大模型的对齐,本质上是让人类价值观、安全规范与模型输出行为保持一致的过程,确保AI不仅“聪明”,听话”且“无害”。
想象一下,你教一只受过高等教育的狗做数学题,如果它算得对,但咬了人,这显然不是我们想要的结果,大模型就像这只狗,它通过海量数据学会了语言逻辑,但原始状态下它没有道德观念,甚至可能输出有害、偏见或违法的内容,对齐技术就是给这只“超级狗”穿上约束衣,并训练它遵循人类的社交礼仪和安全底线。
为什么大模型需要“对齐”?
在2026年的今天,生成式AI已经深入医疗、金融、法律等核心领域,如果模型只是简单地预测下一个字,而不考虑这句话背后的后果,风险是巨大的,业内专家指出,未经对齐的大模型存在三大核心风险:
- 安全性缺失:模型可能被诱导生成制造炸弹、编写病毒代码或传播仇恨言论的内容。
- 价值观偏差:训练数据来自互联网,必然包含性别歧视、种族偏见等社会糟粕,模型会无意识地模仿这些偏见。
- 事实幻觉:模型可能会自信地编造不存在的事实,这在需要高准确性的场景中是致命的。
对齐不仅仅是“加个过滤器”,而是从底层重塑模型的决策逻辑。
从“能说话”到“会说话”的转变
早期的LLM(大语言模型)主要追求“ perplexity ”(困惑度)最小化,也就是尽量准确地预测下一个词,但这导致了“越像人越危险”的局面,对齐技术的引入,标志着AI发展从“能力导向”转向“可控导向”。
我们可以用一个简单的对比来理解:
| 特性 | 预训练模型 (Pre-training) | 对齐后模型 (Aligned) |
|---|---|---|
| 核心目标 | 预测下一个词的概率 | 符合人类意图且安全 |
| 回答风格 | 客观、有时冷漠或带有偏见 | 礼貌、有帮助、遵循伦理 |
| 面对诱导 | 可能照做,如生成恶意代码 | 拒绝回答,或提供安全替代方案 |
| 数据依赖 | 无标签互联网文本 | 少量高质量人类反馈数据 |

这种转变使得大模型从单纯的“信息检索器”进化为“智能助手”。
主流对齐技术解析:RLHF与DPO
目前业界公认的对齐路径主要有两种:基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO),虽然它们的目标一致,但实现路径截然不同。
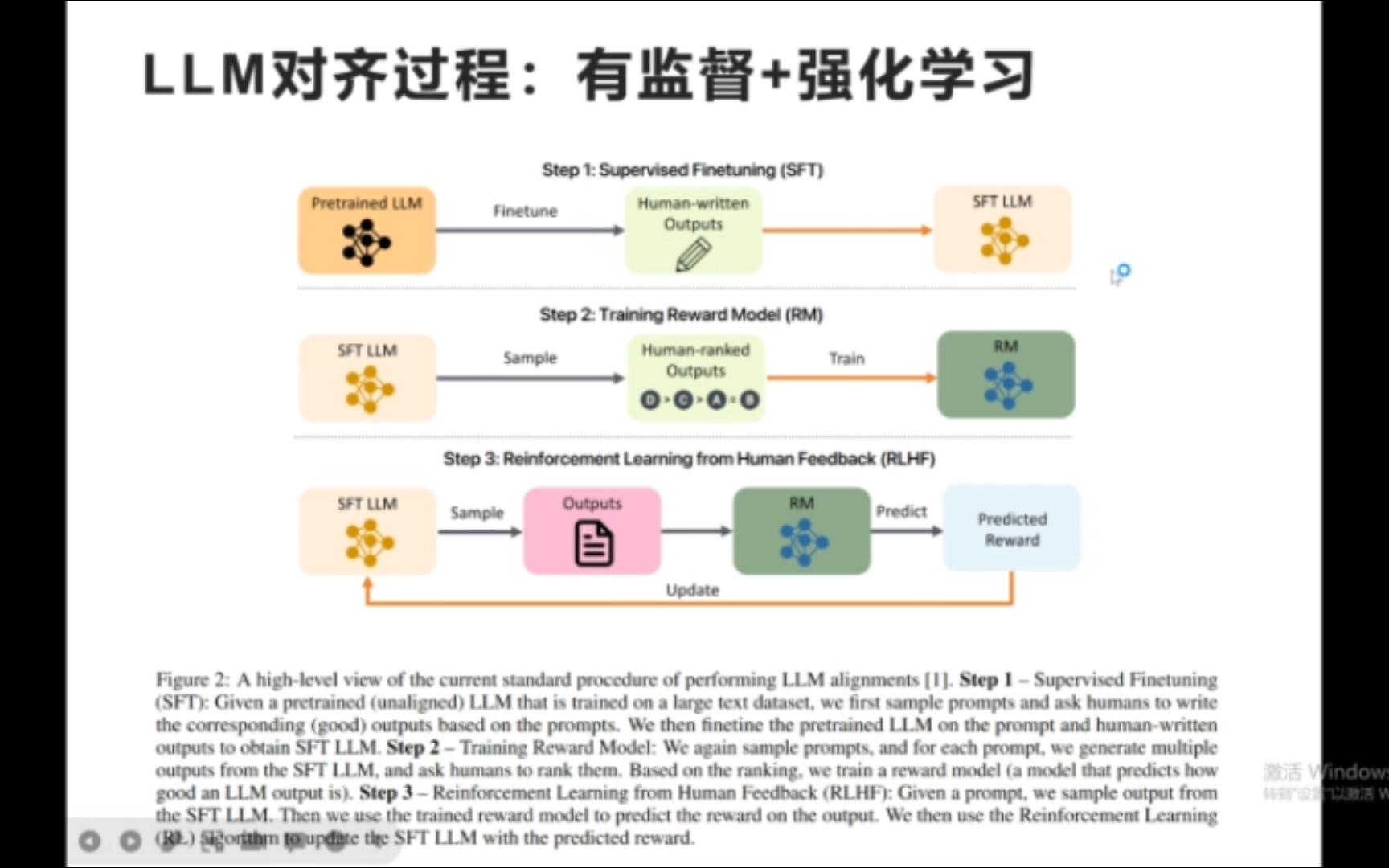
RLHF:三步走的“保姆式”训练
