大模型在Kubernetes集群中的部署,核心在于通过自定义资源定义(CRD)实现GPU资源的细粒度调度,并配合Prometheus与Grafana构建全链路监控,以确保推理服务的低延迟与高可用。
随着生成式AI从实验室走向生产环境,单纯依靠人工经验管理大模型服务已不再现实,Kubernetes作为容器编排的事实标准,虽然提供了强大的弹性伸缩能力,但面对大模型特有的显存占用高、启动慢、推理延迟敏感等特性,传统的监控方案往往显得力不从心,业内专家指出,构建一套适配大模型特性的监控告警体系,是保障业务连续性的关键。
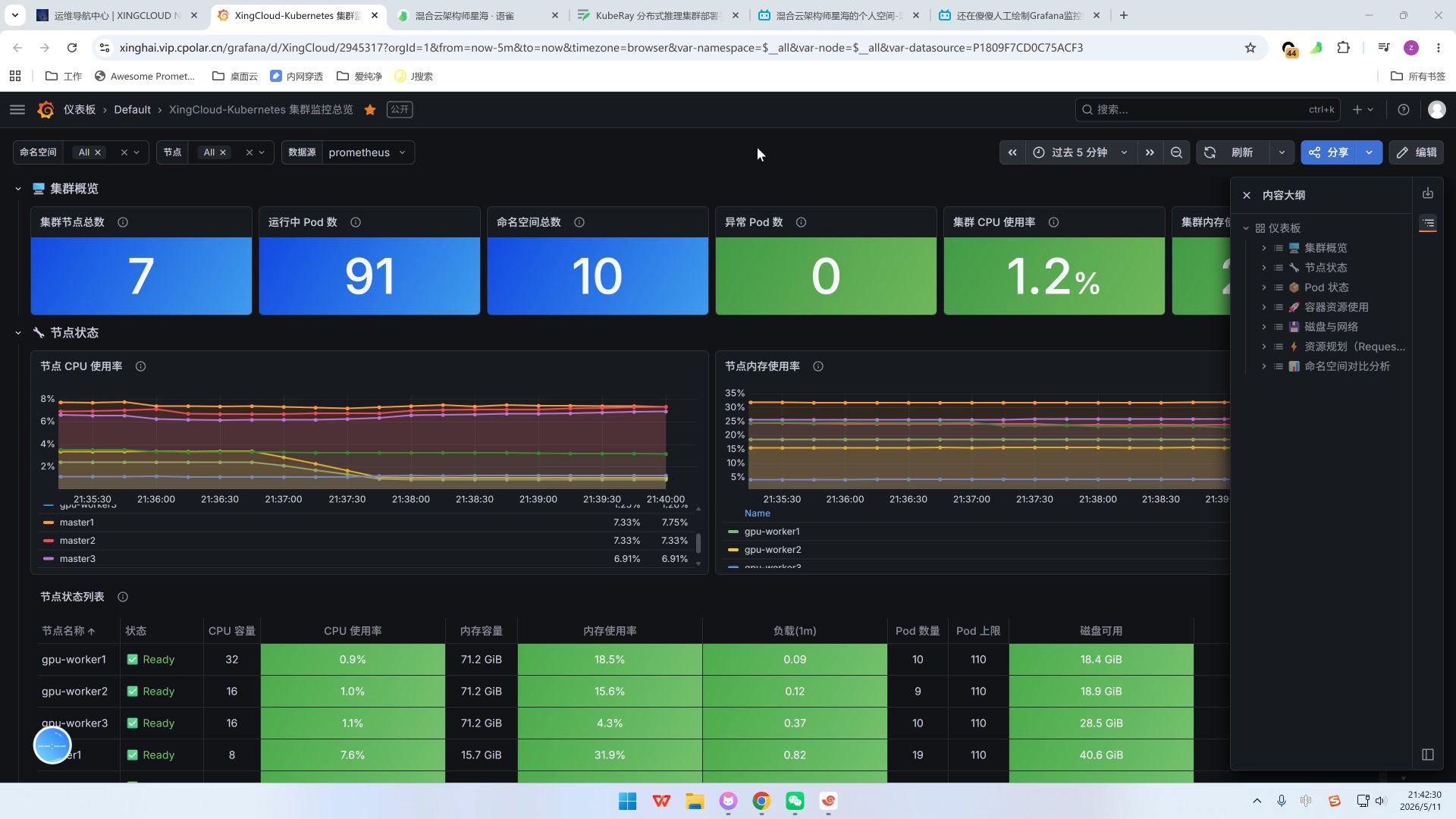
大模型K8s部署监控告警架构设计
在深入具体操作之前,我们需要明确监控的边界,大模型服务通常包含训练、微调、推理三个主要阶段,其中推理阶段对实时性要求最高,也是监控告警的重点。
监控指标体系分层
监控数据不能一概而论,必须根据数据源进行分层采集。
基础设施层监控
这是地基,关注节点的健康状态。
- GPU利用率:不仅看平均利用率,更要看显存(VRAM)占用率,大模型加载时显存会瞬间飙升,需设置动态阈值。
- 节点资源:CPU、内存、磁盘I/O,防止因宿主机资源争抢导致Pod被驱逐。
- 网络带宽:多卡互联(如NVLink)及节点间通信带宽,直接影响分布式推理性能。
服务层监控
这是核心,关注业务逻辑的健康度。
- 请求延迟(Latency):包括首字延迟(TTFT)和端到端延迟,大模型对TTFT极度敏感,这是用户体验的分水岭。
- 吞吐量(TPS/QPS)

