安装MapReduce的核心在于配置Hadoop分布式环境,通过下载二进制包、修改配置文件并启动守护进程,即可在单机或集群中实现分布式计算框架的部署。
MapReduce作为Hadoop生态系统的基石,其安装过程并非简单的解压软件,而是一次对分布式系统底层逻辑的梳理,对于许多初学者而言,面对复杂的XML配置文件和环境变量设置,往往感到无从下手,只要理清了“主节点”与“从节点”的协作关系,安装过程就像搭建积木一样清晰,本文将摒弃晦涩的理论,直接切入实操,带你一步步完成MapReduce环境的搭建。
安装MapReduce前的环境准备与依赖检查
在正式动手之前,确保基础环境的健康是避免后续报错的关键,MapReduce依赖于Java运行环境,且对网络通信和文件系统有特定要求。
Java环境配置与版本选择
业内专家指出,Java版本的兼容性是安装失败的首要原因,MapReduce通常要求JDK 8或JDK 11,具体取决于你使用的Hadoop版本。
验证Java安装状态
在终端输入`java -version`,确认已安装且版本符合预期,如果系统提示未找到命令,需要先配置JAVA_HOME环境变量。
配置环境变量
编辑`~/.bashrc`或`/etc/profile`文件,添加如下内容:
“`bash
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
“`
执行`source ~/.bashrc`使配置立即生效,这一步看似简单,却是后续所有Java进程能够启动的前提。
SSH无密码登录配置
MapReduce在启动时会通过SSH连接各个节点(即使是单机伪分布式也需要本地SSH连接),如果没有配置免密登录,启动脚本会因等待密码输入而超时或报错。
生成密钥对
执行`ssh-keygen -t rsa -P ” -f ~/.ssh/id_rsa`,一路回车即可。
分发公钥
执行`cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys`,并将权限设置为600:`chmod 600 ~/.ssh/authorized_keys`,测试`ssh localhost`,若无需输入密码直接登录,则配置成功。

MapReduce核心配置文件详解与修改
下载Hadoop安装包并解压后,进入etc/hadoop目录,这里是所有配置的心脏,修改配置文件是安装过程中最考验耐心的环节,也是理解分布式原理的最佳窗口。
环境变量设置
编辑hadoop-env.sh文件,找到export JAVA_HOME一行,将其修改为你实际的Java安装路径。export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
这一步确保Hadoop知道去哪里寻找Java解释器。
核心参数配置
MapReduce的运行模式分为单机模式、伪分布式模式和完全分布式模式,对于大多数个人学习和小规模测试,伪分布式模式是性价比最高的选择。
core-site.xml配置
此文件定义Hadoop的全局属性,我们需要指定HDFS的默认文件系统URI。
“`xml
“`
这里`localhost`表示当前机器,`9000`是默认端口。
hdfs-site.xml配置
配置HDFS的副本因子和数据存储路径,伪分布式下,副本因子设为1即可。
“`xml
“`
注意,路径需提前创建,否则NameNode启动时会因目录不存在而失败。
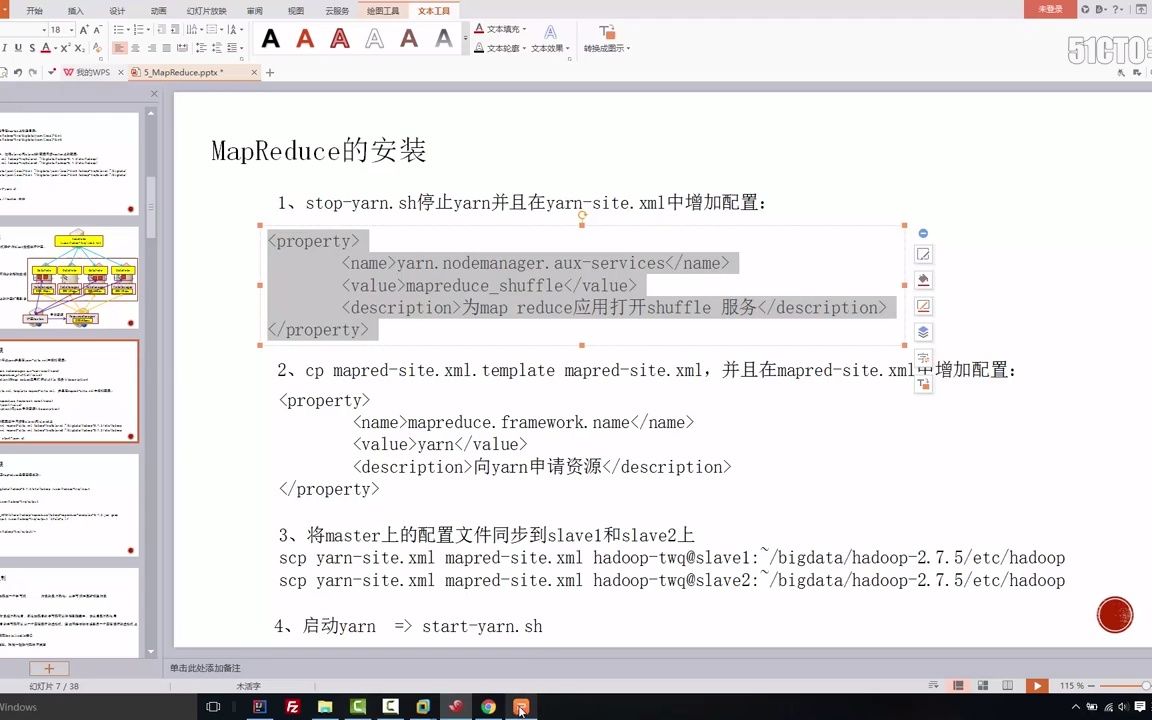
yarn-site.xml配置
YARN是资源调度器,MapReduce任务最终由YARN管理。
“`xml
“`
`mapreduce_shuffle`是MapReduce运行所需的辅助服务,必须配置。
