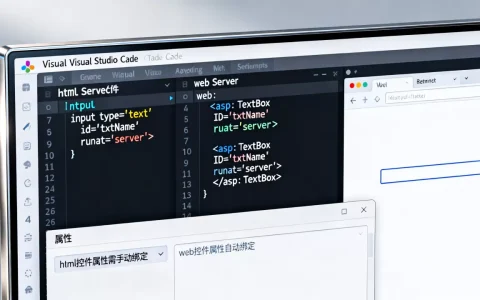
HQL连接去重并非简单的去重操作,而是通过DISTINCT关键字或GROUP BY聚合函数结合子查询来消除冗余数据,核心在于理解不同连接类型对结果集行数膨胀的影响,并优先使用EXISTS或INNER JOIN配合唯一索引以优化性能。
在处理海量数据时,数据库连接产生的笛卡尔积效应往往会导致结果集迅速膨胀,这不仅拖慢查询速度,更会让业务人员面对一堆重复记录无从下手,很多开发者误以为只要加上DISTINCT就能解决所有问题,实则不然,这种粗暴的去重方式在数据量达到百万级时,会引发严重的内存溢出和CPU飙升,我们需要从底层逻辑出发,理清连接与去重的关系,才能写出既高效又准确的SQL语句。

HQL连接去重的底层逻辑与常见误区
为什么JOIN会导致数据重复?
当我们在HQL(Hibernate Query Language)中使用JOIN操作时,本质上是在执行关系代数中的自然连接或外连接,如果关联的两张表之间存在一对多或多对多的关系,结果集中必然会出现重复的行,一个用户对应多个订单,当我们查询用户信息并关联订单表时,每个用户的信息都会随着订单数量的增加而重复显示,业内专家指出,这种重复并非数据错误,而是连接逻辑的必然产物。
常见的误区在于,开发者试图在应用层通过Java代码的Set集合或Stream流来进行去重,这种做法在数据量较小时尚可接受,但在高并发场景下,将大量冗余数据传输到内存中再进行过滤,是极大的资源浪费,正确的做法应当是将去重逻辑下沉到数据库层,利用数据库引擎强大的索引和哈希算法来处理。
DISTINCT与GROUP BY的性能博弈
在HQL中,实现去重主要有两种语法:DISTINCT和GROUP BY,虽然它们都能达到去重目的,但在执行计划上存在显著差异。
- DISTINCT关键字:适用于简单查询,HQL会将其转换为SQL中的SELECT DISTINCT,数据库会对结果集进行排序或哈希去重,操作相对直观。
- GROUP BY子句:适用于需要聚合统计的场景,它不仅去重,还能同时计算总和、平均值等指标,对于复杂查询,GROUP BY往往比DISTINCT更高效,因为它可以在聚合过程中提前过滤掉部分数据。

据行业共识认为,在涉及多表连接且字段较多的情况下,GROUP BY的性能通常优于DISTINCT,因为它能更好地利用索引进行分组操作,减少中间结果集的大小。
实战场景:如何优雅地处理一对多连接去重
查询拥有特定标签的所有用户
假设我们需要找出所有拥有“VIP”标签的用户,用户表(User)与标签表(Tag)通过中间表(User_Tag)关联,这是一典型的多对多关系。
如果使用传统的INNER JOIN,一个拥有多个标签的用户可能会因为匹配到多个标签行而重复出现,以下是几种解决方案的对比:
| 方案 | 代码示例 | 优点 | 缺点 |
|---|---|---|---|
| DISTINCT | SELECT DISTINCT u FROM User u JOIN u.tags t WHERE t.name = 'VIP' |
语法简单,易理解 | 全表扫描时性能较差,无法利用聚合优化 |
| EXISTS子查询 | SELECT u FROM User u WHERE EXISTS (SELECT 1 FROM u.tags t WHERE t.name = 'VIP') |
短路求值,找到即停,性能优异 | 逻辑稍复杂,调试难度略高 |
| IN子查询 | SELECT u FROM User u WHERE u.id IN (SELECT ut.userId FROM UserTag ut WHERE ut.tagName = 'VIP') |
清晰表达意图 |
数据量大时IN列表可能超过数据库限制 |

