在Python中,% x 是取模运算符,用于计算两个数相除后的余数,它是处理循环逻辑、数据分组和奇偶判断的核心工具。
很多初学者看到 符号,第一反应是“百分号”,但在 Python 编程语境下,它的角色完全不同,它不仅仅是一个数学符号,更是控制程序流向的“交通指挥员”,当你需要让程序“每隔几步执行一次”或者“判断数据是否整除”时,% x 就是那个最精准的开关,理解它的底层逻辑,比死记硬背语法要重要得多。
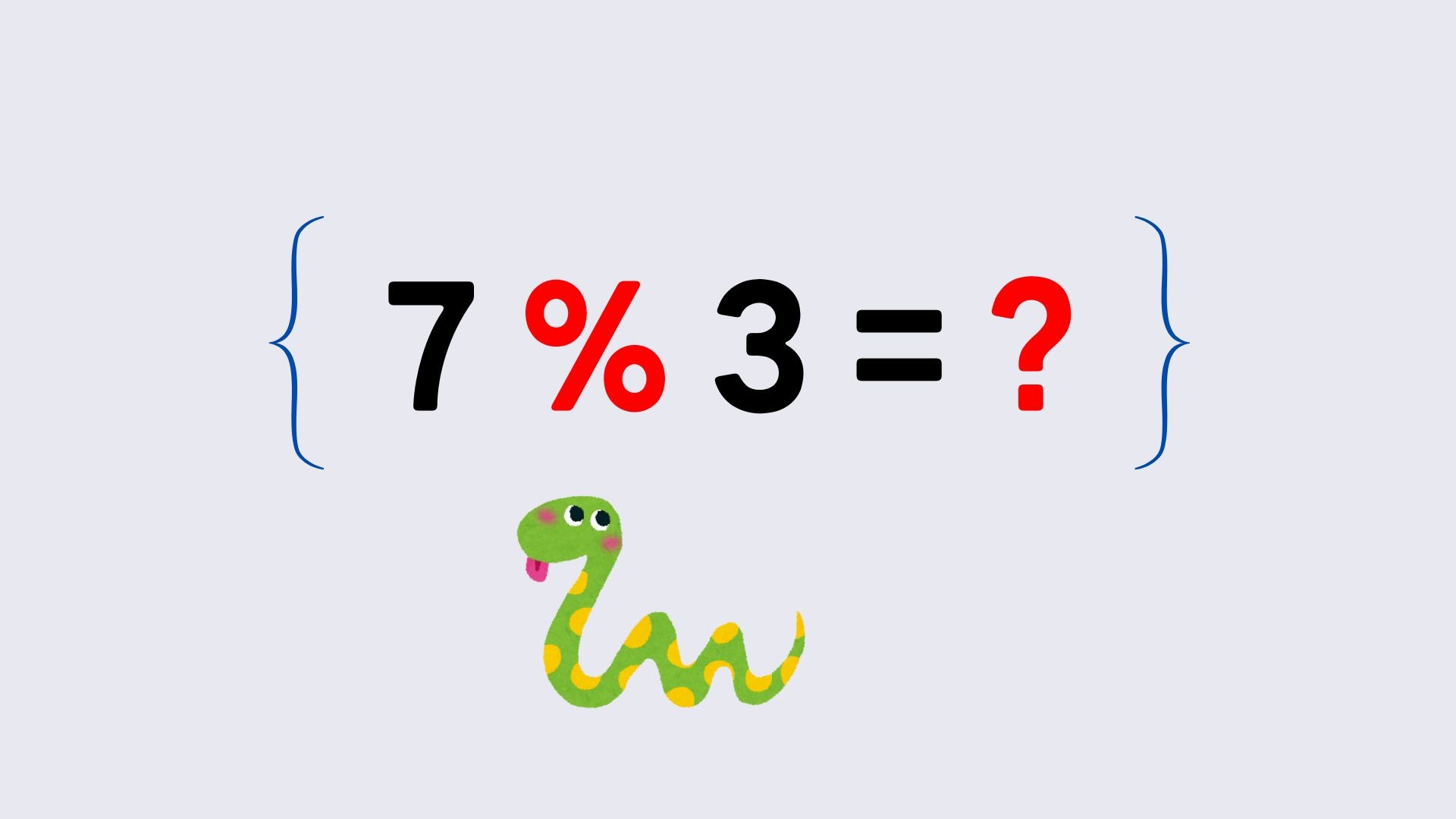
Python取模运算的基本逻辑与场景
取模运算的本质是“除不尽的部分”,想象你有 10 个苹果,每 3 个装一袋,你能装满 3 袋,最后剩下 1 个,这剩下的 1 个,10 % 3 的结果,在代码世界里,这种“剩余”的概念被无限放大,应用在各个角落。
奇偶判断与分页逻辑
这是 最经典的应用场景,在开发后台管理系统或前端展示时,我们经常需要处理列表的分页显示。
- 奇偶性检查:判断一个数字是奇数还是偶数,只需看它除以 2 的余数。
num % 2 == 0,则是偶数;否则是奇数,这种写法比复杂的条件判断更简洁、更高效。 - 表格斑马纹:在前端渲染列表时,为了让用户看得更清楚,通常会让奇数行和偶数行颜色不同,通过
index % 2的结果,可以精准地给 DOM 元素添加不同的 CSS 类名。
循环控制与周期性任务
在处理大量数据或模拟周期性事件时, 能帮你实现“每 N 次执行一次”的逻辑。
在一个遍历 1000 条数据的循环中,你希望每处理 100 条就打印一次进度条,你可以这样写:
for i in range(1000):
if i % 100 == 0:
print(f"进度:{i}%")
这种逻辑在爬虫开发中尤为常见,比如每抓取 50 个页面,就暂停 1 秒,避免被目标网站封禁,这里的 50 就是那个关键的 x。
Python取模运算的高级技巧与陷阱

