构成数据库的最小单位是字段(Field),也常被称为列(Column)或属性,它是存储具体数据值的原子单元,不可再分。
当我们谈论数据库时,往往容易陷入宏观架构的迷雾,比如服务器集群、分布式存储或者复杂的SQL语句,但如果把视角缩小到极致,你会发现所有庞杂的信息系统,最终都建立在一个个微小的“格子”之上,这个格子就是字段,理解字段,就是理解数据世界的基石。
字段与记录的关系:从原子到分子
在关系型数据库中,数据是以表的形式存在的,你可以把一张表想象成一个Excel表格,或者一本通讯录,在这个结构中,字段和记录(Record)是两个核心概念,它们共同构成了数据的骨架。
字段的定义与角色
字段定义了数据的“类型”和“含义”,在创建表时,你必须为每一列指定数据类型,比如整数、字符串、日期或布尔值,这就像是给每个格子贴上了标签,告诉数据库这个格子里只能装什么。
业内专家指出,字段的严格定义是保证数据一致性的第一道防线,如果字段被定义为“整数”,那么试图存入“文本”的操作就会直接报错,从而避免了脏数据的产生,这种约束机制在金融交易、医疗记录等对准确性要求极高的场景中至关重要。
记录的组织逻辑
如果说字段是列,那么记录就是行,一条记录由多个字段的值组合而成,代表一个完整的信息实体,在“员工信息表”中,一行数据可能包含“姓名”、“工号”、“入职日期”等字段的值。
实操建议:如何设计字段结构
在设计数据库时,遵循“原子性”原则是关键,不要在一个字段里存储多个信息,不要建立一个名为“联系方式”的字段,里面同时存放电话和邮箱,用逗号分隔。
正确的做法是拆分:
- 建立
phone_number字段,类型为字符串。 - 建立
email_address字段,类型为字符串。
这种拆分不仅便于查询,还能避免后续数据清洗的噩梦,当需要筛选所有拥有邮箱的员工时,如果数据混在一起,你将不得不使用复杂的正则表达式;而拆分后,只需简单的WHERE email_address IS NOT NULL即可。
字段类型详解:不同场景的选择策略
字段的核心属性是其数据类型,选择合适的类型不仅能节省存储空间,还能显著提升查询效率,不同的数据库系统(如MySQL、PostgreSQL、Oracle)在类型命名上可能略有差异,但核心逻辑相通。
数值型字段:精度与范围的权衡

数值型字段主要用于存储数字,根据需求不同,可分为整数型和浮点型。
- 整数型:适用于ID、数量、年龄等没有小数的场景。
TINYINT:占用1字节,范围-128到127,适合状态码(0/1)。INT:占用4字节,范围约21亿,适合大多数ID和计数。BIGINT:占用8字节,适合超大规模数据的主键或日志ID。
- 浮点型:适用于科学计算、货币(需谨慎)等需要小数的场景。
FLOAT:单精度,占用4字节,精度较低。DOUBLE:双精度,占用8字节,精度较高。
避坑指南:货币存储的最佳实践
在处理金额时,许多初学者会使用FLOAT或DOUBLE,这是极其危险的,由于二进制浮点数的精度问题,1 + 0.2可能不等于3。
对于涉及金钱的业务,业内共识认为应使用定点数类型(如MySQL的DECIMAL)或将金额转换为最小货币单位(如分)存储为整数,10.50元存储为1050,类型为INT,这样既避免了精度丢失,又提高了查询速度。
字符串型字段:长度与编码的艺术
字符串类型用于存储文本,选择哪种类型取决于数据的长度和可变性。
- CHAR:定长字符串,如果指定长度为10,存入”abc”也会占用10个字符的空间,适合长度固定的数据,如身份证号、MD5哈希值。
- VARCHAR:变长字符串,只占用实际长度加1-2字节的长度标识,适合长度不确定的数据,如用户名、评论。
性能对比:CHAR vs VARCHAR
| 特性 | CHAR | VARCHAR |
|---|---|---|
| 存储方式 | 固定长度,不足补空格 | 变长,记录实际长度 |
| 查询速度 | 较快,无需计算偏移量 | 稍慢,需解析长度头 |
