ARIMA模型在Python中的核心实现依赖于statsmodels库,通过“差分-自回归-移动平均”三步法处理时间序列数据,能有效解决线性趋势预测问题,但需严格满足平稳性假设。
时间序列分析是数据科学中的硬骨头,而ARIMA(自回归积分滑动平均模型)无疑是其中最具代表性的工具之一,很多初学者在面对杂乱无章的时间序列数据时,往往感到无从下手,只要理清了模型的底层逻辑,并掌握正确的Python实操步骤,预测未来趋势并非难事,本文将深入拆解ARIMA在Python中的落地流程,从环境配置到模型评估,提供一套可复现的解决方案。
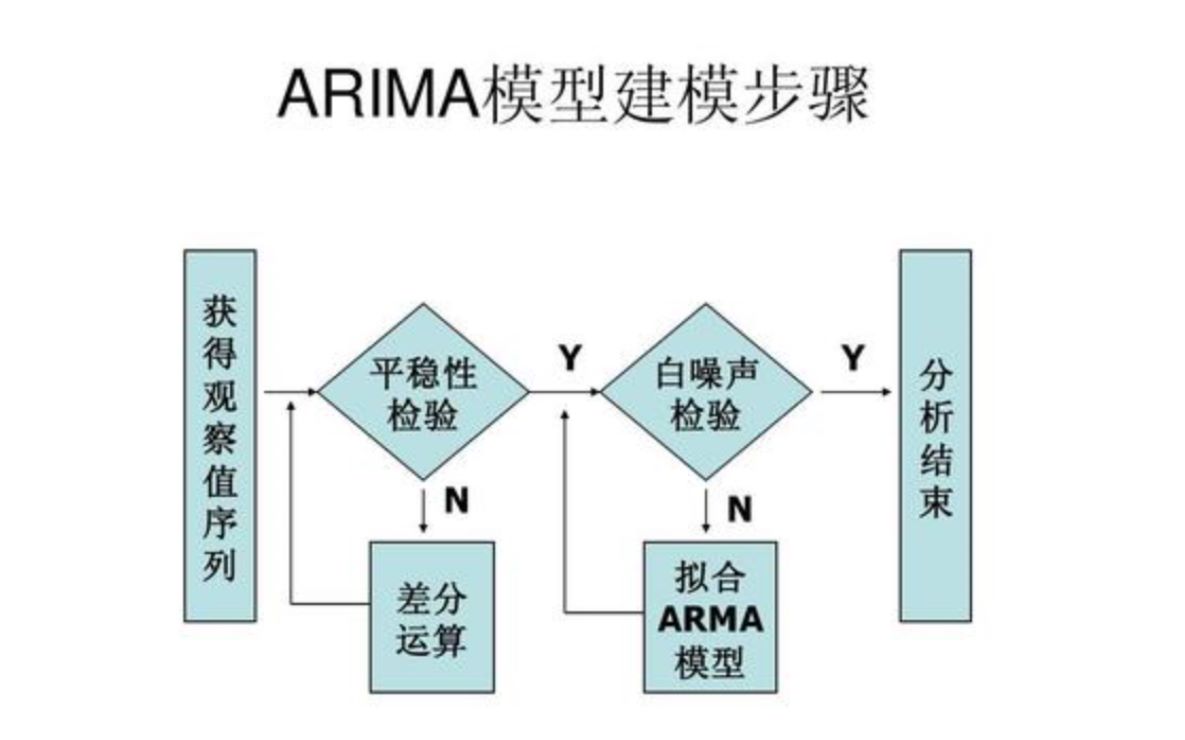
ARIMA模型在Python中的基础环境搭建
在开始建模之前,确保开发环境正确配置是第一步,业内专家指出,Python生态中处理时间序列最权威且广泛使用的库是statsmodels,它提供了完整的ARIMA实现接口。
核心库的安装与导入
你需要安装以下三个关键库:
- pandas:用于数据加载和预处理,处理时间索引。
- numpy:用于数值计算和数组操作。
- statsmodels:核心建模库,提供ARIMA类。
安装命令非常简单,在终端或命令行中输入:pip install pandas numpy statsmodels matplotlib,安装完成后,在代码头部导入模块:import pandas as pd,import numpy as np,from statsmodels.tsa.arima.model import ARIMA。
数据加载与时间索引设置
ARIMA模型对数据的格式有严格要求,数据必须是一个带有时间索引的一维序列,假设你有一份包含日期和销售额的数据,首先需要确保日期列被转换为datetime类型,并设置为索引。
具体操作路径
- 读取CSV文件:使用pd.read_csv()加载数据。
- 转换日期:使用pd.to_datetime()将日期列标准化。
- 设置索引:使用df.set_index(‘date’)将日期列设为索引。
- 重采样:如果数据频率不统一(如每日数据中有缺失),需使用df.resample(‘D’).mean()进行重采样填充,确保时间序列的连续性。

