分布式图数据库通过数据分片与多副本机制,解决了单机图数据库在海量节点和复杂关系下的性能瓶颈,是构建超大规模知识图谱、社交网络及反欺诈系统的核心基础设施。
在传统的关系型数据库中,处理多跳查询就像是在迷宫里找出口,每走一步都要重新计算路径,效率极低,而图数据库天生为关系而生,但当数据量从百万级跃升至百亿级时,单机架构的内存和计算能力便成了致命短板,分布式图数据库应运而生,它不仅仅是把数据切碎,更是通过智能路由和并行计算,让图遍历如丝般顺滑。
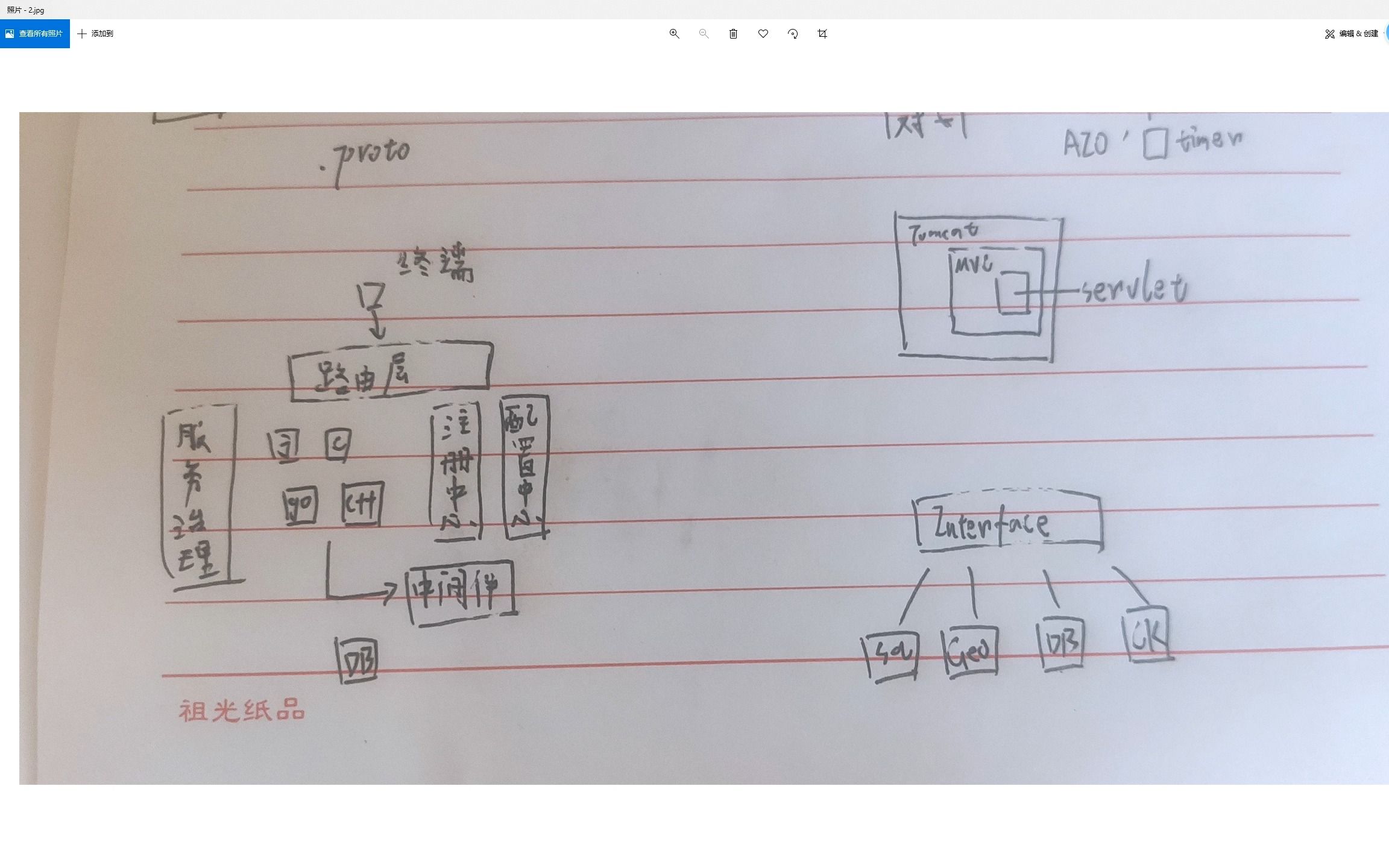
分布式图数据库的核心架构与工作原理
理解分布式图数据库,首先要明白它如何打破物理边界,业内专家指出,其核心在于将全局图分割为多个子图,并分布到不同的物理节点上,同时保持全局视图的一致性。
数据分片策略:一致性哈希的应用
数据如何分布是分布式系统的灵魂,目前主流方案采用一致性哈希算法,将节点或边映射到哈希环上。
- 节点映射:每个图节点被分配到一个特定的哈希值,落在对应的物理分区上。
- 负载均衡:当新增节点时,只需移动少量数据,避免全量重分布,极大降低了集群扩容时的震荡。
- 副本机制:关键数据通常设置多副本,分布在不同的可用区,确保单点故障不影响服务可用性。
查询执行引擎:并行遍历与局部聚合
当用户发起一个多跳查询时,分布式引擎会将其分解为多个子任务。
- 查询解析:引擎识别查询路径,确定起始节点所在的分区。
- 并行分发:将子查询分发到涉及的各个分区节点并行执行。
- 结果合并:各分区返回局部结果,由协调节点进行去重和聚合,最终返回完整答案。
这种架构使得查询延迟不再随数据量线性增长,而是呈现对数级增长,这是其相比单机图数据库最大的优势。