虽然基础用法简单,但在实际工程中, 运算符隐藏着一些容易被忽视的细节,特别是涉及负数或浮点数时,结果可能与你直觉中的数学结果不同。
负数取模的特殊行为
在数学课本里,余数通常是非负的,但在 Python 中,取模结果的符号与被除数(第一个数)保持一致,这是一个巨大的差异点,很多从 C 或 Java 转过来的开发者容易在这里踩坑。
看看下面的对比:
7 % 3结果是1-7 % 3结果是2(因为 -7 = 3 (-3) + 2)7 % -3结果是-2(因为 7 = (-3) (-3) – 2)-7 % -3结果是-1
业内专家指出,这种设计使得取模运算在计算时间偏移量或数组索引环绕时更加符合直觉,在时钟计算中,-1 % 12 得到 11,这正好对应凌晨 11 点,逻辑非常自洽。
浮点数取模的精度问题
当 x 是浮点数时, 运算依然有效,但需要注意浮点数的精度误差。
1 + 0.2 == 0.3 # False (0.1 + 0.2) % 0.1 # 结果可能不是精确的 0.0
据统计,在金融计算或高精度科学计算中,直接使用浮点数取模可能导致微小的误差累积,对于涉及金额或高精度要求的场景,建议使用 decimal 模块,或者先进行四舍五入处理后再取模。
Python取模运算与其他语言的对比分析
不同编程语言对取模运算的定义存在细微差别,了解这些差异有助于你在多语言环境中保持代码的一致性。
Python与C/Java的差异
| 特性 | Python | C / Java |
|---|---|---|
| 负数取模结果符号 | 与被除数一致 | 与除数一致 |
|
示例:-7 % 3 | 2 | -1 |
| 浮点数支持 | 完全支持 | 完全支持 |
| 大整数处理 | 自动支持无限精度 | 可能溢出 |

这种差异源于底层实现机制的不同,Python 倾向于数学上的“向下取整”除法,而 C 系列语言倾向于“向零取整”,在编写跨语言接口或移植代码时,务必注意这一区别,否则可能导致逻辑错误。
性能考量
在高性能计算场景下,取模运算的速度是一个值得关注的指标。
- 整数取模:在现代 CPU 上,整数取模指令的执行周期相对固定,速度较快。
- 大整数取模:Python 的大整数支持意味着随着数字变大,取模运算的时间复杂度会线性增加,对于超大整数(如 RSA 加密中的密钥),直接使用 可能效率低下,此时应使用专门的库(如
gmpy2)进行优化。
行业共识认为,在常规业务逻辑中, 的性能瓶颈几乎可以忽略不计,只有在处理亿级数据循环或实时高频交易系统中,才需要考虑优化取模算法,例如使用位运算替代 2 的幂次取模(x % 4 等价于 x & 3)。
Python取模运算实战案例解析
理论终归要落地,下面通过两个具体的实战场景,展示如何灵活运用 x 参数来解决实际问题。
数据分桶与负载均衡
假设你有一个分布式系统,需要将用户请求均匀分配到 5 个服务器节点上,最简单的方法就是利用用户 ID 的哈希值或 ID 本身进行取模。
def get_server_node(user_id, total_nodes=5):
return user_id % total_nodes
这种方法简单高效,能确保 ID 相近的用户被分配到不同的节点,实现初步的负载均衡,当节点数量变化时,这种简单取模会导致数据大量迁移,生产环境中通常会使用一致性哈希算法,但取模依然是其基础组成部分。

验证码生成与随机数控制
在生成随机验证码时,我们往往希望数字落在特定范围内,虽然 random 模块提供了 randint,但在某些算法中,取模是控制随机数范围的有效手段。
import random # 生成 0-9 之间的随机数字 random_digit = random.randint(0, 100) % 10
这里,% 10 将 0-100 的大范围随机数映射到了 0-9 的小范围,确保了验证码的格式符合预期。
Python取模运算常见问题解答
Python中取模运算% x的具体用法是什么?
% x 是 Python 中的取模运算符,用于计算左操作数除以右操作数 x 后的余数,其基本语法为 a % x,返回值为 a 除以 x 的余数。10 % 3 的结果是 1,它广泛应用于奇偶判断、循环控制、数据分桶等场景。
Python取模运算与整除运算的区别在哪里?
取模运算 返回的是余数,而整除运算 返回的是商。10 // 3 的结果是 3,而 10 % 3 的结果是 1,两者结合可以还原除法的基本原理:被除数 = 商 除数 + 余数,在需要同时获取商和余数的场景中,可以使用 divmod(a, b) 函数,它同时返回商和余数。
Python中负数取模% x的结果为什么是正数?
Python 的取模运算遵循“向下取整”原则,即商向负无穷方向取整,当被除数为负数时,余数的符号与被除数保持一致,但为了确保数学上的同余性质,结果通常表现为正数(当除数为正时)。-7 % 3 中,商是 -3(向下取整),余数是 2,因为 -3 3 + 2 = -7,这种设计使得取模运算在时间计算和环形缓冲区中更加直观和一致。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/461281.html