当Ajax需要传递超过1MB的大数据时,直接拼接URL参数会导致请求失败,最佳方案是将数据封装为JSON对象并通过POST方法发送,同时配合序列化压缩或分片传输技术以确保稳定性。
在Web开发领域,前端与后端的数据交互如同神经系统的信号传导,过去,开发者习惯用GET请求传递少量查询条件,这种轻量级的交互模式在早期互联网时代非常高效,随着富互联网应用(RIA)的普及,业务逻辑日益复杂,前端需要向服务器提交的数据量呈指数级增长,无论是批量导入Excel表格、上传包含大量元数据的表单,还是同步复杂的用户操作日志,传统的URL参数拼接方式都显得捉襟见肘,浏览器对URL长度有限制,通常Chrome和Firefox限制在8KB左右,而IE甚至更短,一旦数据量突破这个阈值,请求便会直接报错,导致用户体验中断,掌握Ajax传递大数据的正确姿势,已成为现代前端工程师的必备技能。
Ajax大数据传输的核心痛点与解决方案对比
在处理大量数据时,开发者常面临两个主要选择:继续使用GET请求还是转向POST请求,这不仅仅是HTTP方法的切换,更是架构思维的转变。
GET与POST在大数据场景下的本质差异
GET请求将数据附加在URL末尾,这种方式虽然便于缓存和书签保存,但其局限性极为明显,URL长度受限是硬伤,数据暴露在地址栏中也带来了安全隐患,对于包含敏感信息的大数据包,GET显然不是明智之选。
相比之下,POST请求将数据放置在请求体(Request Body)中,HTTP协议对请求体大小没有硬性限制,主要受限于服务器配置和内存资源,这意味着,理论上你可以发送几GB的数据,只要网络带宽和服务器处理能力允许。
| 特性 | GET请求 | POST请求 |
|---|---|---|
| 数据位置 | URL参数 | 请求体(Body) |
| 长度限制 | 受浏览器限制(约2KB-8KB) | 理论上无限制(受服务器配置影响) |
| 安全性 | 数据明文显示在URL,易被记录 | 相对安全,不暴露在地址栏 |
| 缓存机制 | 可被浏览器缓存 | 默认不缓存,需手动设置 |
| 适用场景 | 少量查询、获取资源 | 数据提交、文件上传、大数据传输 |

业内专家指出,从RESTful API的设计规范来看,POST用于创建或更新资源,天然适合承载复杂且大量的数据负载,在涉及大数据传输时,转向POST是行业共识。
JSON格式:大数据传输的标准载体
确定了使用POST方法后,数据格式的选择同样关键,虽然传统的表单编码(application/x-www-form-urlencoded)可以处理一定数量的数据,但在处理嵌套对象、数组等复杂结构时,其可读性和解析效率远不如JSON。
