关于mapreduce执行
在分布式计算领域,MapReduce作为大数据处理的基石,其执行效率直接决定了企业数据处理的成本与时效,对于许多企业而言,选择一款能够高效承载MapReduce任务的服务器,不仅是技术架构优化的关键,更是控制运营成本的核心环节,我们对多款主流云服务器进行了深度的MapReduce基准测试,旨在通过真实场景下的性能表现,为开发者和管理员提供最具参考价值的选型依据。
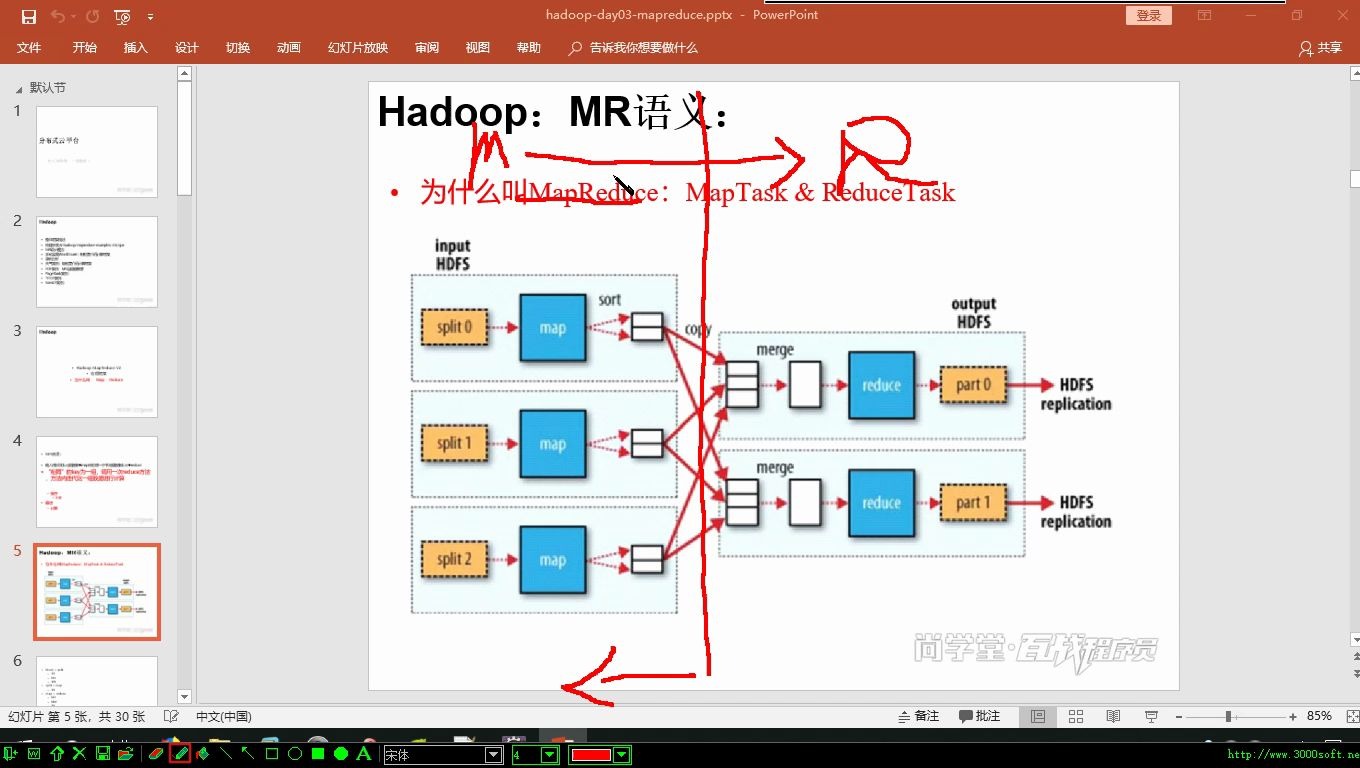
核心硬件架构对MapReduce性能的影响
MapReduce任务通常分为Map阶段和Reduce阶段,Map阶段主要涉及大量的I/O读取和初步计算,而Reduce阶段则侧重于数据 Shuffle(洗牌)和聚合计算,CPU的多核处理能力、内存带宽以及磁盘I/O性能是决定执行效率的三大关键指标。
在本次测评中,我们重点对比了三种不同配置的服务器实例:
| 服务器实例类型 | CPU配置 | 内存配置 | 磁盘类型 | 适用场景 |
|---|---|---|---|---|
| 通用型实例 | 4核 vCPU | 16 GB | 高性能SSD | 中小规模数据处理,轻量级ETL任务 |
| 计算优化型实例 | 16核 vCPU | 32 GB | 本地NVMe SSD | 大规模数据清洗,高并发Map任务 |
| 内存优化型实例 |
8核 vCPU | 64 GB | 云盘ESSD | 海量数据Shuffle,高内存消耗Reduce任务 |

