在Hive中获取特定时间段内的数据库数据,核心在于利用WHERE子句结合时间戳或日期字段进行过滤,同时需确保底层存储格式(如Parquet/ORC)支持分区裁剪以提升查询效率。
处理海量数据时,时间维度的筛选是最常见也最易出错的场景,很多初学者直接在全表扫描后做过滤,导致任务超时或资源耗尽,Hive作为基于Hadoop的数据仓库工具,其性能瓶颈往往不在计算,而在I/O,掌握高效的时间段查询技巧,是数据工程师的必修课。
Hive时间段查询的基础逻辑与常见误区
在处理日志、交易记录等时序数据时,我们首先需要明确数据的存储形态,Hive本身不存储数据,它只是元数据的管理者,数据实际存储在HDFS上,这意味着,查询效率极大程度上取决于数据是如何组织存储的。
直接过滤 vs 分区裁剪
业内专家指出,大多数性能问题源于忽视了分区裁剪(Partition Pruning),如果数据表按照dt(日期)进行了分区,那么查询2026年1月的数据时,Hive应该只读取该月的分区目录,而不是扫描所有历史分区。
- 错误写法:在查询条件中使用函数包裹字段,如
WHERE date_format(dt, 'yyyy-MM') = '2026-01',这会导致全表扫描,因为函数破坏了索引和分区的直接匹配。 - 正确写法:直接使用范围比较,如
WHERE dt >= '2026-01-01' AND dt <= '2026-01-31',这样Hive优化器可以识别分区边界,跳过无关数据。
时间字段的类型选择
在创建表结构时,时间字段的类型选择直接影响查询的便捷性和性能。
- String类型:最常用,格式如
'2026-01-15',优点是兼容性好,缺点是字符串比较逻辑复杂,且占用空间较大。 - Timestamp类型:精度更高,支持时分秒,优点是支持复杂的时间函数,缺点是存储格式转换开销略大。
- Long类型(Unix时间戳):存储从1970-01-01到现在的秒数,优点是计算速度最快,比较效率最高,缺点是可读性差,需要转换才能查看。
实战场景:如何精准提取指定时间窗口的数据

针对不同的业务需求,我们通常面临几种典型的时间段查询场景,无论是排查故障、生成日报,还是进行用户行为分析,掌握以下具体操作路径至关重要。
查询最近N天的数据
这是运维监控和日报生成中最常见的需求,我们需要获取过去7天的订单数据。
- 使用内置函数:Hive提供了
current_date()和date_sub()函数。 - SQL示例:
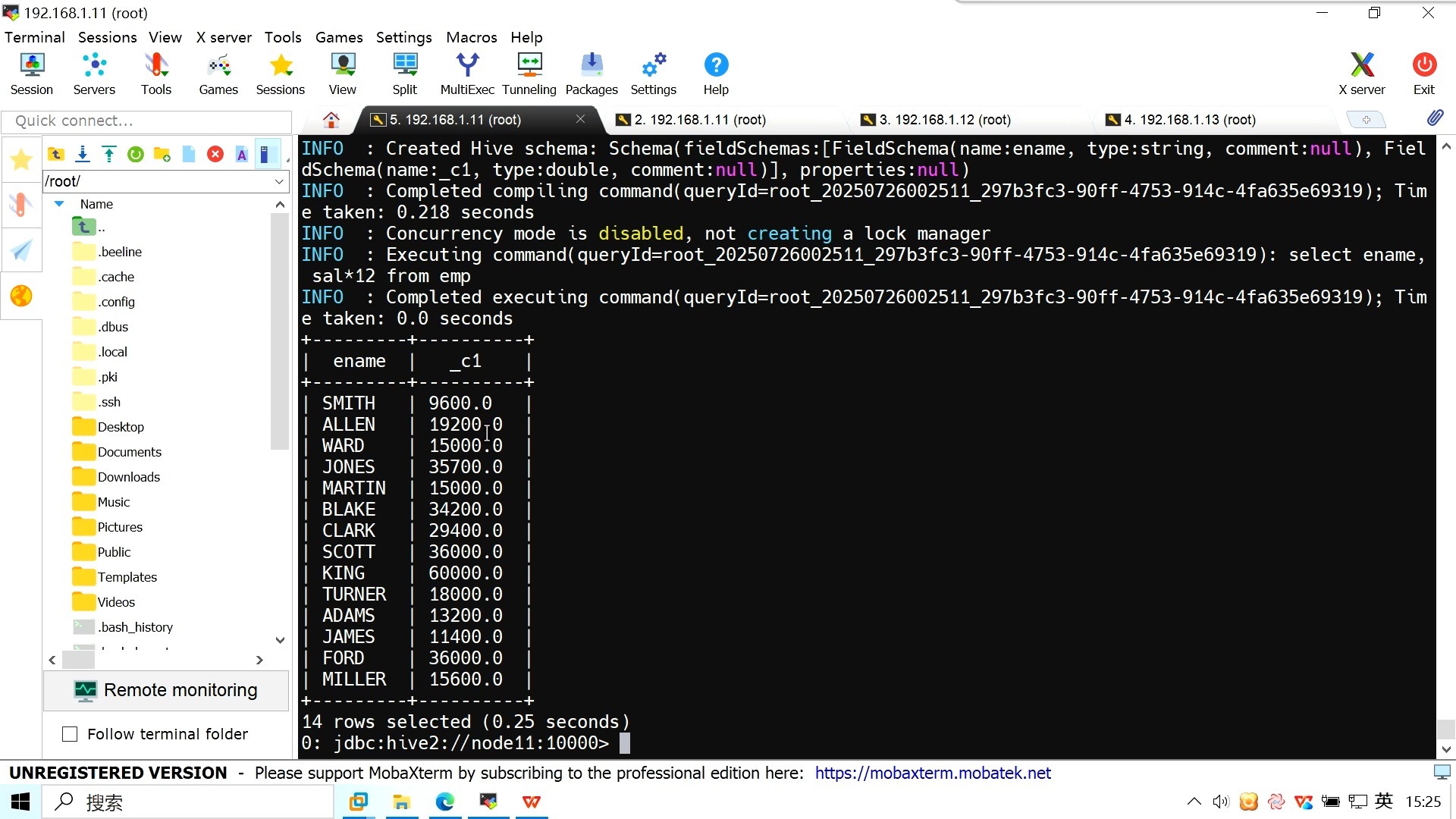
SELECT FROM orders WHERE dt >= date_sub(current_date(), 7) AND dt < current_date();
注意这里使用了小于号
<而不是小于等于,这是为了避免包含当天0点的数据重复或遗漏,具体取决于业务对“当天”的定义。
