归并排序在JavaScript中的核心优势在于其稳定的O(n log n)时间复杂度,特别适合处理大规模数据排序或需要保持相等元素相对顺序的场景,尽管其空间复杂度为O(n)是主要权衡点。
为什么JavaScript开发者选择归并排序
在算法面试和实际工程开发中,js归并排序实现原理是一个绕不开的话题,很多开发者在初次接触时,往往会被其“分治”思想吸引,但在深入理解后,会发现它在特定场景下的不可替代性,与快速排序相比,归并排序最大的特点不是速度上的绝对领先,而是稳定性。
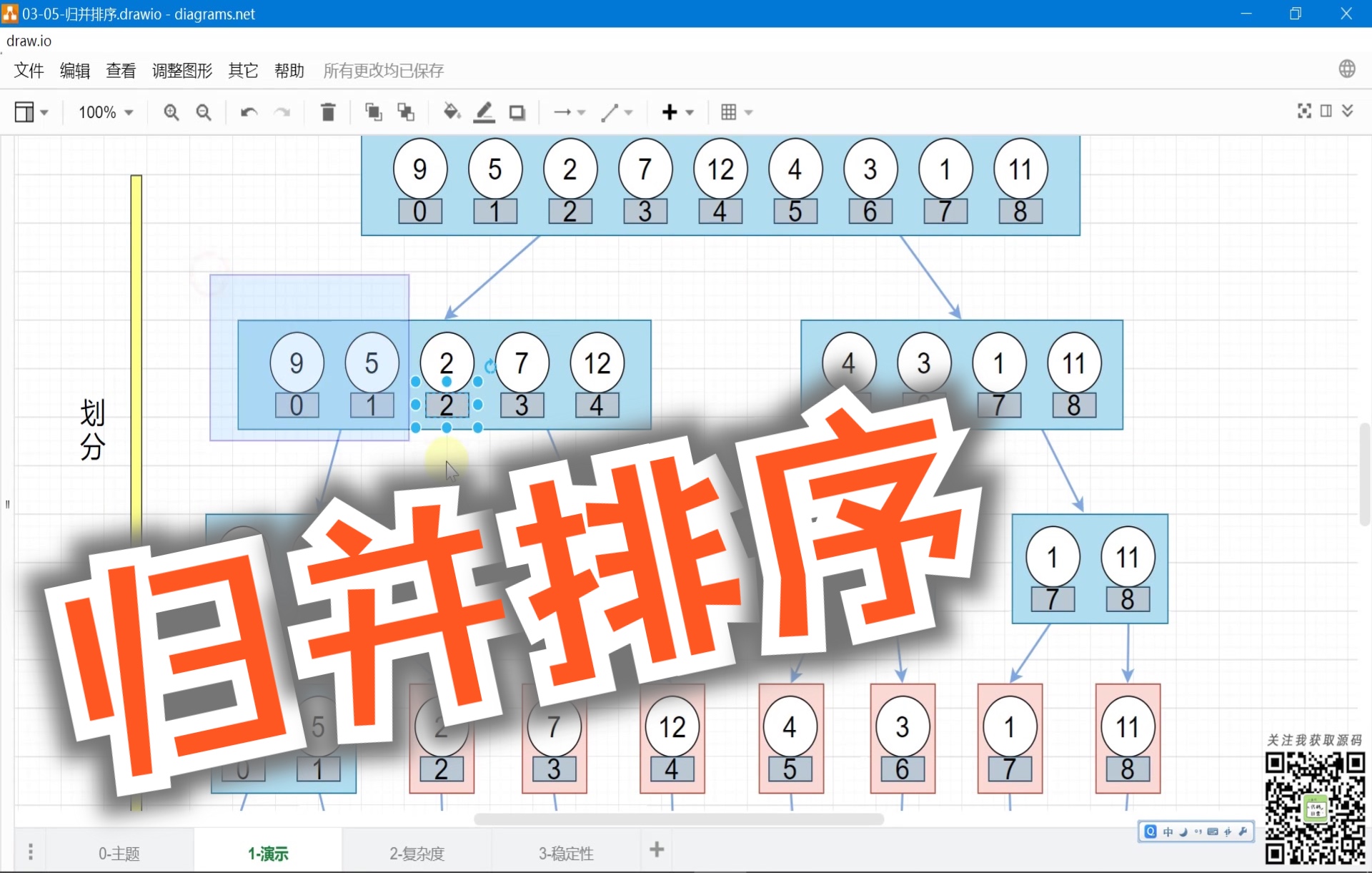
业内专家指出,在处理对象数组排序时,如果需要根据多个字段进行排序,且要求相等元素的原始顺序不被打乱,归并排序是最佳选择,在一个电商订单列表中,如果先按价格排序,再按创建时间排序,使用不稳定的排序算法可能导致相同价格的订单顺序混乱,而归并排序能完美保留这一层级关系。
稳定性与时间复杂度的权衡
理解归并排序的关键在于接受一个事实:它用空间换时间,在JavaScript这种基于对象的内存模型中,创建新数组的成本虽然存在,但相比算法退化的风险,这种代价是值得的。
- 时间复杂度:无论最好、最坏还是平均情况,归并排序始终保持在O(n log n),这意味着即使数据量从10万增加到100万,性能下降也是可控的,不会出现快速排序那样的O(n^2)极端情况。
- 空间复杂度:需要额外的O(n)空间来存储临时数组,在内存受限的移动端或浏览器环境中,这一点需要特别注意。
- 稳定性:相等元素的相对位置保持不变,这对于复杂业务逻辑中的多级排序至关重要。
与快速排序的性能对比场景
很多开发者习惯直接使用Array.prototype.sort(),但在某些极端测试中,原生排序的表现可能不如预期,以下是两种算法在不同数据分布下的表现对比:
| 数据特征 | 快速排序表现 | 归并排序表现 |
推荐场景 |
|---|---|---|---|
| 随机分布 | 极快,平均O(n log n) | 稳定,O(n log n) | 通用场景,快速排序略优 |
| 已排序数据 | 可能退化至O(n^2) | 稳定,O(n log n) | 必须使用归并排序 |
| 少量重复元素 | 性能波动大 | 稳定,O(n log n) | 数据清洗后处理 |
| 大规模数据 | 递归深度可能导致栈溢出 | 递归深度可控 | 大数据集处理 |

据行业共识认为,在Node.js后端服务中处理日志数据或前端Canvas渲染前的坐标点排序时,归并排序因其可预测的性能表现,成为许多资深工程师的首选。
JavaScript中归并排序的实战实现
要掌握js归并排序代码优化技巧,不能只停留在理论层面,我们需要深入代码细节,看看如何在JavaScript引擎中高效地实现这一算法,JavaScript的数组操作虽然方便,但频繁的数组切片(slice)和合并(concat)会带来巨大的性能开销。
基础版实现:直观但低效
