Hash负载均衡软件通过一致性哈希算法将请求精准路由至特定节点,在保障数据局部性的同时,有效解决了传统轮询模式下的缓存穿透问题,是构建高可用分布式系统的核心组件。
在分布式架构日益复杂的今天,单纯依靠硬件负载均衡或简单的轮询策略已难以满足海量数据场景下的性能需求,Hash负载均衡软件不仅仅是一个流量分发工具,它更像是一个拥有“记忆”的智能调度员,它记住每个数据块应该存放在哪个节点,当用户发起请求时,它会根据数据的哈希值,直接找到对应的“老位置”,而不是盲目地随机分配,这种机制极大地提升了缓存命中率,降低了后端存储的压力。
Hash负载均衡的核心机制与优势解析
理解Hash负载均衡,首先要明白它与传统负载均衡的本质区别,传统方式如轮询(Round Robin)或最少连接数(Least Connections),虽然能实现流量均匀分布,但无法保证同一用户或同一数据的请求落在同一台服务器上,这导致每次请求都可能访问不同的后端节点,使得本地缓存失效,必须去数据库或远程缓存中获取数据,造成严重的性能损耗。
一致性哈希算法的工作原理
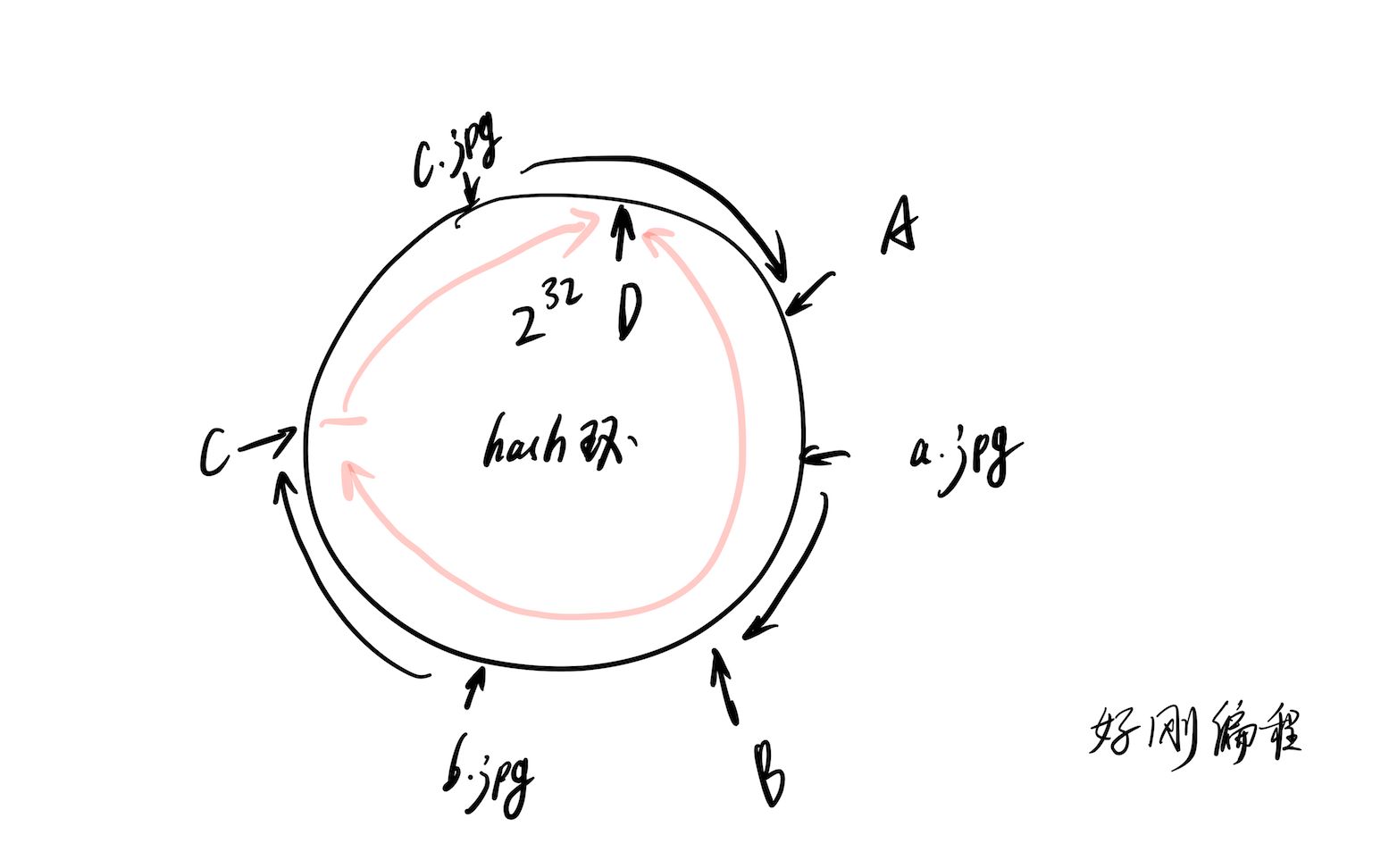
一致性哈希算法是Hash负载均衡的灵魂,它将整个哈希空间组织成一个虚拟的圆环,通常范围是0到2^32-1,所有的服务器节点和数据键(Key)都通过哈希函数映射到这个圆环上。
当需要存储或读取数据时,系统计算数据Key的哈希值,并在圆环上顺时针查找,遇到的第一个服务器节点即为该数据的归属节点,这种设计带来了两个显著优势:
- 数据局部性增强:只要服务器节点不发生变化,同一Key的数据始终落在同一节点,缓存命中率极高。
- 节点伸缩性良好:当新增或移除节点时,只有受影响的一小部分数据需要重新映射,避免了全量数据迁移带来的巨大开销。
虚拟节点解决数据倾斜问题
在实际应用中,如果服务器节点数量较少,或者服务器性能差异较大,直接映射可能导致数据分布不均,即“数据倾斜”,为了解决这个问题,业内专家指出,引入虚拟节点(Virtual Nodes)是标准做法。
每个物理服务器节点在哈希环上对应多个虚拟节点,这些虚拟节点均匀分布在哈希环上,使得数据分布更加均衡,即使某台物理服务器宕机,其对应的多个虚拟节点也会分散到其他物理服务器上,从而保证系统的整体稳定性。

主流Hash负载均衡软件选型对比
市场上存在多种支持Hash负载均衡的软件方案,从开源组件到商业产品,选择哪一款取决于具体的业务场景和技术栈。
开源方案:Nginx与Redis Cluster
Nginx是最常见的Web服务器,通过配置ip_hash或hash $request_uri指令,可以实现基于IP或URL的Hash负载均衡,这种方式配置简单,适合大多数Web应用,Nginx的Hash算法较为简单,缺乏对节点权重和虚拟节点的精细控制。