跨天复杂时间区间过滤
当需要查询非整天的时间段,2026年1月1日 10:00 到 1月2日 10:00”,且数据存储在Timestamp字段中时,操作稍显复杂。
- 步骤一:确保时间字段类型为
timestamp或string。 - 步骤二:使用
to_timestamp()或cast()进行类型转换,确保比较的一致性。 - 步骤三:构建范围查询。
SELECT FROM user_behavior WHERE event_time >= to_timestamp('2026-01-01 10:00:00') AND event_time < to_timestamp('2026-01-02 10:00:00');这种写法避免了在WHERE子句中对字段进行函数运算,从而保留了分区裁剪的可能性(假设event_time与分区字段有映射关系或数据本身已按时间排序存储)。
处理时区问题
在全球化业务中,服务器时间、数据库时间和用户本地时间往往存在差异,Hive默认使用UTC时间或服务器本地时间。
- 建议:在数据入库阶段(ETL)统一转换为UTC时间存储。
- 查询时:如果业务需要显示本地时间,应在查询结果中通过
from_utc_timestamp()进行转换,而不是在过滤条件中转换,以保证查询性能。
优化技巧:让Hive查询飞起来
除了正确的SQL写法,合理的配置和表结构设计是提升查询速度的关键,特别是在处理PB级数据时,这些细节决定了任务能否在SLA时间内完成。

启用动态分区
如果数据量巨大,静态分区可能导致分区文件过多或过少,动态分区允许Hive根据查询结果自动创建分区。
- 配置项:
set hive.exec.dynamic.partition=true; - 注意事项:务必设置
hive.exec.dynamic.partition.mode=nonstrict,否则默认严格模式要求至少有一个分区是静态的,这在某些复杂场景下会限制灵活性。
利用CBO(基于成本的优化器)
较新版本的Hive支持CBO,它会根据统计信息选择最优的执行计划。
- 操作:确保表的统计信息是最新的。
- 命令:
ANALYZE TABLE orders COMPUTE STATISTICS; - 效果:CBO能够更准确地估算数据倾斜和连接顺序,特别是在多表关联且包含时间过滤时,效果显著。
小文件合并
频繁的时间段查询往往伴随着小文件问题,因为数据可能是按小时或分钟写入的。
- 解决方案:在查询前或定期执行Map端合并。
- 配置:
set hive.merge.mapfiles=true;和set hive.merge.mapredfiles=true; - 原理:这会在Map任务结束后合并小文件,减少NameNode的压力和后续查询的启动开销。
常见问题排查与解决方案
在实际操作中,即使SQL写对了,也可能遇到各种奇怪的问题,以下是几个高频故障点及其解决思路。