| 空间利用 | 浪费空间(若数据短) | 节省空间 |
| 适用场景 | 固定长度数据(如邮编) |
可变长度数据(如姓名) |

据工信部相关技术规范建议,在现代SSD存储成本较低的情况下,空间节省不再是首要考量,查询性能和解耦复杂度更为重要,除非有明确的性能瓶颈,否则优先选择VARCHAR以保持灵活性。
日期与时间型字段:时区与格式的规范
时间数据看似简单,实则暗藏玄机,常见的类型包括DATE、TIME、DATETIME和TIMESTAMP。
DATETIME:占用8字节,范围大,但不包含时区信息。TIMESTAMP:占用4字节,范围较小,但自动关联服务器时区。
国际化应用中的时区陷阱
如果你的应用面向全球用户,务必使用TIMESTAMP或存储UTC时间。DATETIME存储的是“裸时间”,不包含时区信息,当用户在北京查看“2026-01-01 00:00:00”时,如果服务器在纽约,这个时间可能已经过去了24小时。
操作路径建议:
- 数据库层统一使用
TIMESTAMP或DATETIME存储UTC时间。 - 应用层在展示前,根据用户本地时区进行转换。
- 避免在数据库中使用时区敏感函数,除非你完全掌控服务器配置。
字段约束:数据的守门员
仅有数据类型是不够的,还需要通过约束来确保数据的完整性和有效性,约束是字段级别的规则,强制执行业务逻辑。
常用约束类型解析
- NOT NULL:字段不能为空,这是最基本也是最重要的约束,确保每条记录都有核心信息。
- UNIQUE:字段值必须唯一,适用于邮箱、手机号等需要唯一标识的信息。
- PRIMARY KEY:主键约束,唯一标识一条记录,通常也是NOT NULL和UNIQUE的组合。
- FOREIGN KEY:外键约束,建立表与表之间的关系,确保引用的完整性,订单表中的
user_id必须存在于用户表中。
外键的性能权衡
虽然外键能保证数据一致性,但在高并发写入场景下,它可能成为性能瓶颈,因为每次插入或更新都需要检查关联表。
业内专家指出,对于大型互联网应用,通常建议在应用层进行逻辑校验,而非依赖数据库外键,这样可以解耦系统,提高写入吞吐量,但在中小规模系统或数据一致性要求极高的金融系统中,外键仍是推荐做法。
字段设计的实战原则
理解了字段的基本概念和类型后,我们需要将这些知识应用到实际设计中,以下是经过验证的实操原则。

范式与反范式的平衡
数据库设计通常遵循第三范式(3NF),即消除传递依赖,减少数据冗余,这意味着将信息拆分成多个表,通过外键关联。
过度规范化会导致查询时需要大量的JOIN操作,影响性能,在读取频繁的场景下,可以适当反规范化,将常用数据冗余存储在主表中。
具体场景示例:电商订单系统
在订单表中,是否应该冗余存储商品名称?
- 范式做法:只存储
product_id,查询时JOIN商品表获取名称。 - 反范式做法:冗余存储
product_name和product_price。
考虑到订单一旦生成,商品名称和价格通常不应改变(即使商品表更新了历史订单的价格),冗余存储可以简化查询,提高列表页加载速度,但需注意,当商品改名时,历史订单的名称不会自动更新,这可能引发争议,通常只冗余名称,价格通过快照机制在下单时锁定。
索引与字段的配合
字段是索引的基础,为经常用于查询、排序、分组的字段建立索引,可以大幅提升性能,但索引并非越多越好,它会增加写入成本和存储空间。
操作路径建议:
- 分析查询日志,找出高频查询字段。
- 为这些字段创建单列索引或复合索引。
- 避免在索引字段上进行函数运算,否则索引失效。
常见问题解答
数据库最小单位是字段还是字节?
从物理存储角度看,数据最终存储在磁盘的字节(Byte)中;但从逻辑结构和用户交互角度看,构成数据库的最小语义单位是字段(Field),字段是业务逻辑层面的最小单元,而字节是物理层面的最小单元,在数据库设计和SQL操作中,我们关注的是字段。
字段长度限制是多少?
