GPU服务器显示错误通常由驱动冲突、显存溢出或硬件接触不良引起,首要排查步骤是检查NVIDIA驱动版本与CUDA环境的兼容性,并重置显示输出信号。
当你在机房或本地工作站面对黑屏、花屏或报错代码时,焦虑是难免的,这不仅仅是屏幕不亮的问题,更是算力中断的信号,对于依赖GPU进行深度学习训练或3D渲染的用户来说,每一次显示异常都意味着时间的浪费和进度的停滞,解决这个问题的核心逻辑在于“分层隔离”:先软后硬,先外后内,我们需要像剥洋葱一样,从操作系统层面的驱动配置,深入到硬件层面的物理连接,逐一排除故障点。
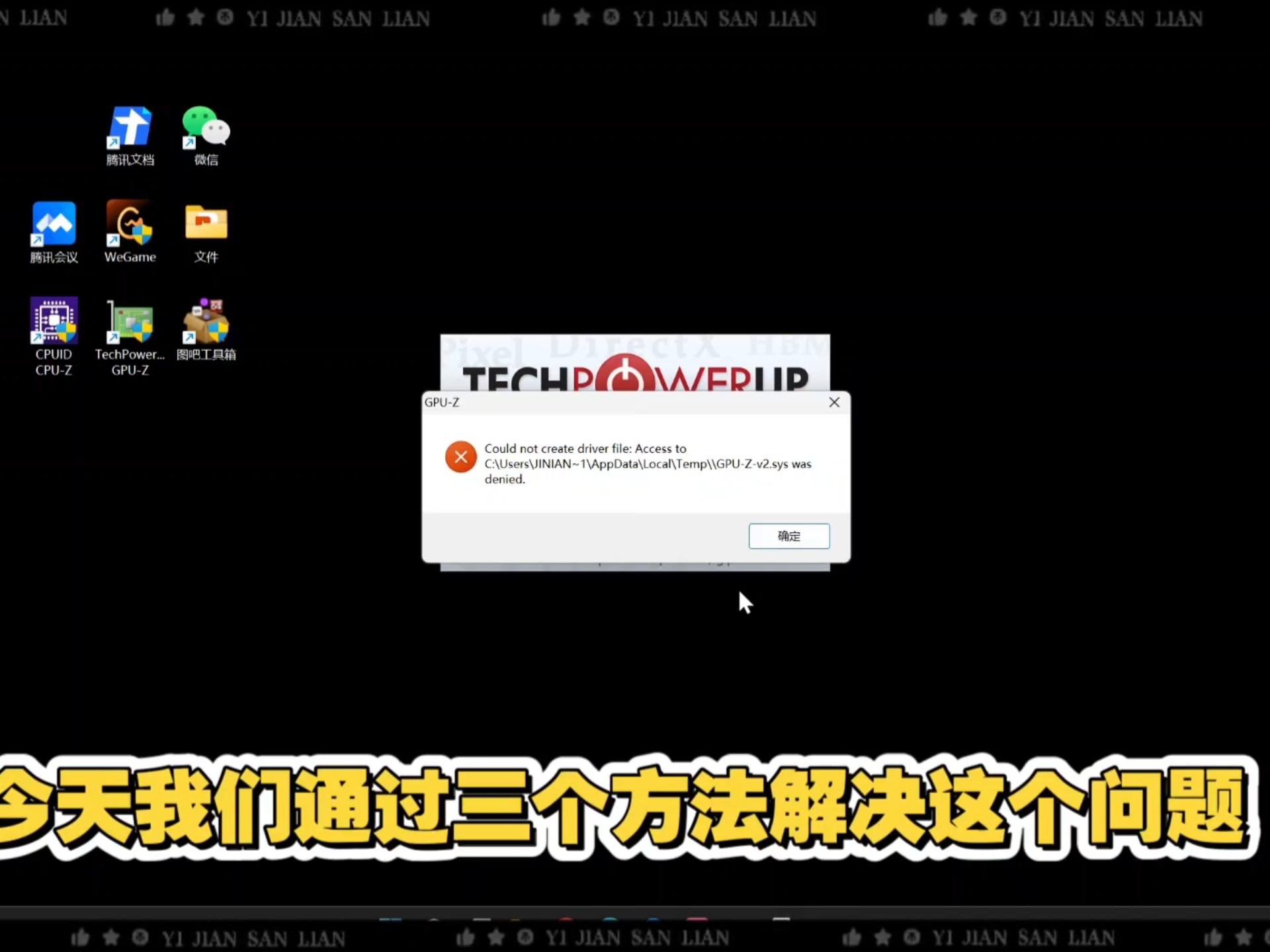
驱动与环境层面的深度排查
绝大多数所谓的“显示错误”,其实并非硬件损坏,而是软件生态中的“水土不服”,特别是在配置gpu服务器显示错误怎么解决的场景下,驱动程序的版本匹配度是决定性的因素。
驱动版本冲突的识别与修复
业内专家指出,NVIDIA驱动、CUDA Toolkit以及cuDNN三者之间存在严格的版本依赖关系,如果强行混用高版本驱动和低版本CUDA,或者在Windows与Linux环境下使用了错误的显示管理器,都会导致X Server无法启动,进而引发黑屏或报错。
操作路径如下:
- 卸载现有驱动:在Linux系统中,使用
sudo apt-get remove --purge nvidia-命令彻底清理残留文件,在Windows中,建议使用DDU(Display Driver Uninstaller)在安全模式下彻底清除。 - 核对兼容性矩阵:访问NVIDIA官方文档,确认你的GPU架构(如Ampere、Hopper)支持的驱动分支,对于A100或H100服务器,通常建议使用LTS(长期支持)分支而非最新Beta版。
- 重新安装:下载对应版本的.run文件或.exe安装包,安装时务必勾选“独立驱动安装”选项,避免安装包自带的Xorg配置覆盖原有设置。
CUDA环境变量的配置陷阱

很多时候,GPU本身工作正常,但应用程序无法调用GPU资源,表现为程序报错“CUDA out of memory”或“no CUDA-capable device is detected”,这往往是环境变量配置错误所致。
- PATH路径检查:确保
/usr/local/cuda/bin在系统PATH变量的最前端。 - LD_LIBRARY_PATH:在Linux中,必须将
/usr/local/cuda/lib64加入动态链接库路径,否则深度学习框架(如PyTorch、TensorFlow)在编译或运行时无法找到底层库文件。 - 验证命令:执行