MapReduce专属配置
编辑mapred-site.xml(若不存在,可从mapred-site.xml.template复制),指定MapReduce的运行框架为YARN。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
这是最关键的一步,若未配置,MapReduce任务将尝试在本地运行,导致无法利用集群资源。
初始化、启动与验证流程
配置完成后,进入执行阶段,这一过程涉及格式化和启动守护进程,顺序不可颠倒。
格式化NameNode
首次安装必须执行格式化操作,以创建HDFS的文件系统元数据。
执行命令:hdfs namenode -format
成功时,终端最后会显示“Storage directory … has been successfully formatted”,若重复格式化,需先删除dfs.name.dir指向的目录,否则NameNode会拒绝启动。
启动HDFS与YARN
进入Hadoop安装目录的sbin文件夹,执行启动脚本。
./start-dfs.sh ./start-yarn.sh
启动后,可通过jps命令查看进程,若看到NameNode、DataNode、ResourceManager、NodeManager和JobHistoryServer(若开启)等进程,说明服务已正常启动。
Web界面验证
打开浏览器,访问http://localhost:9870查看HDFS状态,访问http://localhost:8088查看YARN资源调度情况,这是最直观的验证方式,无需编写代码即可确认环境健康。

常见问题排查与优化建议
在安装MapReduce分布式计算环境的过程中,用户常遇到端口占用或权限问题。
端口冲突处理
若启动失败,检查是否已有其他服务占用9000、8088或9870端口,使用netstat -tlnp查看端口占用情况,并修改core-site.xml或yarn-site.xml中的端口号,重新格式化并重启。
权限问题
确保Hadoop目录及其子目录的所有者是你当前用户,若使用root权限安装,建议创建专用用户(如hadoop)并授权,避免后续文件读写权限混乱。
性能微调
对于MapReduce集群搭建后的性能优化,可适当调整JVM堆内存大小,在mapred-site.xml中增加mapreduce.map.memory.mb和mapreduce.reduce.memory.mb的值,以适应更复杂的数据处理任务。
MapReduce安装常见问题Q&A
安装MapReduce后jps看不到DataNode进程怎么办?
通常是因为NameNode格式化后,DataNode的clusterID未同步,解决方法是停止所有服务,删除`dfs.datanode.data.dir`和`dfs.namenode.name.dir`指定的目录,重新执行`hdfs namenode -format`,再启动服务。
MapReduce伪分布式与完全分布式安装的主要区别是什么?
伪分布式所有进程运行在同一台机器上,配置文件中的主机名均为localhost,适合学习和测试;完全分布式则分布在多台物理或虚拟机上,需配置`slaves`或`workers`文件指定从节点IP,适合生产环境。
如何验证MapReduce安装是否成功?
最直接的方法是运行Hadoop自带的WordCount示例,将任意文本文件上传至HDFS,执行`hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-.jar wordcount /input /output`,若输出目录生成且包含统计结果,则安装完全成功。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/370603.html