JSON(JavaScript Object Notation)因其轻量级、易解析且与JavaScript原生支持良好的特点,成为Ajax传递大数据的首选格式,前端将数据序列化为JSON字符串,后端反序列化解析,这一流程已成为标准操作。
实操指南:如何优化Ajax大数据传输性能
仅仅知道使用POST和JSON还不够,在实际生产环境中,直接发送巨大的JSON对象可能导致页面卡顿、内存溢出或超时,我们需要引入优化策略。
第一步:启用Gzip压缩传输
文本数据具有极高的压缩率,对于包含大量重复字段或长字符串的JSON数据,启用Gzip压缩可以显著减少传输体积。
在Nginx或Apache服务器配置中,开启Gzip压缩是成本最低且效果最显著的优化手段,前端发送请求时,在Header中声明Accept-Encoding: gzip,服务器若支持,则返回压缩后的数据,虽然这主要影响响应,但现代浏览器和服务器通常也支持对请求体进行压缩,或者通过中间件代理实现。
具体操作路径
- 服务器端配置:在Nginx配置文件中添加
gzip on;及相关参数,如gzip_types application/json;
。
- 前端Header设置:确保Ajax请求包含
Accept-Encoding: gzip头。 - 验证效果:使用浏览器开发者工具的Network面板,查看请求大小与响应大小的差异,通常可减少60%-80%的体积。

第二步:数据分片与流式上传
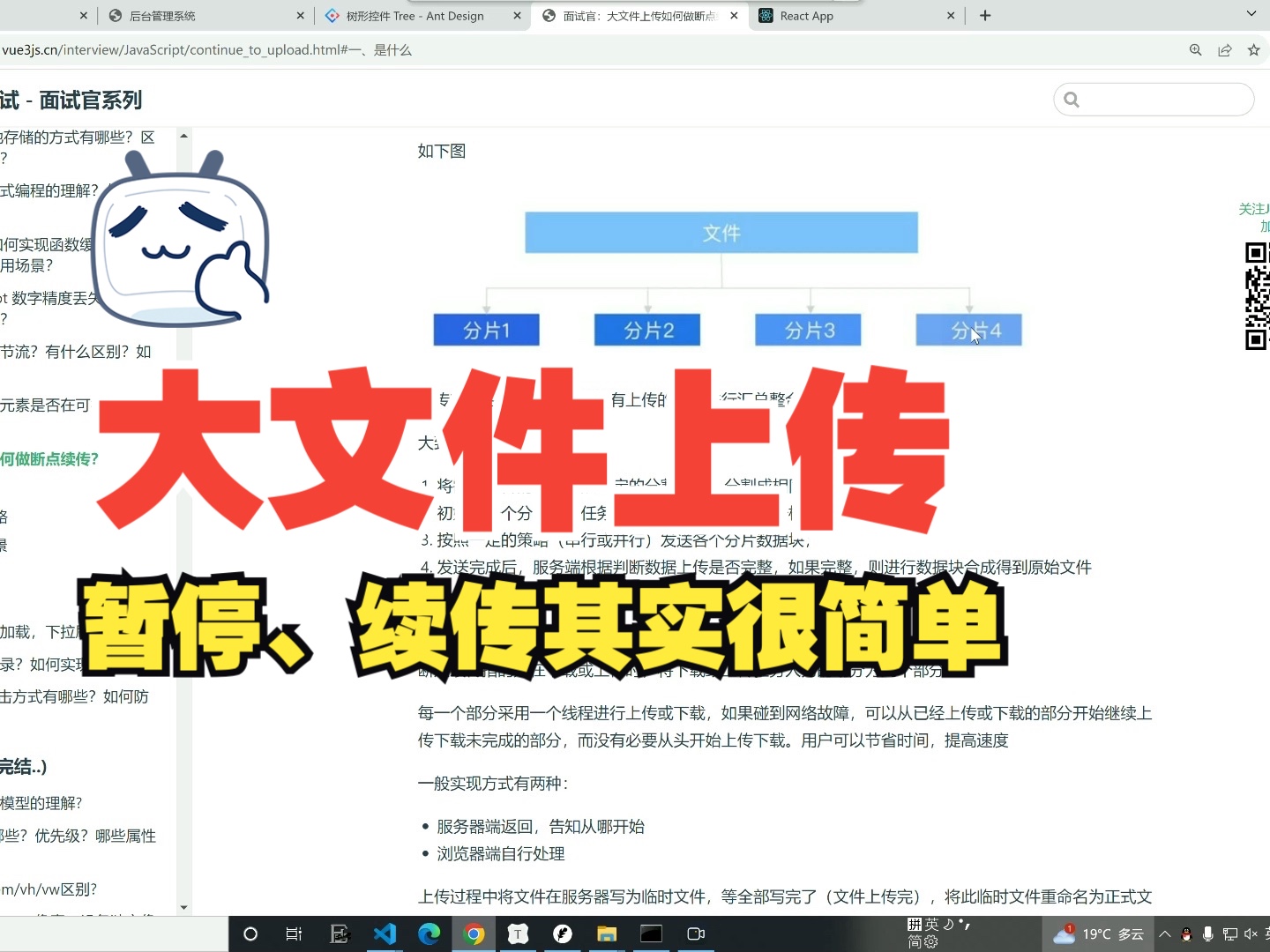
当数据量达到数十MB甚至更大时,单次请求不仅耗时,还容易因网络波动而失败,分片传输(Chunking)成为必要手段。
将大数据集拆分为多个小块,依次发送,后端接收所有分片后,在内存或磁盘中重组数据,这种方式提高了容错率,支持断点续传,并能更好地利用带宽。
分片传输的实现逻辑
- 前端:计算数据总大小,设定分片大小(如1MB),使用
Blob或ArrayBuffer切片,逐个发送请求,每个请求携带当前分片的索引(index)和总索引(total)。 - 后端:接收分片,根据索引写入临时文件,当收到最后一个分片时,触发合并逻辑,生成最终数据文件。
第三步:防抖与节流策略
在用户频繁操作触发数据提交时(如实时保存长文档),直接发送Ajax请求会造成服务器压力激增,引入防抖(Debounce)和节流(Throttle)机制,可以限制请求频率。
- 防抖:在事件触发后等待指定时间,若期间无新触发,则执行一次请求,适用于搜索框输入、表单提交。
- 节流:在指定时间间隔内,只执行一次请求,适用于滚动加载、按钮点击。
常见误区与调试技巧
在实际开发中,即使使用了POST和JSON,仍可能遇到数据丢失或解析错误,以下是一些高频问题的排查思路。
Content-Type头部的正确设置
许多开发者在发送JSON数据时,忘记设置Content-Type: application/json,这会导致后端默认按表单格式解析,从而无法识别JSON字符串,返回400错误或解析为空对象。
