Hive数据导入MySQL的核心在于利用Sqoop工具或JDBC直连进行异构数据库迁移,关键在于解决大数据量下的性能瓶颈与数据类型映射问题。
将Hive中庞大的离线数据同步到MySQL这种关系型数据库中,是许多数据工程师日常面临的典型场景,这不仅仅是简单的复制粘贴,而是一场关于数据一致性、传输效率和系统稳定性的博弈,很多团队在初期往往低估了Hive到MySQL导出的复杂性,导致生产环境出现内存溢出或数据丢失,业内专家指出,选择合适的迁移工具并优化配置参数,是确保数据平滑流转的关键。
为什么需要Hive导入MySQL
在数据架构中,Hive通常作为数据仓库的核心,存储着海量的历史数据和复杂的多维分析结果,而MySQL则更多地服务于在线业务系统,提供低延迟的事务处理,将Hive数据导入MySQL,通常基于以下具体场景:
- 报表服务支撑:BI工具或前端应用直接连接MySQL查询聚合后的指标,避免直接查询Hive带来的高延迟。
- 业务系统同步:将用户画像、标签体系等离线计算结果同步回业务库,供实时推荐系统调用。
- 数据归档与备份:将冷数据从Hive迁移至成本更低的存储方案,或通过MySQL进行特定维度的快速检索。
这种跨引擎的数据流动,解决了大数据存储与高性能查询之间的断层,让数据价值能够真正落地到业务场景中。
主流技术方案对比与选型
实现Hive到MySQL的数据导入主要有两种主流路径:基于Sqoop的工具化方案和基于Spark/Flink的代码化方案,选择哪种方式,取决于数据量级和对实时性的要求。
Sqoop:经典且稳定的批量迁移工具
Sqoop(SQL-to-Hadoop)是Apache旗下的经典工具,专为Hadoop与关系型数据库之间的数据 transfer 设计,它通过生成MapReduce任务来并行导入导出数据,适合大规模离线数据的批量处理。

- 优势:配置简单,支持增量导入,自动处理数据类型映射,社区成熟。
- 劣势:依赖Hadoop集群资源,启动开销较大,不适合微批处理。
- 适用场景:每日T+1的全量或增量数据同步,数据量在GB至TB级别。
Spark JDBC:灵活高效的代码化方案
随着Spark成为大数据处理的事实标准,利用Spark DataFrame的JDBC源直接写入MySQL成为另一种流行选择,这种方式允许开发者在代码中灵活控制数据转换逻辑。
- 优势:内存计算速度快,支持复杂的ETL逻辑,易于集成到现有Spark作业中。
- 劣势:需要自行处理连接池管理和并发控制,否则容易压垮MySQL。
- 适用场景:需要复杂数据清洗后的实时或近实时同步,数据量在百万至千万级。
实操指南:使用Sqoop进行数据导入
对于大多数传统离线同步场景,Sqoop依然是首选,以下是具体的操作步骤和关键参数解析。
环境准备与连接测试
在执行导入之前,必须确保Hadoop集群与MySQL之间的网络互通,且Hive Metastore可访问,测试MySQL驱动是否已正确放置在Sqoop的lib目录下。
使用以下命令测试连接:
sqoop list-tables --connect jdbc:mysql://hostname:3306/database_name --username user --password pass
如果成功列出表名,说明基础连接无误。
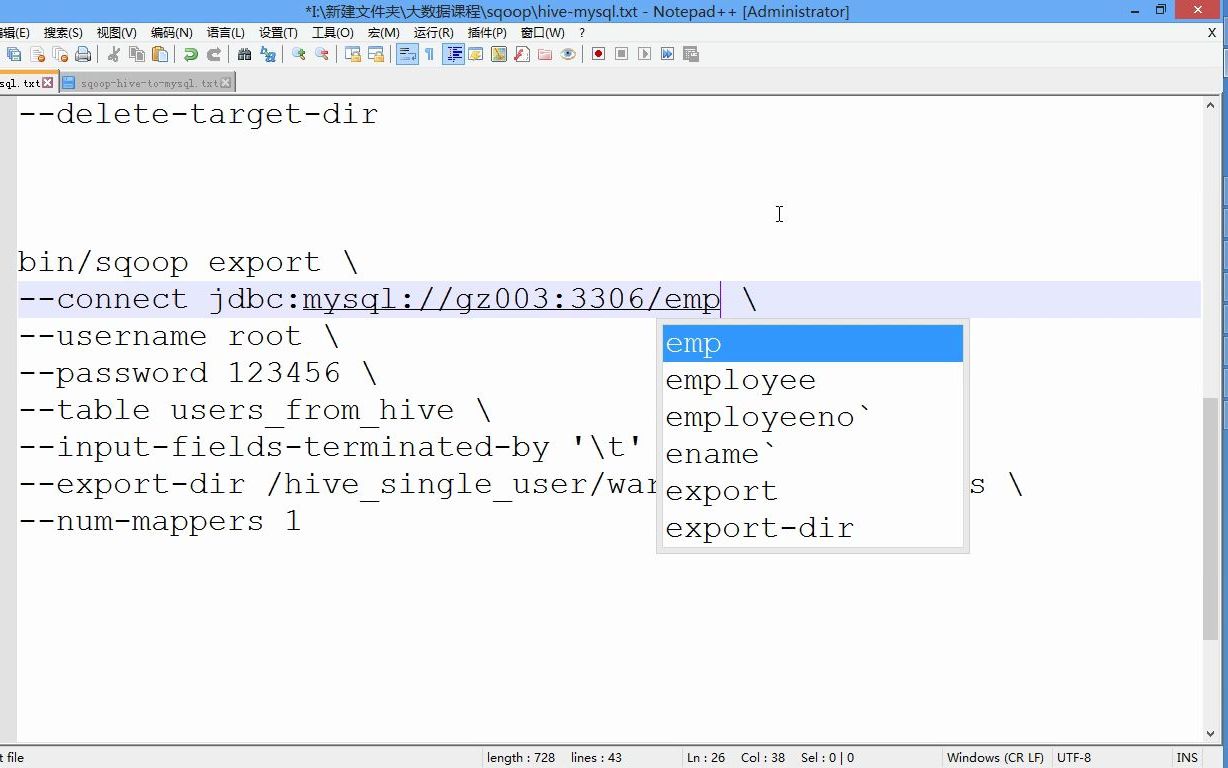
核心导入命令详解
假设我们要将Hive表user_behavior导入MySQL表user_behavior_sync,常用命令如下:
sqoop export --connect jdbc:mysql://mysql_host:3306/target_db --username root --password your_password --table user_behavior_sync --export-dir /user/hive/warehouse/user_behavior --input-fields-terminated-by '�01' --input-lines-terminated-by 'n' --num-mappers 4 --batch

