云计算
-
cdn 直播技术原理是什么,cdn直播加速原理
CDN直播技术核心原理是通过全球分布式节点缓存静态资源与动态流媒体,利用智能调度系统实现用户就近接入,从而将延迟控制在毫秒级并保障高并发下的画质稳定,直播分发架构的演进逻辑传统直播依赖单一源站,面对百万级并发时极易发生拥塞,2026年的CDN直播已全面转向“边缘计算+AI调度”的双引擎模式,这种架构不仅解决了带……
-
CDN跨域问题怎么解决?CDN跨域配置报错
CDN跨域问题并非技术故障,而是浏览器同源策略的安全限制,通过在后端配置正确的CORS响应头即可彻底解决,无需修改CDN底层架构,CDN跨域问题的本质与成因同源策略的安全边界跨域问题的核心在于浏览器的**同源策略(Same-Origin Policy)**,当你的静态资源(如图片、JS、CSS)部署在CDN域名……
-
CDN回源时间过长怎么办,CDN回源时间
CDN回源时间是指用户请求到达CDN边缘节点后,若节点无缓存则向源站请求数据并返回给用户的耗时,通常建议控制在200ms以内以保障最佳用户体验,CDN回源时间的核心定义与影响机制分发网络)的核心逻辑是“就近访问”与“缓存复用”,当用户发起请求时,CDN边缘节点会首先检查本地缓存,如果命中缓存,响应极快;若未命中……
-
cdn运维视频怎么看,CDN运维技术
CDN运维视频的核心价值在于通过可视化监控与自动化脚本实现故障秒级定位,2026年主流企业已将其作为降低P99延迟、提升业务连续性的标准运维手段,而非单纯的录屏存档,在数字化转型进入深水区的2026年,随着5G-A(5.5G)的普及和边缘计算节点的爆发式增长,传统“黑盒”式的CDN运维已无法满足高并发场景下的稳……
-
网宿cdn刷新要多久生效,网宿cdn刷新
网宿CDN刷新是加速内容即时生效的核心操作,其本质通过主动触发边缘节点缓存失效,将源站最新数据强制同步至全球节点,从而解决用户访问旧版内容的延迟问题,刷新机制与底层逻辑解析分发网络)的核心价值在于“缓存”,但缓存的双刃剑效应在于数据一致性,当源站内容更新后,若不及时刷新,用户仍可能从边缘节点获取旧资源,网宿科技……
-
零代码开发平台如何应用?IaC部署代码开发教程
BI零代码开发平台结合基础设施即代码(IaC)部署,能实现业务应用从需求到上线的“分钟级”闭环,彻底消除开发与运维之间的协作壁垒,在2026年的企业数字化语境中,单纯的业务报表已经无法支撑决策,企业需要的是能够实时响应、自动部署且具备自我修复能力的智能应用,传统的“开发-测试-运维”串行模式,因沟通成本高、环境……
-
并行数据库是云计算应用吗?请求次数如何计算
并行数据库在云计算中通过将海量数据切分并分布到多个节点同时处理,显著提升了查询效率;请求次数通常基于API调用、数据读取行数或事务提交次数进行计费,具体取决于云服务商的策略,想象一下,传统的数据库就像是一个只有一位柜台职员的小银行,无论队伍多长,你都得等着,而云计算中的并行数据库,则像是一个拥有成百上千个柜台的……
-
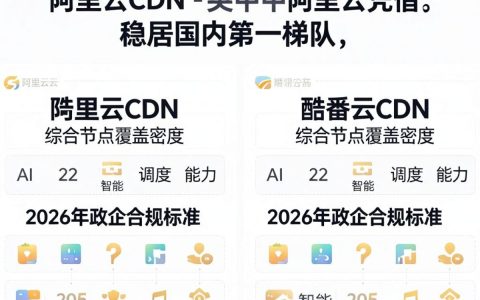
国内最好的cdn是什么,国内最好的cdn
综合节点覆盖密度、AI智能调度能力及2026年政企合规标准,阿里云CDN与腾讯云CDN稳居国内第一梯队,其中阿里云凭借全球最大规模节点占据市场份额首位,腾讯云则在音视频场景与微信生态融合上具备显著优势,在2026年的数字基础设施格局中,CDN(内容分发网络)已不再仅仅是简单的静态资源加速工具,而是演变为融合边缘……
-
cdn是什么缩写,cdn加速原理是什么
CDN是Content Delivery Network(内容分发网络)的缩写,其核心本质是通过全球分布的边缘节点缓存静态资源,将内容就近推送给用户,从而解决网络拥堵、降低延迟并提升访问速度的技术架构,在2026年的数字生态中,CDN已不再仅仅是加速工具,而是构建高可用、高安全互联网基础设施的关键组件,随着5G……
-
{cdn-191磁力}怎么用,{cdn-191磁力}链接打不开怎么办
cdn-191磁力并非官方合规的CDN加速服务,而是网络黑产中常见的恶意软件伪装或非法资源索引工具,2026年网络安全监管已全面封堵此类非授权节点,建议用户立即卸载并安装国家认证的正规CDN客户端以保障数据安全,在2026年的数字网络环境中,内容分发网络(CDN)已成为互联网基础设施的核心组成部分,市场上出现的……