在Access数据库中查询不重复记录,最核心的方法是使用SQL语句中的SELECT DISTINCT关键字,或者在查询设计视图中勾选“唯一值”属性,这能直接过滤掉重复行,返回去重后的结果。
很多初学者在处理Access报表或数据汇总时,经常遇到数据源中存在大量重复项的问题,一个销售记录表中,同一个客户在同一天可能有多条购买明细,如果你直接统计客户数量,结果就会虚高,解决这个问题的关键在于理解Access如何处理“唯一性”判断,以及如何通过不同的操作路径实现数据清洗,下面我们将深入探讨几种主流且高效的去重方案,涵盖从基础界面操作到高级SQL编写的完整流程。
Access查询去重的基础操作路径
对于不熟悉SQL语法的用户来说,Access提供的图形化界面是最直观的选择,这种方法不需要编写代码,通过简单的鼠标点击即可完成去重设置,非常适合处理结构简单的查询需求。
利用查询设计视图的“唯一值”属性
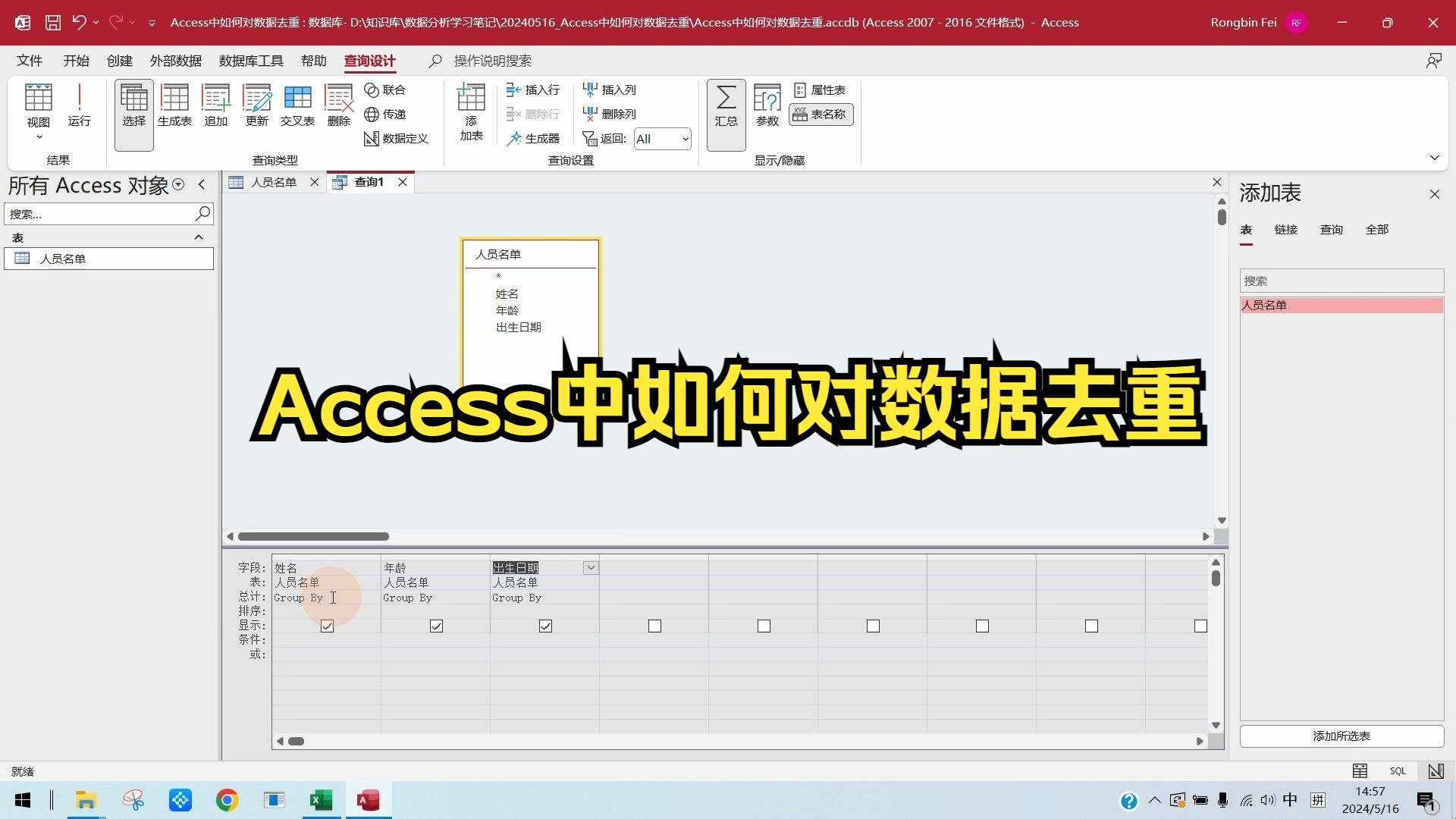
这是最常用且门槛最低的方法,当你打开查询设计视图,将需要的字段添加到网格中后,只需关注工具栏上的一个特定选项。
具体操作步骤如下:
- 打开Access数据库,点击“创建”选项卡下的“查询设计”。
- 添加包含重复数据的数据表或查询对象。
- 将你需要检查重复性的字段拖入下方的字段行。
- 在“设计”选项卡的“结果”组中,找到并点击“唯一值”按钮。
- 字段行下方的“唯一值”单元格会自动变为“是”。
业内专家指出,这种方法的底层逻辑是Access在生成查询结果时,会自动对选定字段进行排序和去重处理,需要注意的是,这种方法仅对当前查询中显示的字段有效,如果你添加了多个字段,Access会基于这些字段的组合来判断唯一性,如果“姓名”和“日期”组合起来是唯一的,即使姓名重复,记录也会保留,务必确保你勾选的字段组合能够准确代表你想要去重的业务实体。
交叉表查询中的去重技巧