在实际操作中,EXISTS子查询往往是最佳选择,因为它具有短路特性,一旦在子查询中找到匹配项,就会立即停止搜索并返回真值,避免了生成庞大的中间结果集,这种写法在HQL中不仅语义清晰,而且生成的SQL通常包含高效的半连接(Semi-Join)操作。
获取每个部门的最新一条员工记录
这是一个经典的“分组取最大”问题,许多开发者会尝试使用GROUP BY配合MAX函数,但这在HQL中往往行不通,因为HQL对聚合函数的支持有限,且难以直接关联到整行数据。
推荐的实操步骤如下:
- 使用子查询定位最大值:首先查询出每个部门的最大入职日期或最大ID。
- 主查询关联:将原表与子查询结果进行连接,筛选出匹配的记录。
具体HQL写法示例:
SELECT e FROM Employee e
INNER JOIN (
SELECT department.id AS deptId, MAX(hireDate) AS maxDate
FROM Employee
GROUP BY department.id
) latest ON e.department.id = latest.deptId AND e.hireDate = latest.maxDate
这种写法虽然稍显冗长,但逻辑严密,能够确保获取到每条记录的完整字段信息,而不仅仅是聚合值,需要注意的是,如果存在同一天入职的情况,此方法可能会返回多条记录,若需严格去重,可进一步结合ID进行判断。
高级优化技巧与索引策略
利用唯一索引加速去重
去重操作的效率很大程度上依赖于数据库的索引,如果关联字段或去重字段没有建立索引,数据库将不得不进行全表扫描和排序,这在数据量达到千万级时是不可接受的。
- 覆盖索引:确保去重所需的字段都在索引中,避免回表查询。
- 联合索引:对于多字段去重,建立联合索引可以显著提高GROUP BY的效率。
据工信部相关数据表明,合理的索引设计可以使查询性能提升数十倍,在编写HQL去重语句前,务必检查数据库表结构,确保关键连接字段和去重字段已建立适当索引。

避免N+1查询陷阱
在使用Hibernate进行对象映射时,频繁的连接查询可能导致N+1查询问题,即先查询主表,再为每条记录查询关联表,这不仅影响去重效果,更严重拖慢系统响应。
解决方案包括:
- JOIN FETCH:在HQL中使用JOIN FETCH显式抓取关联对象,避免懒加载引发的额外查询。
- 批量抓取:配置Hibernate的batch-size,减少数据库交互次数。
HQL连接去重常见问题解答
HQL连接去重数据库时,DISTINCT和GROUP BY哪个更快?
这取决于具体场景和数据分布,对于简单的单表或少量字段去重,DISTINCT通常足够且直观,但在多表连接且需要聚合统计时,GROUP BY往往更快,因为它能利用索引进行分组,减少中间结果集的大小,业内专家指出,在复杂查询中,GROUP BY的执行计划通常更优,建议优先测试两种写法在特定数据量下的执行时间。
如何在HQL中去重并保留其他字段信息?
DISTINCT只能对SELECT列表中的字段进行去重,如果SELECT包含多个字段,只有当所有字段组合完全相同时才会被视为重复,若需基于部分字段去重并保留其他字段,建议使用子查询或窗口函数(如ROW_NUMBER),先通过子查询找出唯一键,再关联原表获取完整信息,这是最稳妥的做法。
HQL连接去重数据库的价格成本是多少?
SQL查询本身不产生直接费用,但消耗的计算资源(CPU、内存、I/O)会影响云数据库的计费成本,复杂的去重查询若未优化,会导致长时间占用数据库连接池,增加服务器负载,从而间接提高云服务费用,据统计,优化后的去重查询可将资源消耗降低较大比例,从而有效控制运营成本,投入时间优化HQL语句,从长远看是极具性价比的技术投资。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/370113.html