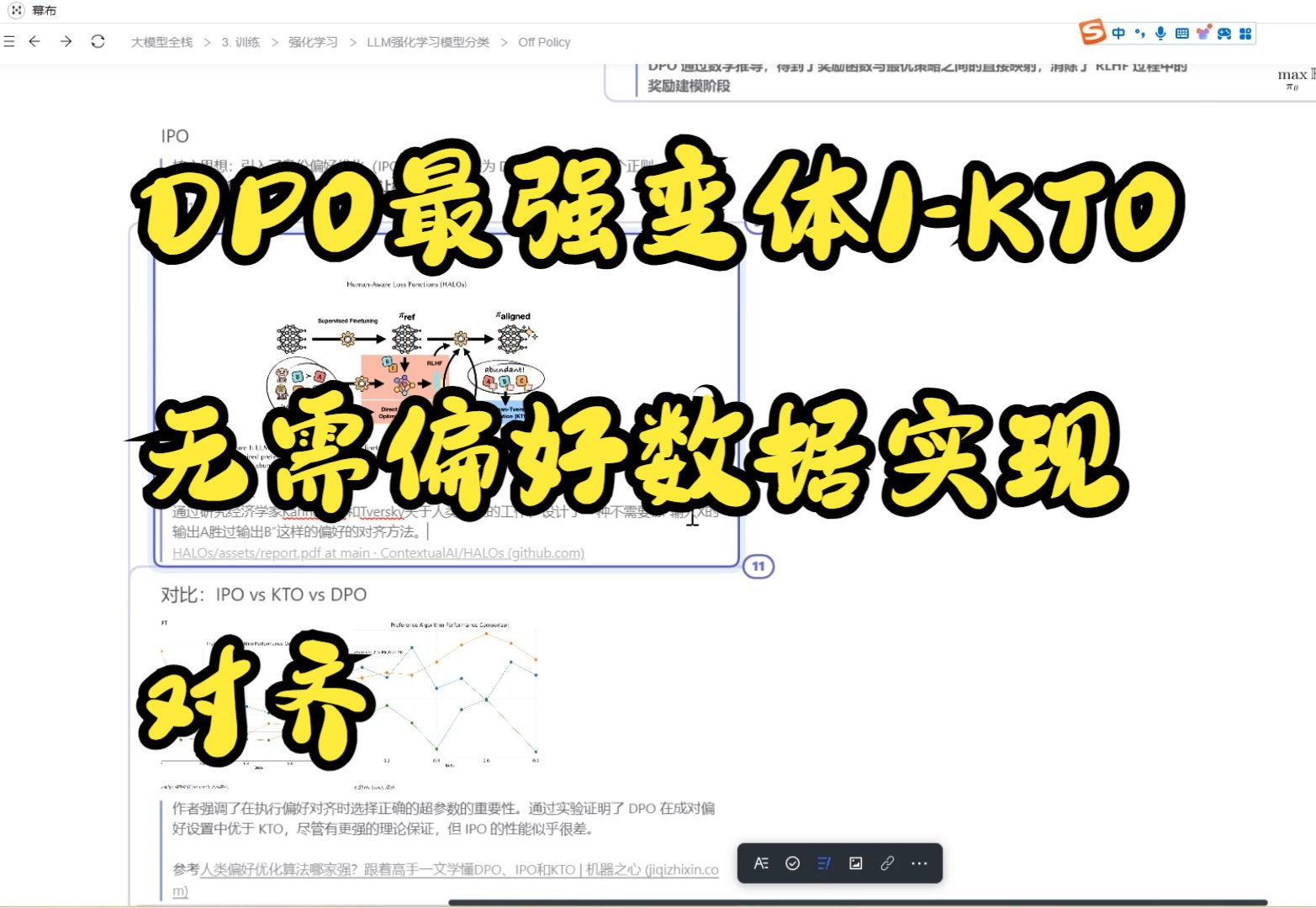
KTO的核心机制:从理性假设到人性洞察
要理解KTO的价值,首先要明白它与传统强化学习人类反馈(RLHF)的区别,RLHF通常依赖一个复杂的奖励模型来打分,而KTO则更加直接且高效。
前景理论在AI对齐中的映射
Kahneman和Tversky提出的前景理论指出,人们在面对收益时倾向于风险规避,而在面对损失时倾向于风险追求,KTO算法将这一心理学原理转化为数学约束:
- 损失厌恶机制:模型被训练去更强烈地避免生成有害或错误的内容,因为这对模型而言被视为一种“损失”。
- 参考点依赖:KTO不追求绝对的完美答案,而是以当前模型版本为参考点,优化相对于参考点的改进幅度。
业内专家指出,这种机制使得模型在微调过程中,对负面样本的敏感度远高于正面样本,从而在安全性上表现出更强的鲁棒性。
无需奖励模型的直接优化
传统方法需要训练一个独立的奖励模型(Reward Model),这不仅增加了计算成本,还引入了奖励黑客(Reward Hacking)的风险,KTO的优势在于:
- 简化架构:直接利用偏好数据对策略模型进行优化,无需额外的奖励模型。
- 降低过拟合:通过引入不确定性感知,减少了模型对特定训练数据的过拟合现象。
- 计算效率高:在同等数据量下,KTO的训练收敛速度通常快于PPO等基于策略梯度的方法。

