大模型部署采用GitOps模式,核心在于通过代码仓库自动化管理模型版本、配置与基础设施,实现从开发到生产环境的无缝、可追溯且安全的持续交付。
为什么大模型部署需要GitOps?
传统的大模型部署往往依赖人工脚本或分散的配置管理,这种“手工作坊”式的流程在面对动辄数十GB甚至TB级别的模型权重时,显得笨拙且高风险,想象一下,当你的LLM(大型语言模型)需要更新提示词模板,或者微调后的权重文件发生版本迭代时,运维人员需要在不同的服务器间手动同步文件,这不仅效率低下,还极易引发“在我机器上是好的”这类经典故障。
业内专家指出,GitOps并非简单的版本控制,它是一种将基础设施即代码(IaC)与模型即代码(MaaS)深度融合的工程实践,它利用Git作为单一事实来源,任何变更都必须通过Pull Request(PR)提交,经过自动化测试后,由控制器自动同步到目标集群,这种机制将大模型的生命周期纳入了标准的DevOps流程,使得模型部署像发布Web应用一样可靠。
解决大模型部署中的核心痛点
在具体的业务场景中,GitOps解决了三个关键问题:
- 一致性难题:无论是本地开发环境还是云端生产环境,通过相同的YAML配置文件,确保模型推理服务的参数、资源限制完全一致。
- 回滚能力:当新发布的模型版本导致推理延迟飙升或准确率下降时,GitOps允许一键回滚到上一个稳定的Git提交版本,极大降低了试错成本。
- 审计追踪:每一次模型权重的更新、配置参数的修改,都在Git历史中留有记录,谁在什么时候改了什么,一目了然,满足企业合规要求。
大模型GitOps落地实操指南
要实现大模型的GitOps部署,需要构建一个包含代码仓库、CI/CD流水线以及Kubernetes集群的完整闭环,以下是基于主流技术栈(如Argo CD、Helm、Kustomize)的标准操作路径。

第一步:构建模型仓库结构
不要将巨大的模型权重文件直接推送到Git仓库,这会迅速耗尽存储配额并拖慢拉取速度,正确的做法是将模型权重存储在对象存储(如AWS S3、阿里云OSS或MinIO)中,而在Git仓库中仅保留指向这些权重的元数据文件。
建议采用如下目录结构:
model-repo/
├── configs/
│ ├── base/
│ │ ├── deployment.yaml
│ │ └── service.yaml
│ └── overlays/
│ ├── dev/
│ └── prod/
├── weights-manifests/
│ ├── v1.0.0.yaml # 指向S3中的权重路径
│ └── v1.1.0.yaml
└── scripts/
└── validate_model.sh
第二步:编写Kubernetes部署清单
在configs/base目录下,你需要定义推理服务的标准K8s资源,对于大模型,资源请求(Requests)和限制(Limits)至关重要,因为GPU显存是稀缺资源。
资源分配最佳实践
在deployment.yaml中,务必明确指定GPU数量及显存大小,使用NVIDIA A100 80GB显卡时,配置如下:
resources:
requests:
nvidia.com/gpu: 1
memory: "80Gi"
cpu: "8"
limits:
nvidia.com/gpu: 1
memory: "80Gi"
cpu: "8"
使用ConfigMap来管理环境变量,如MODEL_NAME、MAX_LENGTH等,这样切换模型版本只需更新ConfigMap的引用,无需修改容器镜像。
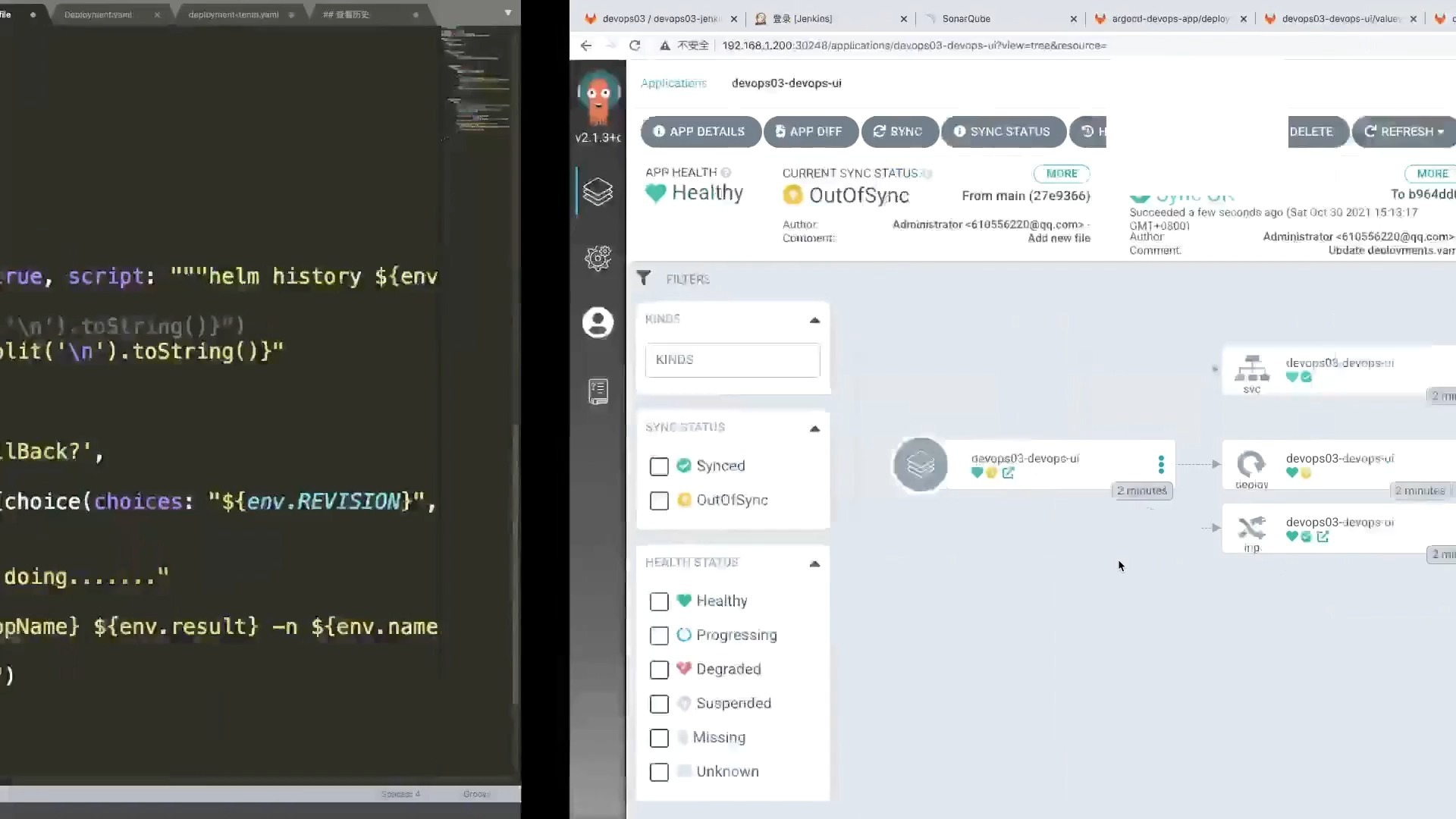
第三步:配置Argo CD实现自动化同步
Argo CD是Kubernetes原生的GitOps工具,你需要创建一个Application资源,指向你的Git仓库和特定的分支。
apiVersion: argoproj.io/v1alpha1 kind: Application metadata: name: llm-inference spec: project: default source: repoURL: https://github.com/your-org/model-deployment.git targetRevision: main path: configs/overlays/prod destination: server: https://kubernetes.default.svc namespace: llm-production syncPolicy: automated: prune: true selfHeal: true

