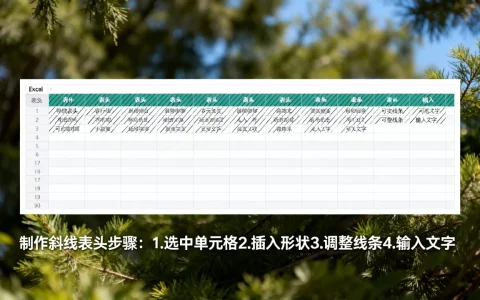
Excel熵值法是一种基于信息熵理论客观赋权的统计方法,它能通过数据本身的离散程度自动计算权重,有效避免人为打分的主观偏差,是处理多指标综合评价问题的首选工具。
在数据分析的日常工作中,我们常常面临这样一个困境:想要评估一个项目的综合表现,但各个指标的重要性到底该如何界定?是拍脑袋决定,还是依赖专家经验?这两种传统方式都存在明显的短板,前者随意性太大,后者成本高且易受个人偏好影响,熵值法恰恰解决了这个痛点,它不依赖任何外部主观判断,而是让数据“自己说话”,当某个指标在不同样本间的差异越大,说明它提供的信息量越多,在综合评价中的权重就应当越高,这种逻辑简单而有力,特别适合那些需要快速建立客观评价体系的场景。
为什么选择Excel熵值法进行客观赋权
很多初学者会问,既然有SPSS或Python,为什么还要死磕Excel?这其实是一个关于成本和效率的权衡问题,对于大多数企业用户而言,安装专业软件的学习曲线陡峭,且代码调试耗时,Excel作为办公标配,其优势在于普及率高、操作直观。
主观赋权与客观赋权的本质区别
业内专家指出,主观赋权法(如AHP层次分析法)依赖于决策者的经验判断,容易受到“锚定效应”的影响,相比之下,客观赋权法完全基于数据分布特征,熵值法的核心逻辑在于“熵”的概念,在信息论中,熵衡量的是系统的不确定性,在评价体系中,如果所有样本在某指标上的数值几乎一样(例如所有公司的利润率都是5%),那么这个指标就无法区分优劣,其信息熵最大,权重应趋近于零,反之,如果数值差异巨大,信息熵小,权重则大。
Excel实现的技术门槛分析
使用Excel实现熵值法并不需要复杂的编程知识,主要依赖基础的函数运算,虽然步骤稍多,但逻辑链条清晰,对于非技术背景的业务人员,掌握这一方法意味着能够独立产出具有说服力的分析报告,这在汇报工作时是一个巨大的加分项,据行业共识认为,掌握至少一种客观赋权方法已成为数据分析师的基础技能之一。

Excel熵值法实操全流程拆解
想要真正掌握熵值法,光懂理论不够,必须动手操作,以下是在Excel中构建熵值法模型的标准路径,建议新建一个工作表,按照步骤逐步执行。
第一步:数据标准化处理
原始数据往往量纲不同,销售额”是万元,“满意度”是百分制,直接计算会导致大数值指标占据主导,必须先进行无量纲化处理。
极差标准化公式
对于正向指标(越大越好),公式为:$X’ = (X – min) / (max – min)$。
对于负向指标(越小越好),公式为:$X’ = (max – X) / (max – min)$。
在Excel中,可以使用MIN和MAX函数结合绝对引用(如$A$1)快速拉出所有数据的标准化值,这一步至关重要,它确保了不同指标之间具有可比性。
第二步:计算比重与熵值
标准化完成后,需要计算每个指标下各样本值的比重,公式为:$P{ij} = X’{ij} / sum X’_{ij}$。
接着计算信息熵 $e_j$,公式为:$ej = -k sum (P{ij} ln P{ij})$,$k = 1 / ln n$,n为样本数量。
这里有一个常见的陷阱:$P{ij}$ 为0,则 $0 ln 0$ 在数学上定义为0,在Excel中,建议使用IF函数处理零值,避免报错。=IF(Pij=0, 0, PijLN(Pij))。
第三步:计算权重与综合得分
得到熵值后,计算差异系数 $d_j = 1 – e_j$。
最终权重 $w_j = d_j / sum dj$。
有了权重,就可以计算每个样本的综合得分:$Score = sum (P{ij} times w_j)$。
至此,一个完整的客观评价体系就搭建完成了,你可以将结果排序,直观地看到哪些样本表现最佳。
常见误区与优化策略
在实际应用中,直接套用公式往往会出现意想不到的问题,以下是几个高频踩坑点及解决方案。
数据极值的影响
如果数据中存在极端异常值,标准化后的结果可能会失真,某项指标绝大多数值为10,但有一个值为1000,这会导致其他数据的标准化值极度压缩,区分度降低。
建议方案:在标准化前,先对数据进行清洗,剔除明显的离群点,或者使用对数变换等非线性变换方法预处理数据,以平滑极端值的影响。