字段长度限制取决于数据类型和数据库引擎,MySQL的VARCHAR最大长度通常为65,535字节,但受限于行最大长度(约65KB)和字符集编码。TEXT类型可以存储长达4GB的数据,在实际设计中,应根据业务需求合理设定,避免盲目使用最大长度,以免浪费内存和I/O资源。
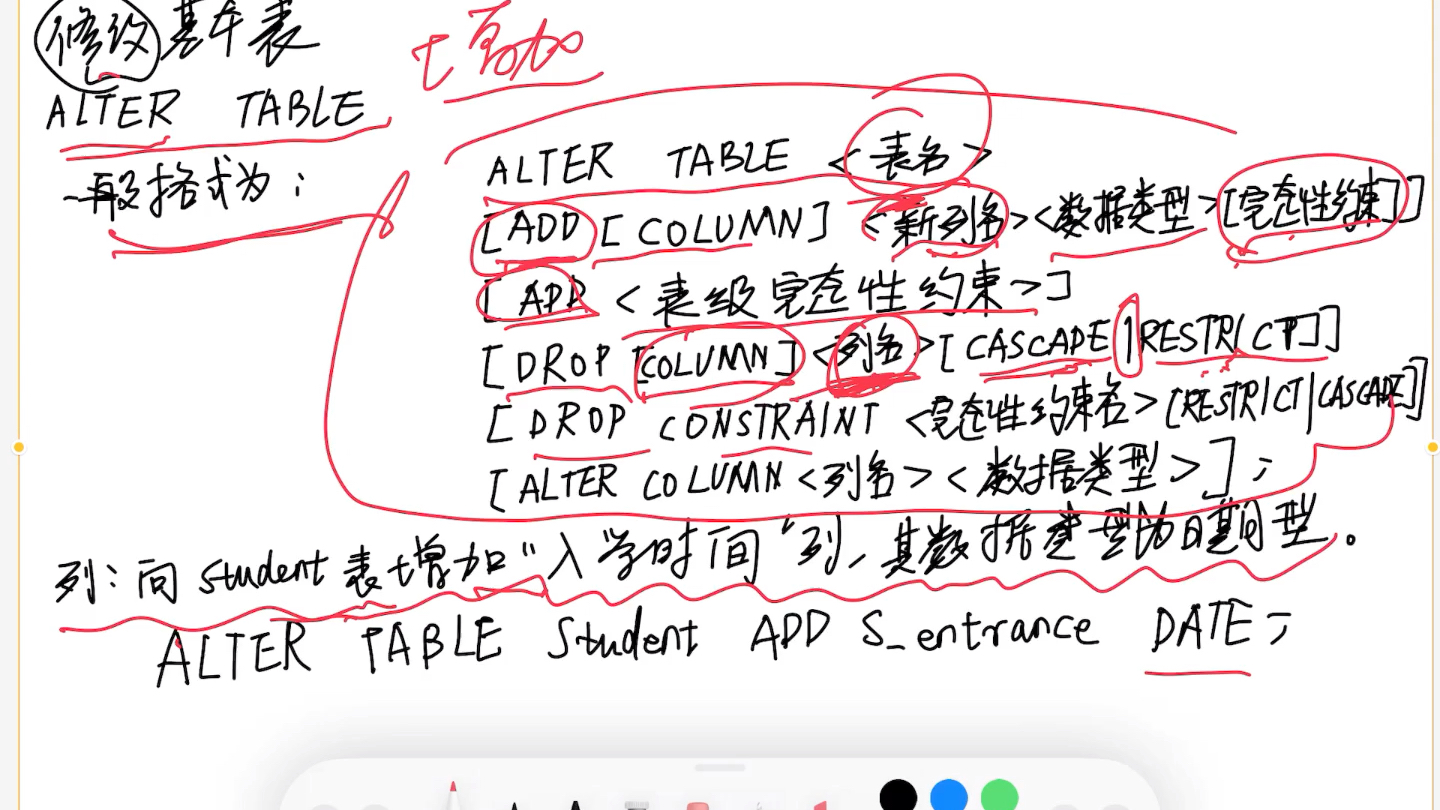
如何修改已有字段的数据类型?
修改字段类型需要使用ALTER TABLE语句。ALTER TABLE table_name MODIFY COLUMN column_name NEW_TYPE;,操作前务必备份数据,因为类型转换可能导致数据丢失或截断,特别是从大范围类型转换为小范围类型时,建议在低峰期操作,并先在测试环境验证。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/204222.html