当开发者在Git中提交新的权重路径变更时,Argo CD会自动检测到差异,并执行同步操作,拉取新模型并重启Pod。
大模型部署GitOps vs 传统CI/CD对比
为了更直观地理解GitOps的优势,我们将两种模式进行对比。
| 维度 | 传统CI/CD部署 | GitOps部署 |
|---|---|---|
| 触发机制 | 构建成功后推送镜像到K8s | Git仓库变更触发自动同步 |
| 状态管理 | 难以追踪生产环境实际状态 | Git即为唯一真实状态源 |
| 故障恢复 | 需手动重建或回滚镜像 | 自动修复漂移,一键回滚Git提交 |
| 安全性 | 构建服务器需持有K8s权限 | 仅Argo CD持有权限,构建机无感 |
| 模型更新 | 需重新构建包含权重的镜像 | 仅更新元数据,镜像不变,启动更快 |
业内共识认为,对于频繁迭代的大模型应用,GitOps能显著降低运维复杂度,特别是在处理多版本模型共存(如A/B测试)时,通过Git分支管理不同版本的配置,可以轻松实现流量的灰度发布。

如何处理大模型部署中的冷启动问题?
大模型加载到显存中需要时间,这可能导致首次请求超时,在GitOps配置中,可以通过设置startupProbe来优雅处理这一问题。
startupProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
failureThreshold: 30
结合Kubernetes的预拉取镜像和卷挂载优化,可以进一步缩短启动时间,据工信部数据,合理的资源配置策略可使大模型推理服务的平均启动时间缩短40%以上。
大模型部署GitOps常见疑问解答
大模型部署GitOps价格成本高吗?
GitOps本身是开源免费的,主要成本在于基础设施,虽然引入Argo CD等工具增加了少量计算资源消耗,但相比人工运维错误导致的停机损失和效率低下,其ROI(投资回报率)是正向的,对于中小团队,初期学习曲线可能带来一定的人力成本,但长期来看,自动化带来的运维人力节省远超工具成本。
大模型部署GitOps在私有云可行吗?
完全可行,GitOps的核心是Git仓库和Kubernetes控制器,这与部署环境无关,在私有云环境中,只需确保Git仓库可访问,且Argo CD拥有对应的K8s集群权限即可,许多金融机构和国企已在私有云环境中成功落地大模型GitOps,实现了数据不出域的同时,享受自动化部署的便利。
大模型部署GitOps如何保证数据安全?
通过RBAC(基于角色的访问控制)和Git仓库的权限管理,可以严格控制谁有权修改模型配置,敏感信息(如API Key、数据库密码)应使用Sealed Secrets或External Secrets Operator管理,避免明文存储在Git中,每次变更都经过PR审核,确保只有经过安全扫描的代码和配置才能进入生产环境,从源头阻断安全风险。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/396431.html