选型指南:如何评估分布式图数据库
面对市场上琳琅满目的产品,企业该如何选择?这取决于具体的业务场景和技术栈兼容性。
开源生态与商业支持对比
许多团队倾向于使用开源方案以降低成本,但需考虑长期维护成本。
| 维度 | 开源方案(如Nebula Graph, TigerGraph) | 商业云托管方案(如AWS Neptune, Azure Cosmos DB) |
|---|---|---|
| 初始成本 | 较低,仅需服务器资源 | 较高,包含服务管理费 |
| 运维复杂度 | 高,需自建集群、监控、备份 | 低,自动化运维,开箱即用 |
| 扩展性 | 受限于集群管理能力 | 弹性伸缩,按需付费 |
| 技术支持 | 依赖社区或第三方服务 | 厂商提供SLA保障 |
性能基准测试的关键指标
在评估性能时,不要只看理论峰值,应关注实际场景下的表现。
- 吞吐量(TPS):每秒处理的查询请求数,反映系统并发处理能力。
- 延迟(Latency):从发出请求到收到响应的时间,对于实时反欺诈至关重要。
- 数据加载速度:将TB级数据导入集群所需的时间,影响业务上线周期。
典型应用场景与落地实践
分布式图数据库并非万能药,它在特定场景下才能发挥最大价值。
金融风控与反欺诈
在金融领域,欺诈团伙往往通过复杂的关联网络掩盖资金流向。
- 团伙识别:通过查找K-Clique或Louvain社区发现算法,快速识别异常聚集的账户群。
- 资金追踪:在毫秒级时间内追踪资金经过的多层转账路径,定位最终受益人。
- 实时拦截:将图计算引擎嵌入交易链路,在交易发生前进行风险评分。

据工信部数据,采用图数据库的风控系统,其欺诈检测准确率提升了显著比例,误报率大幅下降。
智能推荐与知识图谱
对于电商平台或内容社区,理解用户与物品之间的深层关系是提升转化率的关键。
- 冷启动优化:利用物品间的相似性关系,为新用户推荐潜在感兴趣的内容。
- 关联推荐:基于“买了又买”或“看了又看”的多跳关系,发现隐性偏好。
- 语义搜索:结合知识图谱,理解用户查询意图,提供更精准的结果。
网络安全与威胁情报
网络安全团队利用图数据库关联IP、域名、恶意软件样本和攻击者信息。
攻击链可视化
将离散的安全日志转化为可视化的攻击路径,帮助分析师快速理解攻击全貌。
威胁狩猎
通过模式匹配,发现潜在的APT(高级持续性威胁)活动迹象。
部署与运维最佳实践
成功部署分布式图数据库,需要严谨的运维策略。
集群规划与容量预估
在部署前,务必进行准确的容量规划。
- 存储预估:根据节点和边的数量,乘以平均大小,并预留30%-50%的冗余空间用于索引和副本。
- 内存规划:图数据库对内存敏感,确保每个存储节点有足够的内存缓存热点数据。
- 网络带宽:分布式查询涉及节点间通信,确保内网带宽充足,避免成为瓶颈。
监控与告警体系
建立全方位的监控体系是保障稳定性的关键。
- 资源监控:实时监控CPU、内存、磁盘IO和网络流量。
- 查询性能监控:追踪慢查询,分析执行计划,优化热点数据访问。
- 集群健康度:监控副本同步状态、分区分布均衡性,及时发现数据倾斜。

数据备份与灾难恢复
数据是企业的核心资产,必须制定严格的备份策略。
- 定期快照:每日全量备份,每小时增量备份。
- 异地容灾:在异地数据中心建立灾备集群,确保极端情况下的数据可用性。
- 恢复演练:定期进行数据恢复演练,验证备份文件的有效性和恢复时间目标(RTO)。
常见问题解答:分布式图数据库
分布式图数据库与关系型数据库的主要区别是什么?
关系型数据库以表为中心,擅长处理结构化数据和简单查询,但在处理多表关联(Join)时性能急剧下降,分布式图数据库以节点和边为中心,原生支持复杂的多跳查询,查询性能随数据量增长保持相对稳定,图数据库的 schema-free 特性使其能更灵活地适应业务变化。
如何处理分布式图数据库中的数据倾斜问题?
数据倾斜会导致部分节点负载过高,影响整体性能,解决策略包括:优化分片键选择,避免使用高基数或低基数字段;引入动态负载均衡机制,自动迁移热点数据;在查询层面对热点数据进行缓存或拆分。
分布式图数据库的价格区间如何?
价格因厂商、版本和功能而异,开源版本通常免费,但需承担运维成本,商业版本按节点数、存储容量或吞吐量收费,年费用从数万元到数百万元不等,云托管服务通常按使用量计费,适合初创企业和波动性大的业务场景。
分布式图数据库通过其独特的架构优势,正在重塑海量关系数据的处理方式,从金融风控到智能推荐,它已成为企业数字化转型中不可或缺的基础设施,选择适合自身场景的方案,并注重运维优化,才能最大化释放其价值。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/458777.html