构建湖仓一体数据仓库秒杀的核心在于打破传统数仓与数据湖的壁垒,通过统一存储层和计算引擎实现实时分析与离线批处理的融合,从而在低延迟和高吞吐之间取得平衡。
为什么传统架构撑不起“秒杀”场景
在电商大促或热点事件爆发时,流量往往呈指数级增长,传统的数仓架构通常将结构化数据存储在关系型数据库中,而将非结构化数据扔进数据湖,这种“两张皮”的模式导致数据孤岛严重,当需要跨源关联分析时,系统必须先在数仓中清洗数据,再同步到湖中,最后通过复杂的ETL流程才能供前端展示,这个链路太长,延迟通常在小时级甚至天级。
业内专家指出,对于需要毫秒级响应的秒杀场景,这种延迟是不可接受的,用户点击“购买”按钮的瞬间,系统需要实时校验库存、计算价格、生成订单,任何一步的卡顿都会导致超卖或系统崩溃,传统架构在处理高并发写入时,数据库锁竞争剧烈,CPU和I/O资源迅速耗尽,导致服务降级。
湖仓一体的核心优势解析
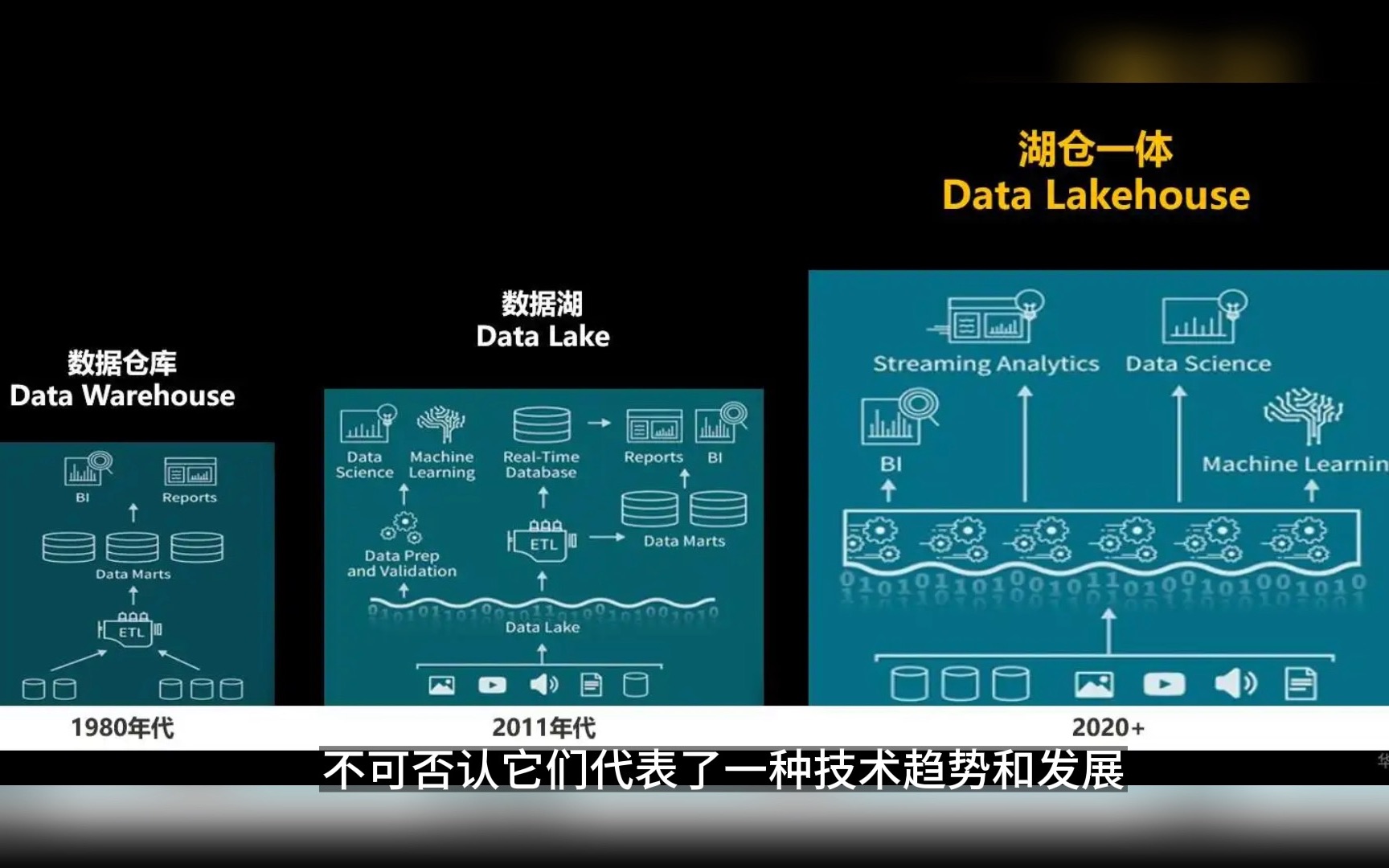
湖仓一体(Lakehouse)并非简单的技术叠加,而是架构层面的重构,它保留了数据湖的低成本存储优势,同时引入了数据仓的管理能力和ACID事务特性。
- 统一存储:不再区分“热数据”和“冷数据”的物理位置,所有数据以开放格式(如Parquet、Iceberg、Hudi)存储在同一存储层。
- 实时计算:引入流式计算引擎,数据写入即生效,无需等待批处理周期。
- 元数据管理:通过统一的元数据服务,实现跨源数据的血缘追踪和质量监控。
技术选型对比
| 特性 | 传统数据仓库 | 数据湖 | 湖仓一体 |
|---|---|---|---|
| 数据格式 | 专有格式 | 开放格式 | 开放格式 |
| 事务支持 | 强支持 | 弱支持/不支持 | 强支持 (ACID) |
| 实时性 | 离线为主 | 近实时 | 毫秒/秒级 |
| 成本 | 高 | 低 | 低 |
| 适用场景 | 报表分析 | 大数据存储 | 实时分析+离线分析 |