nvidia-smi,如果能看到GPU列表和驱动版本,说明底层驱动正常;执行nvcc -V,确认编译器版本与应用需求一致。
硬件物理连接与信号链路诊断
当软件层面排查无误后,问题可能指向物理链路,服务器通常位于机房,通过KVM或远程管理卡(IPMI/iDRAC)进行监控,本地显示器的连接方式不同,故障点也截然不同。
本地直连显示器的信号问题
如果你直接在服务器主机上连接显示器,遇到gpu服务器显示错误代码的情况,首先要考虑的是信号握手失败。
- 接口匹配:确保使用DP(DisplayPort)或HDMI线连接至独立GPU的输出接口,而非主板上的集成显卡接口,服务器主板集成显卡通常被BIOS禁用或性能极低,无法驱动高分辨率屏幕。
- 线缆质量:DP线对屏蔽要求极高,劣质线材在传输高带宽信号时会出现丢包,导致闪烁或黑屏,建议更换为经过认证的DP 1.4或HDMI 2.1线缆。
- 分辨率刷新率:进入BIOS或安全模式,将分辨率降至1024×768,刷新率设为60Hz,如果能正常显示,再逐步提升,以排除显示器带宽不足的问题。
远程管理卡(IPMI/iDRAC)的独立性
对于企业级GPU服务器,本地显示器往往不是主要操作界面,IPMI或iDRAC卡拥有独立的BIOS和显示引擎,其显示状态与GPU驱动无关。

- 查看SEL日志:通过Web界面查看System Event Log(SEL),寻找“Video Controller Error”或“PCIe Bus Error”记录。
- 重置BMC:如果远程画面卡顿或黑屏,尝试通过电源按钮长按5-10秒强制重启BMC模块,这能解决大部分固件层面的显示假死问题。
显存溢出与计算负载导致的显示假死
这是一个容易被忽视的隐性故障,当GPU被深度学习任务占满显存,或者正在进行高负载的渲染计算时,负责图形输出的进程可能被调度器挂起,导致桌面环境无响应,看起来像是“显示错误”。
显存监控与资源释放
- 实时监控:使用
watch -n 1 nvidia-smi命令实时观察GPU内存占用,如果Used Memory接近Total Memory,且Compute Process列表中存在异常进程,说明资源已被耗尽。 - 强制清理:使用
nvidia-smi --gpu-reset尝试重置GPU状态,若无效,需找到占用显存的PID(进程ID),使用kill -9 <PID>强制终止。 - 避免碎片化:在训练大型模型时,启用梯度累积或混合精度训练(AMP),可以有效降低显存峰值,避免因为显存碎片化导致的显示服务崩溃。