务必在Ajax配置中显式指定Content-Type,在jQuery中设置contentType: 'application/json',在原生Fetch API中设置headers: { 'Content-Type': 'application/json' }。
后端接收参数的注解配置
在后端框架中,如Spring Boot的Java应用,接收JSON数据需要使用

@RequestBody注解,若误用@RequestParam,则只能接收URL参数或表单数据,导致JSON数据被忽略。
对于复杂的大数据对象,确保后端DTO(数据传输对象)的属性名与前端JSON字段名一致,或使用@JsonProperty进行映射。
跨域资源共享(CORS)问题
大数据传输常涉及前后端分离架构,跨域请求不可避免,若后端未正确配置CORS,浏览器会拦截请求。
检查后端是否允许了POST方法,以及是否允许了Content-Type: application/json头,在Spring Boot中,可使用@CrossOrigin注解或配置全局CORS策略。
Q&A:Ajax传递大数据参数常见疑问
Ajax传递大数据参数时,如何避免内存溢出?
内存溢出通常发生在前端尝试一次性加载或处理过大的JSON对象时,为避免此问题,建议采用流式处理或分片传输,前端不要将完整的大数据对象存储在单个变量中,而是通过迭代器或生成器逐步构建数据,后端也应避免将所有数据加载到内存中,而是采用流式写入磁盘,对于前端展示,可使用虚拟列表技术,仅渲染可视区域内的数据,而非一次性渲染所有节点。
Ajax传递大数据参数,POST请求体大小限制是多少?
HTTP协议本身对POST请求体大小没有固定限制,主要取决于服务器配置,Nginx默认client_max_body_size为1MB,Apache的LimitRequestBody默认为0(无限制),实际限制由服务器管理员设定,开发者需根据业务需求调整服务器配置,并确保客户端发送的数据不超过该限制,若需传输超大文件,建议使用专门的上传接口,而非通用的数据提交接口。
Ajax传递大数据参数,是否支持断点续传?
标准的Ajax请求本身不支持断点续传,因为每次请求都是独立的,要实现断点续传,需在前端实现分片逻辑,记录每个分片的上传状态,当网络中断恢复后,前端检查已上传的分片索引,跳过已完成的部分,仅上传剩余分片,后端需维护分片状态,支持部分上传和合并,这种机制通常用于大文件上传场景,对于纯文本大数据,可通过重试机制和分片发送实现类似效果。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/302591.html










