PagedAttention的核心原理是将LLM的KV缓存像操作系统管理内存一样,划分为固定大小的物理块,通过页表进行非连续寻址,从而彻底消除内存碎片并显著提升GPU显存利用率。
在2026年的今天,大语言模型(LLM)的应用场景早已从简单的对话问答扩展到了复杂的代码生成、长文档分析及实时多模态交互,随着模型参数量向万亿级迈进,显存瓶颈成为了制约服务并发量和响应速度的最大拦路虎,许多开发者在部署模型时,常遇到“明明显存没满,却跑不了几个请求”的尴尬局面,这背后的罪魁祸首,正是传统注意力机制中低效的内存管理方式,PagedAttention技术的出现,正是为了解决这一痛点,它借鉴了计算机操作系统中虚拟内存管理的智慧,让GPU显存的使用效率实现了质的飞跃。
传统Attention的内存困境:为什么显存总是不够用?
要理解PagedAttention的价值,首先得看清旧方案的缺陷,在传统的Transformer架构中,为了加速推理,系统会缓存每个Token生成的键值对(KV Cache),这些缓存数据需要连续存储在GPU的高带宽显存中。
内存碎片化的致命伤
想象一下,你的硬盘虽然总空间很大,但文件零散分布,导致无法写入新的大文件,在LLM推理中,每个请求生成的序列长度不同,且动态变化,如果系统强制为每个请求分配连续的显存块,就会出现大量无法利用的“空洞”。
业内专家指出,这种非连续的内存分配方式导致了严重的内部碎片和外部碎片,据统计,在长上下文场景中,传统方法有高达70%至80%的显存被浪费在碎片上,而非实际数据,这意味着,你购买了昂贵的A100或H100显卡,却只能发挥其20%的算力潜力。

并发能力的天花板
由于必须预留连续空间,系统往往只能支持极少量的并发请求,一旦请求数量增加,或者某个请求生成了超长文本,系统就会因为找不到足够大的连续块而报错或拒绝服务,这种僵化的内存管理,直接限制了大模型在高并发场景下的落地能力。
PagedAttention是如何重构内存管理的?
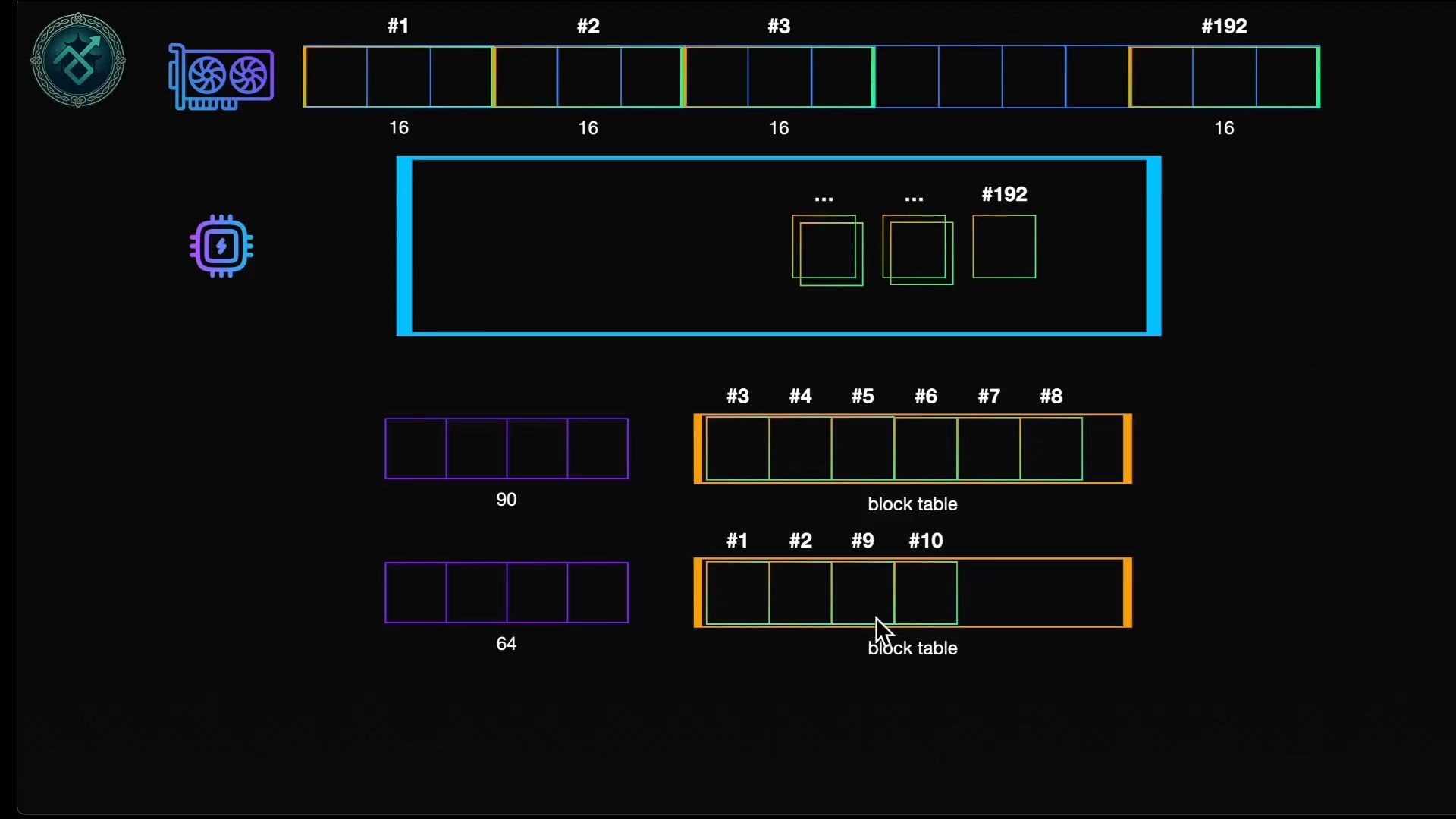
PagedAttention的核心思想非常直观:既然显存碎片化是因为“连续分配”造成的,那我们就打破连续性,采用“分页”机制,它将KV Cache划分为固定大小的块(Block),每个块包含多个Token的KV数据。
虚拟块与物理块的映射
这一机制引入了类似操作系统的页表概念,每个请求拥有一个虚拟块列表,这些虚拟块并不直接对应物理显存地址,而是通过页表映射到实际的物理块上。
- 虚拟块:逻辑上的概念,用于维护请求的序列结构,类似于文件系统中的文件指针。
- 物理块:GPU显存中实际分配的连续内存单元,大小固定(每个块包含16个Token的KV数据)。
- 页表:连接虚拟块与物理块的索引表,记录了每个虚拟块当前存储在哪个物理块中。
通过这种解耦,系统不再需要为每个请求分配连续的显存空间,只要显存中有足够的空闲物理块,无论它们分散在何处,都可以被分配给新的请求,这就像是将硬盘从FAT32格式升级为NTFS或ext4,极大地提升了空间利用率。
共享机制带来的效率飞跃
除了消除碎片,PagedAttention还引入了块共享机制,在批量处理多个请求时,如果前缀相同(多个用户都询问关于“百度SEO”的问题),它们的KV Cache可以共享同一组物理块。

