HTML5语音输入技术通过浏览器原生API实现,无需安装插件即可将语音实时转为文字,目前主流浏览器如Chrome、Edge均支持该功能,适合快速录入、无障碍操作及移动端高效办公场景。
HTML5语音输入的技术原理与核心优势
语音输入并非简单的录音转写,而是基于Web Speech API构建的交互体系,这一技术栈让网页应用具备了“听”和“说”的能力,极大地降低了人机交互的门槛。

底层逻辑:Web Speech API的双引擎驱动
业内专家指出,Web Speech API主要包含两个核心接口:SpeechRecognition用于语音识别,SpeechSynthesis用于语音合成,在HTML5语音输入场景中,我们主要关注前者,当用户点击麦克风图标时,浏览器会启动音频捕获进程,将模拟信号数字化后发送给后端引擎进行语义分析。
- 实时性:数据流是分段传输的,而非等待整段说完,这意味着用户能即时看到转换结果。
- 低延迟:得益于现代浏览器的优化,从发声到显示文字的延迟通常控制在毫秒级。
- 离线能力:部分高级实现支持本地模型缓存,在弱网环境下仍能保持基础识别功能。
对比传统输入法:效率与体验的差异化
很多人疑惑,既然有键盘和拼音输入法,为何还要用语音?这涉及不同场景下的效率博弈。
| 维度 | 传统键盘/拼音输入 | HTML5语音输入 |
|---|---|---|
| 输入速度 | 熟练者约40-60字/分钟 | 平均150-200字/分钟(口语化表达) |
| 操作负担 | 需双手配合,占用桌面空间 | 单手即可操作,解放双手 |
| 适用场景 | 精确校对、代码编写、数字录入 | 会议记录、语音笔记、无障碍浏览 |
| 准确率 | 接近100%(无错别字) | 受环境噪音影响,需后期微调 |

多数情况下,语音输入在处理长篇大论或灵感迸发时具有压倒性优势,它允许用户保持思维的连续性,避免因打字中断思路。
主流浏览器支持情况与兼容性解析
在部署或体验HTML5语音输入时,兼容性是首要考虑因素,不同浏览器的实现标准存在细微差异,这直接影响开发者的技术选型和最终用户的体验。
Chrome与Edge的领先地位
Google Chrome和Microsoft Edge基于Chromium内核,对Web Speech API的支持最为完善,它们通常调用云端引擎,识别准确率极高,尤其是对中文方言和多义词的处理能力较强,对于寻找html5语音输入兼容性这两款浏览器是首选。
- Chrome:支持
webkitSpeechRecognition及标准SpeechRecognition接口,自动处理权限请求。 - Edge:除了基础功能外,还集成了微软的Azure认知服务,提供企业级的高精度识别。
Safari与Firefox的特殊限制
Apple Safari在iOS和macOS上对语音输入的支持较为封闭,虽然Safari 14+开始支持Web Speech API,但在iOS设备上,往往需要调用系统的原生语音输入键盘,而非网页内的自定义UI,Firefox则出于隐私考量,默认禁用部分云端API,用户需手动开启配置。
据统计,国内仍有相当一部分用户在使用旧版浏览器或国产双核浏览器的兼容模式,这可能导致语音功能失效,在开发时必须提供降级方案,例如提示用户“请使用Chrome浏览器以获得最佳体验”。
开发者实操指南:如何集成语音输入功能
对于前端开发者而言,集成HTML5语音输入并不复杂,但需要注意细节处理,以确保用户体验的流畅性。
基础代码实现路径
以下是实现一个基础语音输入框的标准步骤:

