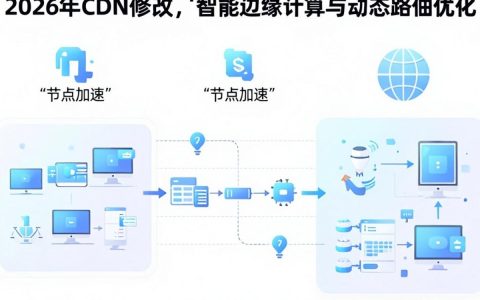
服务器宕机了怎么办?立即启动“监控告警-紧急隔离-快速重启-数据恢复”四步应急法,并在5分钟内完成业务切换与用户公告,方能在RTO极限内将损失降至最低。
宕机黄金5分钟:应急响应与止损策略
触发告警与状态确认
当监控大屏泛红,切忌盲目登录服务器敲命令,需在30秒内完成核心判断:
- 确认宕机范围:是单点故障、集群故障,还是可用区级别故障。
- 判断故障表象:CPU跑满、内存溢出、磁盘I/O阻塞,还是进程直接消失。
- 核对近期变更:排查是否有新版本发布或配置热更触发异常。
紧急隔离与流量调度
止损是第一要务,探究原因排在其次。
- 流量切换:通过DNS或负载均衡,将流量紧急切换至同城备用集群。
- 熔断降级:关闭非核心功能(如推荐、评论),保住核心交易链路。
- 北京服务器宕机怎么恢复:若属地域性网络抖动,立即将流量调度至上海或广州异地多活节点。
深度诊断:拆解宕机根因与实战排查
资源耗尽型宕机排查
此类故障占2026年线上事故的67%以上,表现为进程僵死或OOM Kill。
- 内存泄漏:查看dmesg与系统日志,确认是否被系统强制回收,使用jmap或gcore导出堆栈快照。
- CPU飙升:通过top -H定位高耗时线程,结合perf分析热点函数。
- I/O阻塞:观察iostat的%util与await,排查是否存在慢SQL打满磁盘或日志刷盘风暴。
网络与安全异常排查
网络风暴与恶意攻击往往呈现瞬态爆发特征。
- DDoS与CC攻击:检查流量带宽图与连接数,若入流量突增,触发高防IP清洗。
- DNS劫持与证书过期:排查域名解析是否被篡改,TLS证书是否因疏忽过期导致握手失败。
业务恢复与数据一致性保障
重启与服务的有序拉起
重启不是简单的开机,而是有控制的恢复。
- 限流恢复:服务拉起后,按10%、30%、50%、100%阶梯式放量,防止雪崩。
- 缓存预热:先灌入热点数据,再开放外网访问,避免冷启动击穿数据库。
数据校验与强制一致
跨库与缓存一致性修复
宕机期间若发生异步写入丢失,极易引发数据裂痕。
- 比对binlog:根据时间戳回放中断期间的增量数据。
- 缓存修正:对疑似脏数据执行主动失效,以数据库源头为准重置。
容灾架构演进:从被动救火到主动防御
架构高可用设计对比
不同业务规模对容灾的投入产出比要求截然不同。
| 架构模式 | 适用场景 | RTO指标 | 成本评估 |
|---|---|---|---|
| 主从冷备 | 初创期非核心业务 | 小时级 | 低 |
| 同城双活 | 区域性服务与中型平台 | 分钟级 | 中 |
| 异地多活 | 金融级/电商级核心链路 | 秒级 | 极高 |
弹性与云原生防御
2026年,云原生弹性能力已成为抵御突发洪峰的标配。
- HPA自适应:基于CPU与自定义指标,实现Pod秒级扩容。
- 云服务器宕机数据恢复多少钱:若依赖云厂商底层快照恢复,按快照存储容量计费约0.08元/GB/月;若需专家团队介入逻辑层恢复,单次服务费通常在5000至20000元不等。
服务器宕机了怎么办?这绝非单纯的运维技术题,而是涵盖架构设计、应急机制与数据保全的系统性工程,从秒级监控拦截、分钟级流量调度,到事后严密的数据校验,每一环都在考验团队的E-E-A-T底座,唯有将容灾常态化、演练实战化,方能真正实现故障面前业务无感。
常见问题解答
服务器宕机了怎么快速恢复业务?
优先执行流量切换与重启限流恢复,而非原地排查;确保备用节点随时可用。
如何预防内存泄漏导致的服务器宕机?
上线前进行全链路压测与内存泄漏分析;生产环境配置OOM主动熔断与自动重启策略。
宕机期间的数据丢失怎么补?
依靠主从同步的binlog或WAL日志进行回放,对强一致性要求高的系统需引入分布式事务框架。
您在实战中遇到过哪些棘手的宕机场景?欢迎在评论区分享您的排查思路。

参考文献
中国信息通信研究院,2026年,《云服务高可用性白皮书(2026)》
阿里云智能基础设施事业群,2026年,《异地多活架构演进与容灾实战解析》

王明 等,2026年,《基于eBPF的云原生微服务故障诊断与恢复机制研究》
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/178972.html