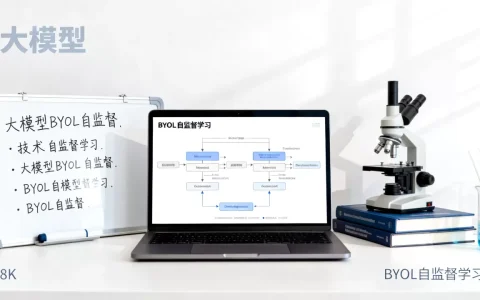
大模型的MAE(Masked Autoencoder)掩码自编码器是一种通过随机遮蔽输入数据的大部分区域,迫使模型仅依据剩余可见部分去重构原始完整数据的预训练方法,其核心在于利用“缺失补全”机制学习数据的深层语义与结构特征。
在传统的自然语言处理或计算机视觉任务中,模型往往需要大量的标注数据才能学会识别规律,而MAE的出现,彻底改变了这一范式,它不再依赖人工标注的标签,而是让模型自己“出题”并“解题”,想象一下,你遮住一本书90%的文字,只留下几个关键词,能否猜出整段故事?MAE做的就是这件事,而且是在高维度的数学空间里,这种机制不仅大幅降低了数据获取成本,还显著提升了模型对未见过数据的泛化能力。

MAE的核心机制:从“全量输入”到“稀疏重构”
MAE的工作原理看似简单,实则蕴含着深刻的数学逻辑,它主要分为编码、遮蔽和解码三个关键步骤,每个步骤都经过精心设计以最大化信息提取效率。
输入数据的随机遮蔽策略
在训练阶段,MAE首先接收原始输入数据,例如一张高清图片或一段长文本,与传统方法不同,MAE不会处理所有像素或所有token,它会随机选取一个高比例的遮蔽率,通常在75%到90%之间,这意味着输入给模型的数据是极度稀疏的。
这种高比例的遮蔽并非随意丢弃信息,而是一种强制性的注意力聚焦机制,通过遮蔽大部分内容,模型被迫放弃对局部细节的依赖,转而关注全局结构和上下文关联,业内专家指出,这种策略能有效防止模型过拟合于表面特征,从而学习到更具鲁棒性的表示。
遮蔽区域的随机性与均匀性
为了确保模型不会通过简单的模式匹配来作弊,遮蔽区域必须是完全随机且均匀分布的,如果遮蔽集中在特定区域,模型可能会利用边缘信息推断中心内容,这违背了学习全局特征的初衷,算法会在输入张量上生成一个二值掩码矩阵,标记哪些部分被保留,哪些部分被替换为特殊的[MASK] token。
编码器的高效特征提取
经过遮蔽后的稀疏数据被送入编码器,这里的关键优化在于,编码器只需要处理那些未被遮蔽的可见部分,由于输入数据量大幅减少,计算复杂度显著降低,在处理图像时,如果遮蔽率为85%,编码器只需处理15%的图像块。

这种设计带来了两个显著优势:
- 计算效率提升:减少了前向传播的计算量,使得训练过程更加轻量化。
- 特征聚焦:模型被迫从有限的可见信息中提取最具代表性的语义特征,而非依赖冗余信息。
解码器的重建任务
编码器的输出并不直接作为最终结果,而是传递给解码器,解码器的任务是根据编码后的特征,重建出原始的完整数据,对于图像,这意味着生成被遮蔽像素的RGB值;对于文本,这意味着预测被遮蔽token的概率分布。
重建过程并非简单的像素级还原,而是语义级的重构,模型需要确保重建出的数据不仅在视觉上或语法上合理,还要在语义上与原始数据一致,这种“由果索因”的训练方式,迫使模型内部建立起对数据结构的深刻理解。
MAE与传统自编码器的本质区别
很多人容易将MAE与传统的自编码器(Autoencoder, AE)混淆,但两者在架构设计和训练目标上存在显著差异,理解这些区别,有助于更好地把握MAE的技术优势。
架构设计的差异
传统自编码器通常包含一个编码器和一个对称的解码器,输入和输出维度一致,且通常不引入遮蔽机制,编码器将输入压缩为低维潜在空间表示,解码器再将其还原,这种结构容易导致信息瓶颈,即低维表示无法承载原始数据的全部细节。
相比之下,MAE采用非对称架构,编码器仅处理可见部分,解码器则负责重建完整数据,这种设计打破了传统自编码器的对称性限制,允许模型在编码阶段进行更灵活的特征抽象,行业共识认为,MAE的非对称设计使其在保留细节和捕捉语义之间取得了更好的平衡。
训练目标的优化
传统自编码器的损失函数通常基于均方误差(MSE)或交叉熵,旨在最小化重建误差,这种优化容易导致模型生成模糊或平滑的输出,缺乏高频细节。
MAE则引入了更精细的重建损失,在图像MAE中,损失函数不仅考虑像素值的差异,还可能引入感知损失或对抗损失,以鼓励生成更逼真的细节,MAE的高遮蔽率使得重建任务更具挑战性,迫使模型学习更本质的特征,而非简单的记忆训练数据。
MAE在实际场景中的应用价值