在某些复杂的报表场景中,用户可能会尝试使用交叉表查询来汇总数据,交叉表查询本身并不直接提供“去重”选项,它更侧重于数值聚合,在这种情况下,建议先创建一个普通的查询进行去重,再将此查询作为交叉表查询的数据源,这种分层处理的方法虽然增加了步骤,但能确保数据的准确性和逻辑的清晰度。
SQL高级查询:SELECT DISTINCT的应用场景
当数据量较大或去重逻辑复杂时,图形化界面可能显得力不从心,切换到SQL视图并使用SELECT DISTINCT语句是更专业且高效的选择,这种方法不仅执行速度通常更快,而且能更好地处理多表关联时的去重需求。
基本语法与执行逻辑
SELECT DISTINCT的基本语法非常简洁,它紧跟在SELECT关键字之后,其工作原理是数据库引擎在返回结果集之前,会对所有选定的列进行组合比较,移除完全相同的行。
如果你只想获取所有不重复的客户姓名,SQL语句如下:
SELECT DISTINCT CustomerName FROM Orders;
这条语句会遍历Orders表,提取CustomerName列,并丢弃任何之前已经出现过的名字,值得注意的是,DISTINCT作用于其后所有列,如果你希望基于多个字段去重,例如同时考虑“客户姓名”和“所在城市”,语句应写为:
SELECT DISTINCT CustomerName, City FROM Customers;
在这种情况下,只有当姓名和城市的组合完全一致时,记录才会被视为重复,这种灵活性使得SELECT DISTINCT在处理多维数据时具有不可替代的优势。
性能优化与潜在陷阱
尽管SELECT DISTINCT功能强大,但在处理百万级数据时,其性能可能成为瓶颈,因为去重操作通常涉及排序或哈希计算,这会消耗较多的内存和CPU资源。
为了优化性能,建议采取以下措施:
- 避免SELECT 永远不要使用`SELECT DISTINCT `,除非你真的需要所有列的唯一组合,这会导致巨大的计算开销。
- 利用索引:确保用于去重的字段已建立索引,索引可以显著加快排序和比较的速度。
- 限制返回字段:只选择真正需要的字段,减少数据传输量。

据统计,在大型数据库中,不当使用DISTINCT可能导致查询响应时间增加数倍,在编写SQL时,应始终评估数据量级和字段数量,必要时考虑使用子查询或临时表来预处理数据。
去重方案的对比与选择策略
面对不同的业务需求,选择哪种去重方法至关重要,错误的选择可能导致数据错误、性能低下或维护困难。
界面操作 vs SQL语句
| 特性 | 查询设计视图(唯一值) | SQL视图(SELECT DISTINCT) |
|---|---|---|
| 学习曲线 | 低,适合新手 | 中,需掌握基本SQL语法 |
| 灵活性 | 低,仅支持简单去重 | 高,支持复杂逻辑和多表关联 |
| 性能 | 一般,依赖Access引擎优化 | 较好,尤其在使用索引时 |
| 可移植性 | 低,仅限Access环境 | 高,标准SQL可在其他数据库运行 |
多数情况下,对于小型数据集或临时性分析,界面操作足以满足需求,对于生产环境或需要频繁运行的自动化报表,SQL语句是更可靠的选择。
去重与分组汇总的区别
很多用户混淆了“去重”和“分组汇总”,去重旨在返回唯一的记录行,而分组汇总(使用GROUP BY)旨在计算聚合值(如总和、平均值)。

如果你想知道每个客户的总销售额,应使用GROUP BY而非DISTINCT。DISTINCT只会列出客户名字,而GROUP BY能同时列出名字和对应的销售总额,在实际操作中,应根据业务目标明确区分这两种需求,避免逻辑错误。
常见问题与解决方案
Access查询去重不重复字段怎么处理
当需要基于部分字段去重,但显示其他非去重字段时,DISTINCT无法直接实现,可以使用子查询或GROUP BY配合聚合函数,使用MAX()或MIN()函数获取非去重字段的值,从而实现“保留一条完整记录”的效果。
Access查询去重后数据丢失怎么办
如果去重后发现数据量急剧减少,需检查去重字段的选择是否正确,有时,看似相同的字段可能包含不可见的空格或大小写差异,导致Access认为它们不同,建议使用Trim()函数清理数据,或统一大小写后再进行去重操作。
Access查询去重唯一值设置失败原因
唯一值”选项无法勾选或无效,通常是因为查询中包含了计算字段或复杂表达式,Access对这类字段的去重支持有限,建议将计算字段提取到子查询中,或在SQL视图中手动编写去重逻辑。
Access查询不重复的最佳实践总结
在Access中进行数据去重,并非单一技术的应用,而是对数据结构和业务逻辑的综合考量,对于简单场景,利用查询设计视图的“唯一值”属性是最快捷的路径;而对于复杂、高性能要求的场景,熟练掌握SELECT DISTINCT及GROUP BY语句则是必备技能。
业内共识认为,数据清洗是数据分析的前置关键环节,无论采用何种工具,确保去重逻辑与业务定义一致,才是保证数据准确性的根本,通过合理选择去重方法,优化SQL性能,并定期维护数据质量,你可以显著提升Access数据库的使用效率,为后续的数据分析和决策提供坚实可靠的基础,没有最好的方法,只有最适合当前场景的方案。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/447759.html