初学者最容易写出的版本是利用slice和concat方法,这种方法代码简洁,易于理解,但在处理大数据时,频繁的数组创建和内存分配会导致严重的性能瓶颈。
function mergeSort(arr) {
if (arr.length <= 1) return arr;
const mid = Math.floor(arr.length / 2);
const left = mergeSort(arr.slice(0, mid));
const right = mergeSort(arr.slice(mid));
return merge(left, right);
}
function merge(left, right) {
let result = [];
let i = 0, j = 0;
while (i < left.length && j < right.length) {
if (left[i] <= right[j]) {
result.push(left[i++]);
} else {
result.push(right[j++]);
}
}
return result.concat(left.slice(i)).concat(right.slice(j));
}

这段代码的问题在于,每次递归都会创建新的数组对象,在V8引擎中,这会导致垃圾回收(GC)压力剧增。
优化版实现:原地合并与索引传递
为了提升性能,我们需要减少内存分配,优化的核心思路是:传递索引而非切片数组,并在合并阶段使用预分配的临时数组。
function mergeSortOptimized(arr, tempArr = [], left = 0, right = arr.length - 1) {
if (left < right) {
const mid = Math.floor((left + right) / 2);
mergeSortOptimized(arr, tempArr, left, mid);
mergeSortOptimized(arr, tempArr, mid + 1, right);
merge(arr, tempArr, left, mid, right);
}
return arr;
}
function merge(arr, tempArr, left, mid, right) {
let i = left;
let j = mid + 1;
let k = left;
while (i <= mid && j <= right) {
if (arr[i] <= arr[j]) {
tempArr[k++] = arr[i++];
} else {
tempArr[k++] = arr[j++];
}
}
while (i <= mid) {
tempArr[k++] = arr[i++];
}
while (j <= right) {
tempArr[k++] = arr[j++];
}
for (let idx = left; idx <= right; idx++) {