RLHF(Reinforcement Learning from Human Feedback)是目前最主流的对齐方法,它的过程非常繁琐,但效果显著,它分为三个关键步骤:
- 监督微调(SFT):用高质量的人类对话数据对基础模型进行微调,让它学会“像人一样回答”,这一步让模型有了基本的对话能力。
- 奖励模型训练(RM):这是最耗时的一步,人类标注员会对模型生成的多个答案进行排序,答案A比答案B更好”,基于这些排序数据,训练一个独立的“奖励模型”,让它学会给答案打分。
- 强化学习优化:利用奖励模型作为“裁判”,通过强化学习算法(如PPO)不断调整主模型的参数,最大化奖励分数。
这个过程就像教孩子骑自行车,先让他知道姿势(SFT),然后家长在旁边喊“好”或“不好”(RM),最后孩子通过不断摔倒和爬起找到平衡(RL)。
DPO:更高效的“直接优化”
近年来,DPO(Direct Preference Optimization)因其高效性受到青睐,传统RLHF需要训练额外的奖励模型,计算成本高且不稳定,DPO则通过数学变换,将奖励模型隐含在损失函数中,直接优化模型对偏好数据的响应。
据行业共识认为,DPO在同等算力下,能达到与RLHF相近甚至更好的对齐效果,且训练流程更简单,减少了超参数调优的复杂性,对于企业级应用来说,这意味着更低的部署成本和更快的迭代速度。
2026年场景下的对齐挑战与应对
随着AI应用的深入,对齐不再是一个静态的“开关”,而是一个动态的“持续过程”,特别是在垂直领域,通用对齐往往不够用。

垂直领域的特异性对齐
在医疗或法律场景下,通用的“无害”标准可能不够,一个医疗助手不仅要避免提供错误诊断,还要在紧急情况下知道何时建议用户立即就医,而不是继续闲聊。
- 医疗场景:需要引入医学专家的知识图谱,对模型的回答进行事实性校验,当模型输出模糊建议时,必须强制触发“免责声明”或“就医建议”。
- 金融场景:重点在于合规性,模型需要识别潜在的市场操纵言论或非法投资建议,并依据当地法规(如SEC或证监会规定)进行拦截。
多模态对齐的新难题
2026年的大模型大多是多模态的,能处理文本、图像、音频,对齐的难度随之指数级上升。
- 图像偏见:模型生成的图片是否隐含种族或性别刻板印象?生成“CEO”图片时是否默认全是白人男性?这需要引入视觉-语言联合对齐技术。
- 音频情感操控:语音合成模型是否被用于制作深度伪造的诈骗语音?对齐技术需要加入“数字水印”和“情感伦理约束”,防止技术滥用。
如何评估对齐效果?