对于缓存场景,Redis Cluster是事实上的标准,它内置了基于Slot(槽位)的哈希槽机制,将16384个槽位分布在多个节点上,客户端在访问数据时,先计算Key的哈希值,确定所属槽位,再路由到对应的节点,这种机制不仅实现了Hash负载均衡,还具备自动故障转移和数据分片能力。
商业与专用方案:F5与HAProxy的高级特性
对于对稳定性要求极高的金融或电信行业,F5 BIG-IP等商业负载均衡器提供了更强大的Hash算法支持,包括自定义哈希函数和更细粒度的会话保持策略,HAProxy则以其高性能和灵活性著称,支持多种负载均衡算法,包括基于HTTP Cookie的Hash算法,适合需要保持用户会话一致性的Web应用。
| 软件名称 | 核心算法 | 适用场景 | 配置复杂度 |
|---|---|---|---|
| Nginx | ip_hash, hash | Web流量分发,简单会话保持 | 低 |
| Redis Cluster | 哈希槽(Slot) | 分布式缓存,大数据存储 | 中 |
| HAProxy | cookie, hdr | 高并发Web应用,会话保持 | 中 |
| F5 BIG-IP | 自定义哈希 | 企业级核心业务,高可用性要求 | 高 |
实战部署与常见问题排查
在实际部署Hash负载均衡时,很多团队会遇到数据倾斜、缓存穿透等问题,以下是几个关键的实操步骤和注意事项。
配置步骤示例
以Nginx为例,实现基于URL的Hash负载均衡,可以在

http块中添加以下配置:
upstream backend {
hash $request_uri consistent;
server backend1.example.com:8080;
server backend2.example.com:8080;
server backend3.example.com:8080;
}
这里使用了consistent参数,启用一致性哈希算法,这意味着当后端服务器列表发生变化时,只有少量请求会被重定向到其他服务器,从而减少缓存失效。
常见问题与解决方案
- 热点Key问题:如果某个Key被频繁访问,会导致对应节点负载过高,解决方案是引入多级缓存,或者将热点Key随机分布到多个节点上。
- 节点扩容导致的缓存失效:虽然一致性哈希减少了数据迁移,但新增节点仍会导致部分数据重新分布,建议在扩容前预热缓存,或采用渐进式迁移策略。
- 哈希冲突处理:在分布式系统中,哈希冲突是不可避免的,通常采用链地址法或开放寻址法解决,但在负载均衡层面,主要关注的是节点映射的均匀性,而非单个哈希值的冲突。
未来趋势:智能化与自适应负载均衡
随着AI技术的发展,Hash负载均衡也在向智能化演进,传统的Hash算法是静态的,无法根据实时负载动态调整路由策略,未来的Hash负载均衡软件将结合机器学习算法,实时分析节点负载、网络延迟和业务特征,动态调整哈希函数或节点权重,实现真正的自适应负载均衡。