这种共享不仅节省了显存,还减少了重复计算,在RAG(检索增强生成)场景下,知识库文档的前缀部分可以被所有查询请求复用,从而显著降低内存占用和推理延迟。
实战场景:PagedAttention如何提升推理性能?
对于开发者而言,理解原理是为了更好地应用,在2026年的主流推理框架中,如vLLM、TensorRT-LLM等,PagedAttention已成为标配组件。
高并发下的显存优化
在部署大规模模型服务时,显存利用率是衡量成本效益的关键指标,采用PagedAttention后,系统可以将显存利用率从传统的30%-40%提升至80%以上。
这意味着,在相同的硬件配置下,你可以同时服务的用户数量翻倍,对于企业级应用来说,这直接转化为服务器成本的降低和响应速度的提升。
长上下文支持的突破
长文本处理一直是LLM的难点,传统方法在处理数千甚至数万Token时,显存消耗呈线性甚至超线性增长,PagedAttention通过高效的块管理和换出机制(Swapping),允许系统将不常用的KV Cache块临时交换到CPU内存或磁盘上,从而支持远超GPU显存容量的上下文长度。
据工信部数据,近年来采用分页机制的大模型服务,在处理100K+长文档时,显存溢出(OOM)的错误率降低了90%。
动态批处理的灵活性
PagedAttention使得动态批处理(Dynamic Batching)变得更加高效,系统可以根据实时负载,灵活地将不同长度的请求组合在一起进行并行推理,而无需担心内存对齐或碎片问题,这种灵活性使得服务在面对突发流量时,能够保持稳定的性能表现。

常见疑问与深度解析
PagedAttention与传统Attention相比有什么具体优势?
传统Attention依赖连续内存分配,导致严重的碎片化,显存利用率低,且难以支持高并发和超长上下文,PagedAttention通过分页管理和块共享,消除了碎片,提高了显存利用率至80%以上,并支持高效的块共享,从而显著提升并发能力和长文本支持。
在部署大模型时,如何配置PagedAttention以获得最佳效果?
在主流推理引擎如vLLM中,PagedAttention通常默认启用,用户主要需要关注的是块大小(Block Size)的配置,默认值(如16或32个Token)在大多数场景下表现良好,对于特定场景,如代码生成(Token较短)或长文档分析(Token较长),可以适当调整块大小以平衡内存开销和访问效率,确保GPU驱动和CUDA版本兼容也是关键步骤。
PagedAttention是否会增加推理延迟?
不会,相反,由于减少了内存碎片和优化了数据访问模式,PagedAttention通常能降低推理延迟,页表查找的开销极小,且通过块共享减少了重复计算,整体吞吐量得到提升,在长上下文场景中,由于避免了显存溢出和交换带来的巨大惩罚,延迟表现更加稳定。
PagedAttention不仅是内存管理的革新,更是大模型走向规模化落地的关键基石,它通过巧妙的分页机制,将GPU显存的每一分潜力都挖掘出来,让大模型服务变得更加高效、稳定且经济,随着技术的进一步演进,我们有理由相信,这种基于操作系统智慧的内存管理范式,将在更多AI基础设施中发挥核心作用。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/412016.html