平稳性检验与差分处理
ARIMA模型的前提是数据必须是平稳的,即均值和方差不随时间变化,绝大多数原始时间序列数据(如股票价格、气温)都是非平稳的,因此需要进行差分处理。
如何判断数据是否平稳
判断平稳性主要有两种方法:
- ADF检验(Augmented Dickey-Fuller Test):这是最常用的统计检验方法,原假设是数据存在单位根(非平稳),如果p值小于显著性水平(通常为0.05),则拒绝原假设,认为数据是平稳的。
- 可视化观察:绘制时间序列图,如果数据呈现出明显的趋势或季节性波动,则通常是非平稳的。
在Python中,可以使用statsmodels.tsa.stattools.adfuller函数进行ADF检验。
差分操作的实现
如果数据非平稳,需要进行d阶差分,差分的目的就是消除趋势和季节性,在ARIMA(p,d,q)参数中,d代表差分的阶数。
- 一阶差分:适用于具有线性趋势的数据,计算公式为:y_t’ = y_t – y_{t-1}。
- 二阶差分:适用于具有二次趋势的数据。
实操中,可以通过观察ADF检验的p值变化来确定d的值,一阶差分后p值显著降低,即可确定d=1。
模型定阶:P、D、Q参数的确定
确定ARIMA模型的三个参数p(自回归阶数)、d(差分阶数)、q(移动平均阶数)是建模中最关键也最困难的一步,目前业界主流的做法是结合AIC/BIC准则和ACF/PACF图进行综合判断。

使用ACF和PACF图辅助定阶
ACF(自相关函数)和PACF(偏自相关函数)图是直观判断p和q值的重要工具。
- AR(p)模型:PACF图在p阶后截尾,ACF图呈拖尾状。
- MA(q)模型:ACF图在q阶后截尾,PACF图呈拖尾状。
- ARMA(p,q)模型:ACF和PACF图均呈拖尾状。
在Python中,可以使用statsmodels.graphics.tsaplots.plot_acf和plot_pacf函数绘制这些图表。
自动化定阶:Grid Search
手动观察图表虽然直观,但效率低下且主观性强,对于复杂的时间序列,业内共识认为使用网格搜索(Grid Search)结合信息准则(AIC或BIC)是更科学的方法。
网格搜索实操步骤
- 定义参数范围:设定p、d、q的可能取值范围,例如p=[0,1,2],d=[0,1],q=[0,1,2]。
- 遍历组合:使用嵌套循环遍历所有可能的(p,d,q)组合。
- 拟合模型:对每个组合拟合ARIMA模型。
- 记录指标:记录每个模型的AIC值。
- 选择最优:选择AIC值最小的组合作为最终模型参数。
注意:由于ARIMA模型对初始值敏感,网格搜索可能会遇到收敛问题,建议设置maxiter参数增加迭代次数。
模型评估与预测
模型建立后,必须对其效果进行评估,才能应用于实际业务场景。
残差分析
好的ARIMA模型,其残差应该服从正态分布且无自相关,可以通过绘制残差的直方图、QQ图以及进行Ljung-Box检验来验证,如果残差中存在显著的自相关,说明模型未能充分提取数据中的信息,需要重新调整参数。
预测未来趋势
使用训练好的模型进行预测非常简单,调用model.forecast(steps=n)方法,其中n为需要预测的未来步数。

可视化对比
将历史数据、模型拟合值和预测值绘制在同一张图上,可以直观地评估模型的拟合效果和预测趋势,预测区间会随着预测步数的增加而变宽,这反映了不确定性的增加。
常见误区与优化建议
在实际应用中,很多用户会遇到“为什么我的预测效果不好”的疑问,这通常源于以下几个误区:
- 忽视季节性:标准ARIMA模型无法处理季节性数据,如果数据具有明显的季节性,应使用SARIMA(季节性ARIMA)模型,增加季节性参数P、D、Q、S。
- 数据量不足:ARIMA模型需要足够长的历史数据才能捕捉到稳定的模式,一般建议至少拥有2-3个完整周期的数据。
- 过度拟合:过高的p和q值可能导致模型过度拟合噪声,降低泛化能力,务必使用AIC/BIC准则进行约束。
常见问题解答
ARIMA模型在Python中的常见疑问解答
ARIMA模型适合处理哪些类型的数据?
ARIMA模型主要适用于具有线性趋势且残差为白噪声的时间序列数据,对于具有强非线性、突变点或复杂季节性特征的数据,ARIMA的效果可能有限,此时应考虑使用Prophet、LSTM或SARIMA等更复杂的模型。
如何确定ARIMA模型的最佳参数?
最佳参数的确定没有统一公式,通常结合ACF/PACF图的直观判断和AIC/BIC准则的数值优化,实践中,建议先通过ADF检验确定差分阶数d,再通过网格搜索在较小的p和q范围内寻找AIC最小的组合。
Python中ARIMA模型的预测区间如何解读?
预测区间反映了预测的不确定性,区间越宽,说明未来波动越大,预测置信度越低,在业务决策中,应同时关注预测点值和预测区间,避免仅依赖点预测值做出高风险决策。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/366747.html