:每秒处理请求数,反映系统承载能力。
- 错误率:HTTP 5xx状态码比例,以及模型推理失败(如OOM、超时)的次数。

应用层监控
这是细节,关注模型本身的运行状态。
- Token生成速率:每秒生成的Token数量,衡量推理效率。
- 队列长度:等待推理的请求堆积数量,反映系统是否过载。
Prometheus与Grafana实战配置方案
目前业界主流且成熟的方案是Prometheus采集数据,Grafana可视化展示,这种组合成本低、扩展性强,且社区支持完善。
Exporter选型与部署
要实现上述监控指标,需要部署相应的Exporter。
- Node Exporter:部署在每个K8s节点上,采集宿主机硬件指标,这是基础中的基础,确保你能看到哪台物理机出了问题。
- GPU Exporter:推荐使用NVIDIA DCGM Exporter或kube-prometheus-stack内置的nvidia-device-plugin监控组件,它能深入显卡内部,采集温度、功耗、ECC错误等关键数据。
- 自定义Exporter:对于大模型特有的指标(如TTFT),通常需要在推理服务代码中集成Prometheus客户端库(如Python的prometheus_client),暴露/metrics接口,vLLM或TGI等主流推理框架已原生支持Prometheus指标导出。
告警规则配置策略
告警不是越多越好,噪音过大会导致“告警疲劳”,最终忽略真正的危机。
基于阈值的静态告警
适用于资源水位监控,当节点GPU显存使用率持续5分钟超过90%时,触发P2级告警,通知运维人员介入。
基于SLO的动态告警
适用于服务健康度监控,设定服务等级目标(SLO),如“99%的请求TTFT需低于2秒”,如果过去10分钟内,TTFT超过2秒的请求比例达到1%,则触发P1级紧急告警,这种方式更贴近用户感知,能有效避免误报。

可视化大屏搭建技巧
在Grafana中,建议搭建至少三张核心看板:
- 全局概览屏:展示集群整体健康度、活跃Pod数、总QPS、平均延迟,适合管理层快速掌握状况。
- 模型服务详情屏:按模型名称或版本分组,展示各服务的TPS、TTFT、错误率热力图,适合研发和SRE排查具体模型问题。
- 硬件资源监控屏:展示GPU温度、功耗、显存分布,适合运维团队进行容量规划和故障预防。
常见痛点与优化建议
在实际落地过程中,团队常遇到一些典型问题。
GPU资源碎片化问题
K8s原生调度器对GPU的支持较为粗糙,容易导致显存碎片化,一个需要80GB显存的模型,可能因为节点上剩余显存分散在多个小碎片中而无法调度。
解决方案:启用K8s的GPU共享插件(如NVIDIA MIG或Volcano调度器),或采用基于显存大小的细粒度调度策略,这能显著提升集群资源利用率,降低硬件成本。
冷启动延迟导致的告警误报
大模型加载到显存需要时间,Pod启动初期会出现大量超时请求,如果监控规则未区分“启动中”和“运行中”状态,极易产生大量无效告警。
解决方案:在K8s中配置初始延迟(initialDelaySeconds)和就绪探针(Readiness Probe),只有当模型加载完成并成功响应健康检查后,才将Pod标记为Ready,接入流量监控。
监控数据爆炸与存储成本

高频采集(如每秒1次)会导致Prometheus存储压力巨大。
解决方案:采用分级存储策略,最近7天的数据保留在本地SSD,用于实时告警和排查;7天前的数据归档至对象存储(如S3或OSS),用于长期趋势分析,适当降低非关键指标的采集频率。
大模型K8s部署监控告警常见问题解答
如何在大模型K8s部署监控告警中处理GPU掉卡问题?
GPU掉卡通常表现为节点不可用或Pod频繁重启,建议在Node Exporter中配置GPU温度异常和ECC错误计数告警,一旦检测到硬件级错误,立即触发P0级告警,并自动将该节点上的Pod驱逐,防止错误扩散,结合K8s的自动恢复机制,确保业务在其他健康节点上快速重建。
大模型K8s部署监控告警中TTFT过高如何定位?
TTFT(首字延迟)过高通常由排队等待或模型加载慢引起,首先检查Grafana中的请求队列长度,若队列长,说明并发过高,需考虑水平扩容(HPA),若队列短但TTFT高,检查GPU利用率,若利用率低但延迟高,可能是模型权重加载瓶颈或网络IO瓶颈,此时需查看具体Pod的日志,确认是否有频繁的上下文切换或磁盘读取缓慢。
大模型K8s部署监控告警系统选型需要考虑哪些因素?
选型需综合考虑团队技术栈、数据规模和预算,若团队熟悉云原生技术,Prometheus+Grafana是首选,因其生态丰富且免费,若追求开箱即用且预算充足,可考虑商业APM工具(如Datadog、New Relic),它们提供更深度的应用层洞察,对于超大规模集群,需关注监控系统的可扩展性,确保在数千节点规模下仍能稳定运行,数据查询延迟不超过秒级。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/397703.html