云原生环境的普及也推动了Hash负载均衡的容器化部署,Kubernetes中的Ingress Controller和Service Mesh技术,正在将负载均衡逻辑下沉到Sidecar代理中,实现更细粒度的流量控制。
Hash负载均衡软件选型指南与价格考量
在决定采用哪种Hash负载均衡方案时,除了技术特性,成本也是重要考量因素,许多企业关注hash负载均衡软件哪个好用,这取决于团队的技术能力和业务规模,对于初创公司,Nginx或开源Redis Cluster是性价比极高的选择,因为它们免费且社区支持强大,对于大型企业,F5或HAProxy的商业版本提供了更好的技术支持和稳定性保障,虽然hash负载均衡软件价格较高,但其带来的业务连续性和性能提升往往能抵消成本。
地域因素也不容忽视,不同地区的网络环境差异可能导致Hash算法的效果不同,在跨国业务中,

hash负载均衡软件推荐可能需要结合全球加速网络(GAN)使用,以确保低延迟和高可用性。
Hash负载均衡软件常见问题解答
Hash负载均衡软件如何实现会话保持?
Hash负载均衡软件通过计算请求中的特定字段(如IP地址、URL、Cookie值等)的哈希值,将请求路由到固定的后端节点,这样,同一用户的多次请求会到达同一台服务器,从而保持会话状态,Nginx的ip_hash指令基于客户端IP地址进行哈希计算,确保同一IP的请求始终由同一后端服务器处理。
Hash负载均衡软件适合哪些业务场景?
Hash负载均衡软件特别适合对数据局部性要求高的场景,如分布式缓存(Redis)、内容分发网络(CDN)和微服务架构中的状态管理,在这些场景中,减少数据迁移和缓存失效能显著提升系统性能,对于无状态服务,简单的轮询负载均衡可能更为合适。
Hash负载均衡软件与一致性哈希算法有什么区别?
Hash负载均衡软件是实现负载均衡的工具,而一致性哈希算法是其中一种核心的路由算法,Hash负载均衡软件可以支持多种算法,如轮询、最少连接数、一致性哈希等,一致性哈希算法是Hash负载均衡软件中的一种高级特性,用于解决节点动态变化时的数据迁移问题。
如何优化Hash负载均衡软件的性能?
优化Hash负载均衡软件的性能可以从以下几个方面入手:一是选择合适的哈希算法,如一致性哈希以减少数据迁移;二是合理设置虚拟节点数量,以平衡数据均匀性和内存占用;三是监控节点负载,及时调整哈希权重;四是使用高效的哈希函数,如MurmurHash,以减少计算开销。
Hash负载均衡软件在云环境中的部署优势是什么?
在云环境中,Hash负载均衡软件可以无缝集成到容器编排平台(如Kubernetes)中,实现自动扩缩容和故障恢复,云提供商通常提供托管的负载均衡服务,如AWS的ALB或Azure的Load Balancer,这些服务内置了Hash负载均衡功能,无需手动配置,降低了运维复杂度,云环境的弹性资源使得Hash负载均衡软件能够轻松应对流量高峰,确保业务连续性。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/448430.html