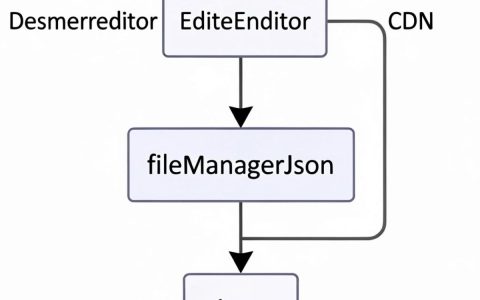
动态文档是现代数据中台的核心能力之一,它彻底改变了传统静态数据字典和文档的管理模式,其本质是利用自动化技术,将数据资产(库表、字段、API、指标、模型等)的结构化元数据与其使用说明、业务含义、血缘关系、质量状态等信息实时、动态地关联、生成并呈现出来,它并非一份“写死”的PDF或Word文件,而是一个与数据资产本身紧密耦合、随其变化而自动更新的“活”知识库。

核心价值:破解数据认知与协作困境
国内企业在数据应用深化过程中,普遍面临数据“找不到、看不懂、不敢用”的痛点,动态文档正是解决这些问题的利器:
- 提升数据发现效率与准确性: 用户可通过关键词、业务标签、分类等快速检索所需数据资产,查看其最新结构和描述,避免在过时文档或海量表中盲目摸索。
- 降低数据理解门槛: 提供清晰、统一的业务术语解释、计算逻辑说明、数据来源(血缘)及质量评估,让业务人员、分析师、开发者都能快速理解数据含义和可信度。
- 保障数据一致性,促进协作: 作为唯一的、权威的数据描述源,确保不同团队对同一数据的理解一致,减少沟通歧义,提升跨部门协作效率。
- 支撑数据治理落地: 是数据标准、数据质量规则、数据安全等级等治理要求的重要承载和宣贯渠道,使治理成果可视化、可触达。
- 加速数据价值释放: 通过降低数据使用门槛和提升信任度,让更多角色能快速、自信地利用数据进行决策、分析和应用开发。
国内应用现状与核心挑战
国内领先企业在数据中台建设中,已普遍认识到动态文档(常以“数据目录”、“数据地图”、“元数据中心”等形式体现)的重要性,并积极投入建设,实践中仍面临显著挑战:
- 自动化程度不足: 许多文档仍需人工录入维护,耗时耗力且易与实际脱节,违背“动态”初衷。
- 业务与技术描述割裂: 技术元数据(如字段类型、长度)与业务元数据(如业务定义、计算口径)分离,缺乏有效融合,导致业务用户理解困难。
- 血缘与影响分析薄弱: 数据血缘关系(数据从源头到消费的流转路径)和影响分析(下游依赖)的覆盖度和可视化不足,难以评估变更影响。
- 用户活跃度与价值闭环: 文档建好后,用户活跃度低,未形成“查阅-反馈-改进”的闭环,价值未充分发挥。
- 与开发运维流程脱节: 未有效嵌入数据开发、模型设计、数据测试、发布上线等流程,导致文档更新滞后。
构建有效动态文档的核心技术架构与解决方案
要解决上述挑战,构建真正“动态”且高价值的文档系统,需依托坚实的技术架构和专业的解决方案:

-
自动化元数据采集与发现引擎:
- 深度集成: 无缝对接主流数据库(MySQL, Oracle, Hive, Spark等)、数仓工具、BI平台、API网关、数据开发平台等。
- 全链路扫描: 自动扫描抽取库表结构、字段、视图、存储过程、ETL任务、API接口、指标定义、数据模型等技术元数据。
- 智能解析: 利用自然语言处理(NLP)等技术,尝试从代码注释、任务名称等提取初步业务语义。
-
统一元数据模型与存储:
- 标准化建模: 定义统一的核心元模型(如资产类型、属性、关系),兼容不同来源的元数据。
- 集中存储与管理: 建立企业级元数据中心,作为所有元数据的唯一权威存储库。
-
智能增强与关联:
- 业务术语关联: 建立技术元数据(字段)与企业业务术语库的映射关系,赋予技术字段明确的业务含义。
- 自动血缘解析: 通过解析SQL脚本、ETL任务日志、API调用链等,自动构建数据血缘图谱,清晰展示数据源、加工过程和消费端。
- 质量与SLA集成: 关联数据质量检测结果、SLA达标情况,在文档中直观展示数据的可信度状态。
- 机器学习辅助: 应用机器学习推荐相似资产、自动生成字段描述初稿、识别潜在的数据质量问题关联。
-
协作化知识管理与反馈闭环:
- 便捷编辑与评论: 提供用户友好的界面,允许业务专家补充业务描述、使用示例、注意事项等,支持评论、提问。
- 版本控制与审计: 记录元数据和描述的变更历史,确保可追溯和合规审计。
- 通知与订阅: 当关注的资产发生变更(结构、描述、质量状态)时,自动通知订阅用户。
-
用户友好的搜索与展示门户:
- 智能搜索: 支持关键词、标签、业务术语、数据域等多维度精准搜索,提供联想、排序、过滤功能。
- 可视化图谱: 以图形化方式直观展示数据血缘关系、上下游影响。
- 场景化视图: 为不同角色(业务人员、分析师、开发者、治理员)提供定制化的信息展示视图。
- API集成: 提供API供其他系统(如BI工具、数据开发平台)嵌入调用元数据信息。
实施路径与关键成功要素

- 顶层规划,价值驱动: 明确动态文档的核心目标(如提升找数效率、降低沟通成本、支撑治理合规),优先覆盖高价值、高使用率的数据域。
- 技术选型与集成: 选择成熟的数据目录/元数据管理产品(如国内厂商的DataPipeline、奇点云、数新网络等方案,或开源方案如Apache Atlas/Amundsen),或基于开源组件自建,重点评估其自动化采集能力、扩展性和集成能力。
- 建立协同维护机制: 明确数据Owner(技术Owner与业务Owner)职责,将元数据维护(尤其是业务描述)嵌入数据开发、模型设计、上线评审流程。
- 推广与运营: 持续培训用户,展示成功用例,建立反馈奖励机制,将文档使用情况纳入数据治理考核指标。
- 持续迭代: 根据用户反馈和使用数据,不断优化搜索体验、展示内容、自动化能力。
案例价值:从“成本中心”到“效率引擎”
国内某大型零售企业通过落地动态数据文档系统:
- 数据分析师 找数时间平均缩短60%,新入职员工熟悉数据周期从数周降至几天。
- 业务部门 对核心指标的解读达成一致,报表需求沟通效率显著提升。
- 数据开发团队 在修改表结构前能清晰评估影响范围,减少线上事故。
- 数据治理团队 能有效跟踪数据标准的执行情况和数据质量问题的根因。
未来趋势:智能化、场景化、平民化
随着AI技术的深入应用,动态文档将更加智能化:自动生成更准确的业务描述、预测数据变更影响、主动推荐相关资产,它将更加场景化,深度嵌入BI分析、数据开发、机器学习等具体工作流,提供“恰好所需”的信息,最终目标是让动态文档成为企业内人人可用的数据“说明书”,真正实现数据的平民化应用。
您的数据资产“活”起来了吗? 当前团队在查找和理解关键业务数据时,面临的最大障碍是什么?是文档缺失、信息过时,还是业务口径难以统一?欢迎分享您遇到的痛点或成功经验,共同探讨如何让数据知识在企业内高效流动!
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/21100.html