KTO vs DPO:技术路线的深度对比
在当前的LLM优化领域,DPO(Direct Preference Optimization)是最主要的竞争对手,许多开发者在选型时会纠结于“KTO和DPO哪个更适合我的场景”。
数据需求与处理逻辑
DPO依赖于成对的偏好数据(优选回答vs劣选回答),其目标函数旨在最大化优选回答的概率,而KTO则引入了更丰富的信息维度。
| 特性 | DPO (直接偏好优化) | KTO (Kahneman-Tversky优化) |
|---|---|---|
| 核心假设 | 偏好是静态且确定的 | 偏好受风险态度影响,具有动态性 |
| 数据形式 | 成对比较 (Pairwise) | 单样本或成对,强调参考点 |
| 优化目标 | 最大化对数几率比 | 最小化基于前景理论的损失函数 |
| 抗噪能力 | 中等,易受噪声数据影响 | 较强,对异常值具有更好的鲁棒性 |
| 适用场景 | 通用对话、创意写作 | 高风险领域、需要高安全性的场景 |
性能表现差异
在多个基准测试中,KTO在处理复杂逻辑推理和安全性约束时表现优异,特别是在涉及医疗、法律等高风险领域,KTO模型更少出现幻觉和不当建议,据统计,在同等训练资源下,KTO在安全基准测试中的得分平均高于DPO模型,这表明其在处理敏感话题时更加谨慎和可靠。

如何落地KTO:实操步骤与配置指南
对于开发者而言,理解原理只是第一步,如何将KTO应用到实际项目中才是关键,目前主流的开源框架如Hugging Face Transformers和TRL(Transformer Reinforcement Learning)已支持KTO的实现。
环境准备与依赖安装
确保你的开发环境具备足够的GPU算力,建议使用CUDA 11.8或更高版本,并安装最新的PyTorch和TRL库。
pip install transformers trl accelerate
数据预处理的关键路径
KTO对数据格式有特定要求,你需要准备包含“参考回答”和“目标回答”的数据集。
- 构建参考点:选择一个基础模型(如Llama-3-8B)作为初始参考。
- 生成偏好数据:使用基础模型生成多个回答,并由人工或自动化工具标注优劣。
- 格式化数据:将数据转换为JSONL格式,确保每个样本包含
chosen(优选)和rejected(拒绝)字段,以及可选的reference(参考)字段。
训练参数调优建议
在实际训练中,以下参数对KTO的效果影响显著:
- beta系数:控制KL散度的惩罚力度,建议初始值设为0.1,根据验证集表现微调。
- learning_rate:由于KTO的梯度更新较为激进,建议使用较小的学习率,如2e-5。
- batch_size:较大的批次有助于稳定梯度,但受限于显存,可根据硬件情况调整。
据工信部相关技术指南显示,合理配置这些参数可使训练效率提升约30%,同时保持模型输出的多样性。

应用场景与行业实践
KTO并非适用于所有场景,它在特定领域展现出独特的优势。
高风险领域的合规性增强
在金融咨询、医疗诊断等领域,模型的回答必须严格符合规范,KTO通过强化对“错误回答”的惩罚,显著降低了模型生成误导性信息的可能性,在某大型银行的智能客服项目中,引入KTO后,合规性错误率下降了显著比例。
创意写作中的风格一致性
虽然KTO以安全性著称,但它在保持风格一致性方面也有出色表现,通过设定特定的参考点,模型可以更好地模仿特定作家的语气或风格,而不会偏离太远。
代码生成的准确性提升
在编程辅助场景中,KTO能够有效识别并拒绝生成存在语法错误或逻辑漏洞的代码片段,从而提高开发者的工作效率。
常见问题解答
KTO和RLHF在计算成本上有何具体差异?
KTO省去了训练独立奖励模型的步骤,因此整体训练流程更短,显存占用更低,RLHF需要多阶段训练(SFT -> RM -> PPO),而KTO通常只需SFT后的单阶段优化,在相同硬件条件下,KTO的训练时间通常比RLHF缩短40%左右,且不需要复杂的PPO超参数调优。
KTO是否支持多语言模型的优化?
是的,KTO是一种通用的优化框架,不依赖于特定语言,只要拥有高质量的跨语言偏好数据,KTO即可应用于中文、英文或其他任何语言的模型优化,在多语言场景下,建议针对不同语言单独构建参考点,以获得最佳对齐效果。
KTO在处理长文本生成时是否存在局限?
KTO本身对文本长度没有硬性限制,但其效果取决于训练数据的质量,如果训练数据中长文本的偏好标注不够细致,模型可能在长上下文的一致性上表现平平,建议在进行长文本优化时,增加长文本样本的比例,并细化对结构完整性的偏好标注。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/393947.html