硬件故障的最终判定与更换建议
如果经过上述所有软件和链路排查,问题依旧存在,且不同显示器、不同线缆均无法解决,那么硬件故障的可能性极大。
GPU硬件自检流程
- 重新插拔:断电后,将GPU从PCIe插槽中拔出,用橡皮擦清理金手指,重新安装并确保固定螺丝紧固,接触不良是服务器震动导致故障的主要原因。
- 交叉测试:将疑似故障的GPU安装到另一台正常的服务器中,或将正常的GPU安装到故障服务器中,这是判断故障源最准确的方法。
- 检查供电

:确认GPU的8pin或12pin供电接口是否插紧,电源供应器(PSU)的功率是否满足峰值需求,功率不足会导致GPU在高负载下电压不稳,引发显示异常。
何时需要寻求专业维修
如果交叉测试确认GPU本身故障,且服务器仍在保修期内,应立即联系厂商技术支持,对于gpu服务器显示错误维修费用,通常取决于故障部件,如果是驱动或配置问题,费用为零;如果是GPU核心或显存颗粒损坏,更换成本可能高达数千至数万元,准确的故障定位至关重要,避免不必要的硬件更换开销。
常见问题解答:gpu服务器显示错误
为什么nvidia-smi能识别GPU,但本地显示器黑屏?
这通常是因为X Server或Wayland显示管理器未能正确加载NVIDIA专有驱动,或者默认使用了开源的Nouveau驱动导致冲突,解决方案是禁用Nouveau驱动,安装官方专有驱动,并手动配置xorg.conf文件,指定使用NVIDIA驱动作为显示输出。
GPU服务器显示错误代码0x00000057是什么意思?
该错误代码通常与参数无效或配置不匹配有关,在GPU上下文中,它可能表示CUDA上下文创建失败,或者驱动程序与操作系统内核版本不兼容,建议检查系统日志(dmesg),确认是否有内核模块加载失败的记录,并尝试更新Linux内核至稳定版本。
服务器重启后GPU显示异常,如何快速恢复?
首先检查BIOS设置中是否保留了GPU的PCIe配置,进入系统后运行nvidia-smi,如果无法识别,尝试sudo modprobe nvidia加载驱动模块,若仍无效,检查电源线连接是否因震动松动,并确认电源供应器是否处于正常供电状态。
面对GPU服务器显示错误,保持冷静,遵循“软件驱动优先、硬件链路其次、负载监控辅助”的原则,绝大多数问题都能在短时间内得到解决,准确的环境配置和定期的硬件维护,是保障算力稳定运行的基石。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/419633.html