问题1:查询结果为空,但预期有数据
- 原因:时间格式不匹配,字段是
'2026-01-01 00:00:00',而查询条件只写了'2026-01-01',在字符串比较中,后者可能被视为小于前者。 - 解决:统一使用
>=和<的范围比较,或者使用date()函数截断时间部分后再比较。
问题2:查询速度极慢,甚至OOM(内存溢出)
- 原因:数据倾斜,某些时间段的数据量远大于其他时间段(如双11当天的流量)。
- 解决:
- 开启Map端聚合:
set hive.map.aggr=true; - 调整Reducer数量:
set hive.exec.reducers.bytes.per.reducer=1000000000; - 考虑将热点时间段的数据单独存储或预聚合。
- 开启Map端聚合:

问题3:时区显示错误
- 原因:Hive会话时区与数据实际时区不一致。
- 解决:在会话开始时设置时区:
set hive.exec.scratchdir=/tmp/hive-${user.name}; set hive.users.in.admin.role=admin;更直接的是在SQL中使用from_utc_timestamp()或to_utc_timestamp()显式转换。
Hive获取时间段内数据库相关Q&A
如何高效查询Hive中过去一个月的数据?
高效查询的核心是避免全表扫描,确认数据表是否按天或按月进行了分区,如果已分区,直接使用WHERE dt >= '2026-01-01' AND dt < '2026-02-01'这样的范围条件,Hive会自动进行分区裁剪,只读取相关目录,如果未分区,则必须使用date_sub(current_date(), 30)等函数,但性能会大幅下降,建议优先采用分区表结构,并在ETL过程中确保分区字段的准确性。
Hive中时间字段应该用String还是Timestamp?
这取决于业务场景对精度和性能的需求,对于绝大多数日志和交易数据,推荐使用Timestamp类型,因为它支持更丰富的时间函数运算,如时区转换、时间差计算等,且存储效率高于String,如果数据量极大且仅需按天聚合,String类型的yyyy-MM-dd格式配合分区表也是可行的选择,但其灵活性较差,避免使用Long类型的Unix时间戳,除非对查询性能有极致要求且团队具备完善的转换工具链。
为什么我的Hive时间段查询结果包含重复数据?
重复数据通常源于时间边界处理不当或数据源本身的问题,首先检查SQL中的边界条件,确保使用>=和<而非>=和<=,以避免跨天数据在边界处的重复或遗漏,检查ETL过程,确保同一时间点的数据只被写入一次,如果使用了Union All操作,需检查各子查询的时间区间是否有重叠。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/459922.html