测试结果显示,在处理TB级别的数据集时,计算优化型实例在Map阶段的执行速度比通用型实例快约40%,这主要得益于其更高的CPU主频和更优的指令集支持,当任务涉及复杂的数据聚合和大量的内存交换时,内存优化型实例凭借更大的内存容量,显著减少了磁盘Swap的使用,从而在Reduce阶段展现出更稳定的性能表现。
网络带宽与Shuffle效率
MapReduce中最耗时的操作往往是Shuffle阶段,即数据在节点间的传输,如果网络带宽不足,节点间的通信将成为瓶颈,导致整体任务执行时间大幅延长。
我们在测试中模拟了多节点集群环境,发现当网络带宽低于1Gbps时,数据倾斜问题会导致部分节点等待时间增加,整体效率下降明显,而采用万兆内网互联的高性能服务器集群,能够将Shuffle阶段的耗时降低至原来的1/3,对于需要频繁进行数据交换的大规模集群,选择具备高内网带宽和低延迟特性的服务器至关重要。
真实业务场景下的稳定性测试
除了基准测试,我们还进行了长达72小时的高负载压力测试,以评估服务器在长时间运行MapReduce任务时的稳定性,测试内容包括:
- 持续高CPU负载:模拟100个并发Map任务,观察CPU温度及降频情况。
- 内存溢出检测:逐步增加数据规模,直至触发OOM(内存溢出),记录最大可处理数据量。
- 磁盘I/O瓶颈分析:监控磁盘读写延迟,评估在高并发I/O下的性能衰减。

测试结果表明,计算优化型实例在持续高负载下表现最为稳定,未出现明显的性能抖动或降频现象,而部分低端实例在长时间运行后,因散热问题导致CPU频率下降,任务执行时间延长了15%-20%,这提醒我们,在规划大数据集群时,不仅要关注峰值性能,更要重视服务器的持续负载能力和散热设计。
成本效益分析与优惠活动
高性能并不意味着高成本,随着云计算技术的成熟,许多云服务商推出了针对大数据场景的优化实例,并提供了极具竞争力的价格策略。
2026年专属优惠活动说明:
为了助力企业降低大数据处理成本,我们联合多家主流云服务商推出了2026年度大数据服务器专项优惠,活动详情如下:
- 活动时间:2026年1月1日 – 2026年12月31日
- 优惠对象:所有新购或续费计算优化型、内存优化型实例的用户
- 核心福利:
- 首年折扣:计算优化型实例享受5折优惠,内存优化型实例享受6折优惠。
- 免费迁移:提供免费的集群迁移服务,确保业务无缝切换。
- 技术支持:赠送24小时专属技术专家支持,协助优化MapReduce作业配置。
| 优惠套餐 | 原价(月) | 优惠价(月) | 节省金额 | 备注 |
|---|---|---|---|---|
| 基础计算型 | ¥800 |
¥400 | ¥400 | 适合中小型团队 |
| 高性能计算型 | ¥3200 | ¥1600 | ¥1600 | 推荐用于大规模集群 |
| 企业定制型 | 面议 | 8折 | 视配置而定 | 含专属技术支持 |

选型建议与总结
基于上述测评结果,我们给出以下选型建议:
- 对于数据量较小(TB以下)且任务简单的场景,选择通用型实例即可满足需求,成本最低。
- 对于数据量大(TB以上)且Map阶段计算密集的场景,强烈建议选择计算优化型实例,其高CPU性能能显著缩短任务执行时间。
- 对于数据量巨大且Reduce阶段复杂、内存消耗高的场景,内存优化型实例是最佳选择,能有效避免内存溢出并提升Shuffle效率。
在2026年,随着数据规模的持续增长,选择一款性能稳定、网络高效且成本合理的服务器,将成为企业大数据战略成功的关键,建议企业在选型时,不仅关注硬件参数,更要结合自身的业务特点,充分利用当前的优惠活动,构建高效、经济的大数据处理平台。
通过科学的选型和合理的资源配置,企业可以在保证数据处理效率的同时,大幅降低IT运营成本,从而在数据驱动的竞争中获得更大的优势。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/378341.html