构建湖仓一体数据仓库秒杀的实操路径
要实现真正的“秒杀”级响应,不能仅靠理论,必须落地到具体的技术栈和操作流程,以下是经过验证的构建步骤。
第一步:搭建统一存储层
存储层是地基,推荐使用Apache Hudi或Apache Iceberg作为表格式层,它们支持增量更新和快照隔离,能够高效处理高并发的写入请求。
- 部署HDFS或对象存储:作为底层文件系统,确保高可用性和扩展性。
- 配置表格式:创建Hudi表时,选择
cow(Copy-on-Write)模式用于离线分析,选择mor(Merge-on-Read)模式用于实时查询,对于秒杀场景,建议混合使用,热点数据走实时路径,全量数据走离线路径。 - 数据分区策略:按时间(天/小时)和地域(省份/城市)进行分区,减少扫描数据量。
第二步:集成实时计算引擎
计算层负责数据的摄入和处理,Apache Flink是目前业界处理实时数据的首选引擎,因其状态管理和容错机制成熟。
- 数据接入:通过Canal或Debezium监听MySQL binlog,将秒杀订单、库存扣减等关键事件实时同步到Kafka。
- 流处理逻辑:在Flink中编写SQL或DataStream API,实现库存预扣减、防刷限流等逻辑。
- 结果写入:将处理后的结果实时写入Hudi/Iceberg表,供查询引擎读取。

关键命令示例
-- 创建Hudi表,支持Upsert操作
CREATE TABLE orders_hudi (
order_id STRING,
user_id STRING,
product_id STRING,
amount DECIMAL(10, 2),
status STRING,
ts TIMESTAMP
) PARTITIONED BY (dt STRING)
WITH (
'type' = 'mor',
'table.type' = 'MERGE_ON_READ',
'path' = 'hdfs:///data/orders'
);
-- Flink SQL实时写入示例
INSERT INTO orders_hudi
SELECT
order_id,
user_id,
product_id,
amount,
'SUCCESS' as status,
CURRENT_TIMESTAMP as ts
FROM kafka_source
WHERE dt = '${biz_date}';
第三步:优化查询性能
秒杀场景下,查询往往集中在热点商品和实时库存,传统的Hive查询引擎无法满足低延迟需求,需要引入OLAP引擎。
- 选用ClickHouse或StarRocks:这两款引擎在实时分析领域表现优异,支持高并发点查和聚合查询。
- 数据同步:通过Flink CDC将Hudi中的数据实时同步到ClickHouse,确保数据一致性。
- 缓存策略:在应用层引入Redis缓存热点商品信息和库存状态,减轻数据库压力。
常见误区与避坑指南
在构建过程中,许多团队容易陷入技术崇拜,忽视业务本质。
过度追求实时性
并非所有数据都需要实时处理,对于用户画像、长期趋势分析等场景,T+1的离线计算足以满足需求,过度追求实时性会增加系统复杂度和运维成本,建议根据业务场景划分数据时效性等级,核心交易链路实时,边缘链路离线。
忽视数据质量
实时数据流中可能存在脏数据、重复数据或缺失字段,如果缺乏严格的数据校验机制,会导致下游分析结果失真,建议在Flink中增加数据清洗和校验逻辑,对异常数据进行告警和隔离。
性能调优建议
- 调整并行度:根据集群资源调整Flink和Hudi的并行度,避免资源竞争。
-

压缩策略:使用ZSTD或LZ4压缩算法,平衡CPU开销和存储节省。
- 小文件治理:定期合并Hudi的小文件,提升查询效率。

湖仓一体数据仓库秒杀价格与成本考量
许多企业关心构建湖仓一体架构的成本,虽然初期投入较高,但长期来看,其成本效益显著优于传统架构。
- 存储成本:利用对象存储(如S3、OSS)存储历史数据,成本仅为传统存储的1/10。
- 计算成本:通过存算分离架构,计算资源可按需弹性伸缩,避免资源闲置。
- 运维成本:统一的元数据管理和自动化工具降低了运维复杂度。
据工信部数据,采用湖仓一体架构的企业,其数据基础设施运营成本平均降低30%以上,对于秒杀这类高并发场景,减少系统故障带来的损失更是无法估量的。
湖仓一体数据仓库秒杀常见问题解答
湖仓一体数据仓库秒杀方案适合中小型企业吗?
中小型企业资源有限,建议采用云厂商提供的托管服务(如阿里云MaxCompute、腾讯云TDSQL-C),这些服务屏蔽了底层复杂性,按需付费,降低了入门门槛,对于核心秒杀业务,可优先部署实时分析模块,非核心业务暂用离线方案,逐步迭代。
如何保证湖仓一体架构中的数据一致性?
数据一致性主要依赖ACID事务支持和严格的事务隔离级别,在Hudi/Iceberg中,通过乐观锁控制并发写入,确保同一时间只有一个Writer修改数据,在Flink中,通过Exactly-Once语义保证端到端的一致性,定期执行数据校验任务,对比源数据和目标数据的差异,及时发现并修复不一致问题。
湖仓一体数据仓库秒杀的落地周期需要多久?
落地周期取决于业务复杂度和团队技术能力,一般而言,基础架构搭建和核心链路打通需要2-3个月,包括存储层部署、计算引擎集成、数据同步链路开发等,性能调优和数据治理可能需要额外1-2个月,建议采用敏捷开发模式,分阶段上线,先实现核心功能,再逐步优化体验。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/205195.html