指标间的相关性干扰
熵值法假设指标间相互独立,如果两个指标高度相关(如“营业收入”和“净利润”),它们提供的信息会有大量重叠,导致权重被重复计算。
建议方案:在引入指标前,先进行相关性分析,如果相关系数超过0.8,建议保留其中一个,或采用主成分分析法(PCA)降维后再使用熵值法。
不同场景下的应用差异
熵值法并非万能钥匙,在不同场景下需要灵活调整。
企业绩效考核场景
在员工或部门考核中,熵值法能客观反映业绩分布,但需注意,绩效考核往往包含定性指标(如工作态度),熵值法仅适用于定量数据,对于定性指标,建议结合德尔菲法(专家打分)确定权重,再与定量指标合并计算。
区域竞争力评价场景
在评估不同城市或省份的发展水平时,数据通常来自统计年鉴,量级差异巨大,标准化处理必须严谨,由于各地数据缺失情况不同,插补数据的方法(如均值插补、回归插补)会直接影响熵值结果,需在报告中明确说明。
供应链供应商评估场景
在采购决策中,价格、交期、质量是核心指标,价格通常是负向指标,而质量和交期(越快越好)是正向指标,利用熵值法,可以动态调整权重,当市场价格波动剧烈时,价格指标的离散度变大,其权重自然上升,从而更敏锐地捕捉成本差异。
熵值法与其他方法的对比选择
面对复杂的评价需求,如何选择最合适的方法?
| 方法 | 核心依据 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 熵值法 | 数据离散程度 | 完全客观,无主观偏差 | 对数据质量敏感,可能违背常识 | 数据充足,追求客观性的场景 |
| AHP层次分析法 | 专家两两比较 | 逻辑清晰,可结合定性因素 | 主观性强,一致性检验复杂 | 指标少,依赖专家经验的场景 |
| CRITIC法 | 对比强度与冲突性 | 考虑了指标间的冲突关系 | 计算稍复杂,对数据分布要求高 | 指标间相关性较强的场景 |

业内专家指出,没有绝对最好的方法,只有最适合场景的方法,如果数据量大且追求效率,熵值法是首选;如果指标少且需要融入管理意图,AHP更合适;如果指标间存在强冲突,CRITIC法值得考虑。
Q&A:关于Excel熵值法的常见疑问
Excel熵值法计算结果与专业软件不一致怎么办?
这通常源于标准化方式或ln底数的选择差异,Excel默认使用自然对数ln,而某些软件可能使用log10,只要统一对数底数,并确保标准化公式一致(如均使用极差标准化),结果应当一致,若仍有偏差,请检查是否处理了零值,以及是否使用了正确的样本数n。
如何处理包含缺失值的数据集?
熵值法无法直接处理缺失值,在计算前,必须对缺失数据进行填补,常用的方法包括均值填补、中位数填补或基于回归的预测填补,选择哪种方法取决于缺失机制和数据分布,据工信部相关数据指引,在缺乏特定领域标准时,均值填补是最常用且风险较低的基础手段。
熵值法得出的权重是否一定符合业务逻辑?
不一定,熵值法纯粹基于数学统计,可能得出“看似不合理”的权重,某个业务上认为重要的指标,如果所有样本表现都很接近,其权重会被压得很低,熵值法得出的权重应作为参考,最终权重确定建议采用“主客观组合赋权法”,即结合专家意见和熵值法结果进行加权平均,以兼顾客观性与业务合理性。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/457585.html