- 检测支持性:首先检查浏览器是否支持
SpeechRecognition对象。 - 初始化配置:设置语言代码(如
zh-CN)、连续监听模式(continuous: true)和最终结果返回(interimResults: true)。 - 绑定事件:监听
onresult事件以获取实时文字,onerror处理错误,onend处理停止。
const recognition = new (window.SpeechRecognition || window.webkitSpeechRecognition)();
recognition.lang = 'zh-CN';
recognition.continuous = true;
recognition.interimResults = true;
recognition.onresult = (event) => {
let transcript = '';
for (let i = event.resultIndex; i < event.results.length; ++i) {
transcript += event.results[i][0].transcript;
}
document.getElementById('output').innerText = transcript;
};
权限管理与用户体验优化
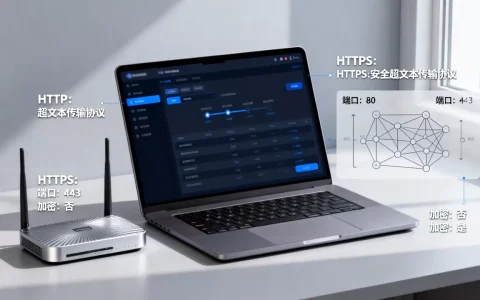
浏览器出于安全考虑,强制要求HTTPS环境才能调用麦克风权限,这意味着如果你的网站是HTTP协议,语音功能将直接失效。
- 权限提示:在用户点击按钮前,应明确告知将请求麦克风权限,避免浏览器弹窗造成突兀感。
- 视觉反馈:必须提供明显的录音状态指示器(如波纹动画),让用户知道系统正在“倾听”。
- 错误处理:针对
no-speech、audio-capture等错误,提供友好的中文提示,而非直接抛出技术代码。
常见应用场景与商业价值分析
HTML5语音输入早已超越个人娱乐范畴,深入到了多个垂直行业,成为提升数字化效率的关键工具。
在线教育:互动课堂的新标配
在在线编程教学或语言学习中,html5语音输入在在线教育中的应用已成为趋势,教师可以通过语音提问,学生通过语音回答,系统实时转写并展示在屏幕上,这不仅增加了课堂互动性,还特别帮助了视障学生或打字速度较慢的学生平等参与课堂。

客服系统:智能工单自动化
现代客服中心正在大规模部署语音转文字技术,当客户拨打热线或在线沟通时,系统自动将对话内容转为文本,并生成工单摘要。
- 降本增效:人工整理录音的时间成本降低约70%。
- 情感分析:基于转写文本,AI可进一步分析客户情绪,预警投诉风险。
- 数据沉淀:所有语音对话变为结构化文本,便于后续检索和分析。
创作:灵感捕捉利器
对于作家、记者和自媒体人,html5语音输入在内容创作中的优势显而易见,在通勤、散步或无法使用键盘时,通过语音记录灵感片段,后期再整理成文,这种“先录后改”的工作流,显著提升了内容产出的频率和质量。
HTML5语音输入常见问题解答
HTML5语音输入支持哪些语言?
Web Speech API支持多种语言,包括普通话(zh-CN)、粤语(zh-TW)、英语(en-US)等,具体支持的语言列表取决于浏览器内核及操作系统,开发者可通过recognition.lang属性动态切换语言,但需注意,部分小众语言可能仅支持云端识别,离线模式下不可用。
语音输入在嘈杂环境中准确率如何?
环境噪音是影响准确率的最大变量,虽然现代算法具备一定的人声分离能力,但在地铁、街道等高分贝场景下,错误率会显著上升,建议在有降噪麦克风硬件支持的设备上使用,或在软件层面增加“去噪”预处理步骤,业内共识认为,安静环境下的识别准确率可达95%以上,而嘈杂环境可能降至70%-80%。
HTML5语音输入的数据隐私安全吗?
数据隐私是用户最关心的问题,主流浏览器在调用API时,会明确提示用户是否允许访问麦克风,且数据通常发送至浏览器厂商的云端服务器进行处理,对于高敏感行业,建议采用本地化部署的语音识别方案,或选择支持私有云API的企业级服务,以确保数据不出内网,据工信部相关数据安全规范,涉及个人信息的语音数据必须进行加密传输和存储。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/362524.html