企业在使用大模型时,如何判断对齐是否到位?通常采用自动化评测与人工审核相结合的方式。
常用评测基准
- SafetyBench:测试模型在面对有害提示时的拒绝率。
- TruthfulQA:评估模型在避免幻觉和保持事实准确性方面的表现。
- HumanEval:虽然主要测代码能力,但也间接反映逻辑一致性。
实操建议:建立内部红队机制
不要完全依赖自动化测试,建议组建内部的“红队”(Red Team),专门尝试通过各种诱导性提问(Prompt Injection)来“攻击”模型。
- 定义攻击向量:列出常见的攻击类型,如角色扮演、越狱提示、逻辑陷阱。
- 自动化扫描:编写脚本批量测试模型对敏感词的响应。
- 人工复核:对自动化测试中的边缘案例进行人工判断,更新安全策略。

这种主动防御机制,比被动等待用户反馈要有效得多。
对齐的未来:从被动合规到主动理解
未来的对齐技术将不再局限于“禁止说什么”,而是转向“理解为什么这么说”。
可解释性对齐
模型不仅要给出答案,还要能解释其推理过程是否符合伦理,在做出贷款审批建议时,模型应能指出:“我拒绝了该申请,因为收入证明存在疑点,而非因为申请人的居住地。”这种透明度有助于建立用户信任。
个性化对齐
不同用户群体可能有不同的价值观偏好,未来的对齐技术可能支持“用户画像定制”,允许企业在合规范围内,根据目标受众的文化背景调整模型的语气和敏感度,但这需要极高的技术门槛,以防止算法歧视。
Q&A:关于大模型对齐的常见疑问
大模型的对齐会影响模型的智力水平吗?
多数情况下,对齐不会显著降低模型的智力,但可能会在极端情况下牺牲一定的创造性,研究表明,经过良好对齐的模型在逻辑推理和事实准确性上往往表现更好,因为它减少了“幻觉”和“胡言乱语”,在某些需要高度发散思维的创意写作任务中,过于严格的对齐可能会让回答显得保守,业内专家指出,关键在于找到“安全”与“灵活”的平衡点,通过精细化的提示词工程而非粗暴的拦截来实现。
中小企业如何低成本实现大模型对齐?
中小企业通常没有资源训练自己的奖励模型,建议采用以下路径:选择已经过良好对齐的开源模型(如Llama系列或Qwen系列)作为基座;利用RAG(检索增强生成)技术,将企业内部的合规文档作为知识库,限制模型的回答范围;在应用层增加一层简单的规则引擎,对敏感关键词进行过滤,这种方式无需重新训练模型,即可满足大部分企业级安全需求。
大模型的对齐标准在全球是否统一?
目前全球尚未形成统一的大模型对齐标准,欧盟的《AI法案》强调高风险应用的透明度与人类监督,美国则更侧重行业自律与创新保护,而中国则强调内容安全与社会主义核心价值观,这种差异导致跨国AI服务需要针对不同地区进行本地化对齐调整,据统计,跨国科技巨头通常维护多套对齐策略,以适应不同司法管辖区的法律要求。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/412710.html