arr[idx] = tempArr[idx];
}
}
这种实现方式将空间复杂度从递归调用的栈空间优化为单一的临时数组,显著降低了内存占用,在浏览器控制台中运行大规模数据测试,你会发现优化版的执行时间和内存峰值都有明显改善。
常见误区与调试指南
在实际应用中,开发者经常遇到js归并排序边界条件处理的问题,这些细微的Bug往往难以察觉,但会导致排序结果错误。
边界索引的计算陷阱
在计算中点时,使用Math.floor((left + right) / 2)是安全的,但在某些极端情况下,left + right可能会溢出(虽然在JavaScript中数字精度很高,但在其他语言中需注意),更关键的是合并时的索引范围。
- 左半部分:从
left到mid(包含mid)。 - 右半部分:从
mid + 1到right(包含right)。
很多初学者错误地将右半部分的起始索引设为

mid,导致元素重复处理或遗漏。
递归终止条件的确认
递归必须有明确的终止条件,在归并排序中,当left >= right时,说明子数组长度为1或0,无需再分割,如果忘记这一条件,或者错误地判断为length === 0,会导致无限递归或栈溢出。
性能监控与测试
在Chrome DevTools中,可以通过Performance面板监控归并排序的执行情况,观察以下指标:
- 主线程阻塞时间:归并排序是CPU密集型操作,会阻塞UI线程,对于超过10万条数据的排序,建议在Web Worker中运行。
- 内存分配曲线:优化版应显示平稳的内存使用,而基础版会显示锯齿状的内存分配峰值。
据工信部相关技术报告提及,前端性能优化中,算法复杂度对长列表渲染的影响不容忽视,合理选择排序算法,能显著提升用户体验。
Q&A:关于js归并排序的常见疑问
js归并排序在大数据量下是否优于快速排序?
在数据量极大且内存充足的情况下,归并排序因其稳定的O(n log n)性能和稳定性,通常比快速排序更可靠,快速排序在最坏情况下可能退化至O(n^2),而归并排序不会,归并排序易于并行化,可以利用Web Worker将左右子数组的排序任务分发到不同线程,进一步提升性能。
js归并排序的空间复杂度能否进一步优化?
标准的归并排序空间复杂度为O(n),这是由合并操作决定的,理论上,原地归并排序可以将空间复杂度降至O(1),但实现极其复杂,且常数因子较大,实际性能往往不如标准实现,在JavaScript中,由于对象开销大,O(1)空间的原地排序并不具备明显优势,因此O(n)空间复杂度是业界普遍接受的标准。
js归并排序代码优化技巧有哪些具体步骤?
优化归并排序的具体步骤包括:避免在递归中创建新数组,改为传递索引;预分配一个与输入数组等大的临时数组,避免在合并过程中频繁分配内存;对于小规模子数组(如长度小于16),可以切换为插入排序,因为插入排序在小数据量下常数因子更小,能减少递归开销。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/274434.html