这里有几个关键参数需要特别注意:
- –num-mappers:设置并发Map任务数,通常建议设置为4-8个,过多会导致MySQL连接数激增,过少则传输效率低。
- –batch:启用JDBC批量插入模式,显著提升写入性能。
- –input-fields-terminated-by:指定Hive文件中的字段分隔符,必须与Hive表定义一致。
增量导入策略
全量导入耗时耗力,增量导入是更优解,Sqoop支持两种增量模式:
- Append模式:追加新记录,通常基于自增ID或时间戳。
- LastModified模式:基于最后修改时间戳,适合更新场景。
基于时间戳的增量导入命令:
sqoop export
--connect jdbc:mysql://mysql_host:3306/target_db
--table user_behavior_sync
--export-dir /user/hive/warehouse/user_behavior/dt=${date}
--check-column create_time
--incremental lastmodified
--last-value "2026-10-01 00:00:00"
常见陷阱与性能优化建议
在实际操作中,Hive导入MySQL经常遇到性能瓶颈或数据异常,以下是基于行业共识的优化建议。
避免MySQL连接池耗尽
当Map任务过多时,每个Mapper都会尝试建立独立的数据库连接,如果MySQL的max_connections限制较低,会导致连接拒绝。
- 解决方案:减少
--num-mappers数量,或在MySQL端调整连接池配置,对于千万级数据,建议将Mapper数量控制在4-8个以内。
数据类型映射错误
Hive中的String类型在MySQL中可能对应VARCHAR或TEXT,如果数据长度超过MySQL字段定义,会导致导入失败或截断。

- 解决方案:在Hive导出前,使用
CAST函数明确转换数据类型,或在MySQL端预先创建足够大的字段类型。
大数据量下的内存溢出
单个Mapper处理的数据块过大,可能导致YARN容器OOM(Out Of Memory)。
- 解决方案:调整Hive表的分区策略,确保每个分区的数据量适中,在Sqoop命令中增加
--hadoop-mapreduce-map-java_opts参数,适当增加堆内存。
Hive导入MySQL相关常见问题解答
Hive导入MySQL时出现中文乱码怎么办?
乱码通常源于字符集不一致,Hive默认可能使用UTF-8,而MySQL表可能使用GBK,解决方案是在MySQL建表时指定CHARSET=utf8mb4,并在Sqoop连接URL中添加?useUnicode=true&characterEncoding=UTF-8参数,确保Hive表的SerDe序列化器也设置为UTF-8编码。
如何判断Hive导入MySQL是否成功?
不能仅依赖Sqoop任务的Exit Code,必须执行数据校验,对比Hive源表和MySQL目标表的记录总数,使用COUNT()进行核对,抽样检查关键字段的值是否一致,特别是日期和数值类型,对于增量导入,还需验证last-value时间戳是否正确更新。
Sqoop与Spark JDBC哪种更适合实时同步?
Sqoop设计用于批量离线处理,不适合毫秒级实时同步,如果需要实时或近实时同步,Spark Structured Streaming或Flink JDBC Sink是更好的选择,它们支持流式处理,能够以低延迟将数据写入MySQL,对于T+1的离线报表场景,Sqoop因其稳定性和易用性,仍然是性价比最高的选择。
Hive导入MySQL并非简单的工具调用,而是一项需要综合考虑数据规模、实时性需求和系统资源的系统工程,选择Sqoop进行批量离线同步,或Spark进行灵活处理,关键在于根据实际业务场景做出精准匹配。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/456872.html