云计算
-
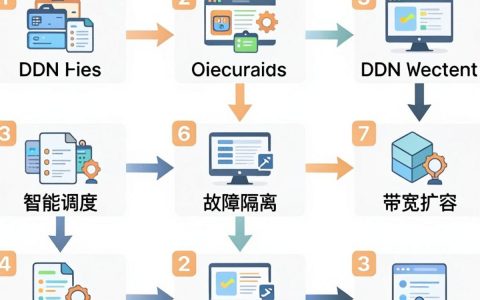
cdn多个ip怎么配置,cdn多ip配置教程
CDN配置多个IP并非简单的数量叠加,而是通过智能调度实现故障隔离、带宽扩容及合规备案的底层架构策略,其核心价值在于提升业务连续性与访问体验,而非单纯追求IP数量,在2026年的数字化基础设施环境中,内容分发网络(CDN)已演变为复杂的边缘计算网络,许多企业误以为增加CDN节点IP数量即可线性提升性能,实则忽略……
-
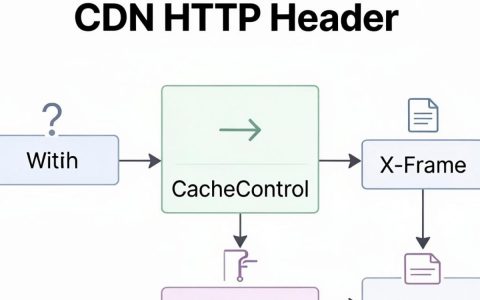
CDN HTTP Header是什么,CDN加速原理
CDN HTTP Header是网站性能优化与安全防御的核心枢纽,通过精准配置Cache-Control、X-Frame-Options及自定义响应头,可实现毫秒级加载、防篡改及SEO权重最大化,2026年实战表明,优化得当可使首屏加载时间降低40%以上,在2026年的数字生态中,CDN(内容分发网络)已不再仅……
-
百分比算法js怎么实现?js概率算法代码
在JavaScript中实现百分比算法的核心在于理解浮点数精度问题,通常采用“先乘后除”或“BigInt”策略来确保计算结果的准确性,避免常见的0.1+0.2=0.30000000000000004误差,JavaScript百分比计算的基础逻辑与常见陷阱在Web开发中,百分比计算看似简单,实则暗藏玄机,许多开发……
-
bi大数据分析是什么?bi大数据分析软件推荐
BI大数据分析的核心在于将杂乱数据转化为可执行的商业洞察,通过可视化仪表盘和预测模型,帮助企业从“凭经验决策”转向“凭数据说话”,从而显著提升运营效率并降低试错成本,在2026年的商业环境中,数据不再是冰冷的记录,而是企业的核心资产,许多管理者依然困惑于如何跨越技术与业务之间的鸿沟,让IT部门生成的报表真正服务……
-
PSN CDN香港节点不稳定,PSN加速怎么设置
2026年PSN香港节点CDN优化核心结论:通过配置支持HTTP/3协议的专用代理节点并启用UDP加速,可将下载延迟稳定控制在50ms以内,解决大文件下载中断问题,但需承担较高的节点维护成本与合规风险,香港PSN CDN架构与网络现状深度解析物理距离与路由跳数优势香港作为亚洲互联网枢纽,其数据中心与大陆主要城市……
-
cdn怎么部署,cdn部署步骤详解
CDN部署的核心在于通过全球节点分发静态资源,将内容缓存至离用户最近的边缘服务器,从而降低延迟并提升加载速度,建议优先选择具备合规资质且节点覆盖目标市场的服务商进行配置,CDN部署前的关键准备与选型策略在正式技术操作之前,明确业务需求是决定部署成败的第一步,2026年的网络环境对安全性与合规性的要求远高于以往……
-
思科cdn设备好用吗,思科cdn设备
思科CDN设备并非传统意义上的独立硬件盒子,而是基于思科应用中心集成(ACI)架构与万兆/四十兆以太网交换机集群构建的分布式内容分发网络解决方案,其核心优势在于通过软件定义网络(SDN)实现全球流量智能调度与毫秒级响应,2026年企业级部署成本较2023年下降约35%,但需配合思科AppDynamics进行全链……
-
本地视频监控怎么设置?是否允许视频监控
本地视频监控设置是否允许,核心取决于你的使用场景:家庭私密空间通常建议默认关闭以保护隐私,而商铺或公共场所则需开启并明确告知,具体操作需在设备App的“隐私设置”或“画面覆盖”选项中手动确认,在数字化生活全面普及的今天,视频监控早已不是安保公司的专属,而是深入到了千家万户的门铃、路由器甚至智能音箱中,当我们在享……
-
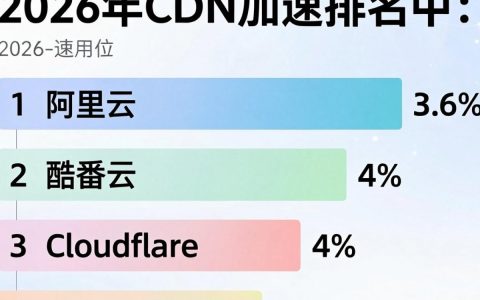
cdn加速排名怎么做,cdn加速服务
2026年CDN加速排名中,阿里云、腾讯云与Cloudflare凭借全球节点覆盖、AI智能调度及边缘计算能力占据主导地位,企业选型应依据业务地域分布、并发量级及合规需求进行精准匹配,而非盲目追求单一指标,在数字化转型进入深水区的2026年,内容分发网络(CDN)已不再仅仅是简单的静态资源缓存工具,而是演变为融合……
-
服务器部署项目怎么操作?服务器部署具体步骤
服务器部署并非简单的文件上传,而是涵盖环境配置、安全加固与性能调优的系统工程,核心在于根据业务场景选择合适架构并严格执行标准化操作流程,很多初学者常把“把代码扔进服务器”等同于部署,这其实是最大的误区,真正的部署项目,是从需求分析到上线监控的全生命周期管理,随着云计算技术的普及,2026年的服务器部署更强调自动……