MAE不仅仅是一个理论模型,它在多个实际应用场景中展现出了巨大的潜力,无论是计算机视觉还是自然语言处理,MAE都提供了新的解决方案。
视觉领域的广泛应用
在计算机视觉任务中,MAE已被证明在图像分类、目标检测和语义分割等下游任务中表现优异,在ImageNet数据集上,基于MAE预训练的模型在分类准确率上超越了多种监督学习基线。
- 数据稀缺场景:在医疗影像分析等领域,标注数据往往稀缺且昂贵,MAE可以通过无监督预训练,从大量未标注的医学图像中提取通用特征,显著提升下游诊断模型的精度。
- 细粒度识别:MAE的高遮蔽率迫使模型关注全局结构,这在识别具有细微差异的物体(如不同品种的鸟类或植物)时尤为有效。
自然语言处理的突破
虽然MAE最初在视觉领域取得突破,但其思想很快被迁移到NLP领域,在文本处理中,MAE通过遮蔽随机token,训练模型预测被遮蔽内容,这种预训练方式在情感分析、文本生成和机器翻译等任务中均取得了显著进展。
- 长文本理解:MAE在处理长文本时,能够有效捕捉全局上下文信息,避免传统注意力机制的计算瓶颈。
- 多语言适配:通过调整遮蔽策略,MAE可以适应不同语言的结构特点,提升多语言模型的通用性。
如何选择合适的MAE模型与参数配置
在实际部署MAE模型时,选择合适的架构和参数配置至关重要,不同的任务和数据集可能需要不同的遮蔽率和模型深度。
遮蔽率的选择
遮蔽率是MAE最重要的超参数之一,较高的遮蔽率(如90%)能迫使模型学习更强的语义表示,但可能导致重建困难,训练不稳定,较低的遮蔽率(如75%)则更容易收敛,但可能无法充分挖掘数据的深层特征。
建议根据任务复杂度进行调整:
- 简单任务:如图像分类,可使用较低遮蔽率,确保模型快速收敛。
- 复杂任务:如细粒度识别或长文本生成,建议使用较高遮蔽率,以获取更丰富的特征表示。
模型规模的权衡
模型规模直接影响性能和计算资源消耗,较大的模型(如ViT-Huge)在复杂任务中表现更佳,但需要更多的GPU内存和训练时间,较小的模型(如ViT-Base)则更适合资源受限的场景。

在资源允许的情况下,优先选择较大规模的预训练模型,并在下游任务中进行微调,若资源有限,可考虑使用知识蒸馏技术,将大模型的知识迁移到小模型中,以平衡性能与效率。
MAE技术的未来趋势与挑战
尽管MAE已取得显著进展,但仍面临一些挑战和未来发展方向。
多模态融合的深化
未来的MAE模型将更多地关注多模态数据的融合,结合文本和图像信息,训练能够同时理解视觉和语义内容的通用模型,这种多模态MAE将在机器人导航、智能助手等领域发挥重要作用。
实时性与效率优化
随着应用场景对实时性要求的提高,MAE模型的推理速度仍需进一步优化,通过模型剪枝、量化和硬件加速等技术,可以显著降低MAE的计算延迟,使其更适合边缘设备和移动端应用。
可解释性的提升
MAE的决策过程仍被视为“黑盒”,未来研究将致力于提升模型的可解释性,通过可视化注意力机制或特征贡献度,帮助用户理解模型是如何进行重建和预测的,这将有助于增强用户对AI系统的信任,特别是在医疗、金融等高风险领域。
关于MAE掩码自编码器的常见问题解答
MAE掩码自编码器与传统BERT模型有何区别?
MAE主要应用于视觉领域,通过遮蔽图像块并重建像素来学习特征;而BERT主要应用于自然语言处理,通过遮蔽文本token并预测其身份来学习语义,尽管两者都采用掩码机制,但MAE的遮蔽比例通常更高,且重建目标更侧重于结构完整性,而BERT更侧重于上下文语义理解。
MAE模型在训练时需要标注数据吗?
不需要,MAE是一种无监督预训练方法,仅依赖原始输入数据即可进行训练,它通过自监督的方式生成伪标签(即重建目标),无需人工标注,这使得MAE能够利用海量未标注数据,显著降低数据获取成本。
MAE模型的推理速度是否比传统模型慢?
在预训练阶段,由于需要重建完整数据,MAE的计算量较大,但在推理阶段,MAE通常只使用编码器部分,且输入数据经过遮蔽处理,计算量反而可能低于处理全量数据的传统模型,在特定场景下,MAE的推理效率可能更具优势。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/405641.html