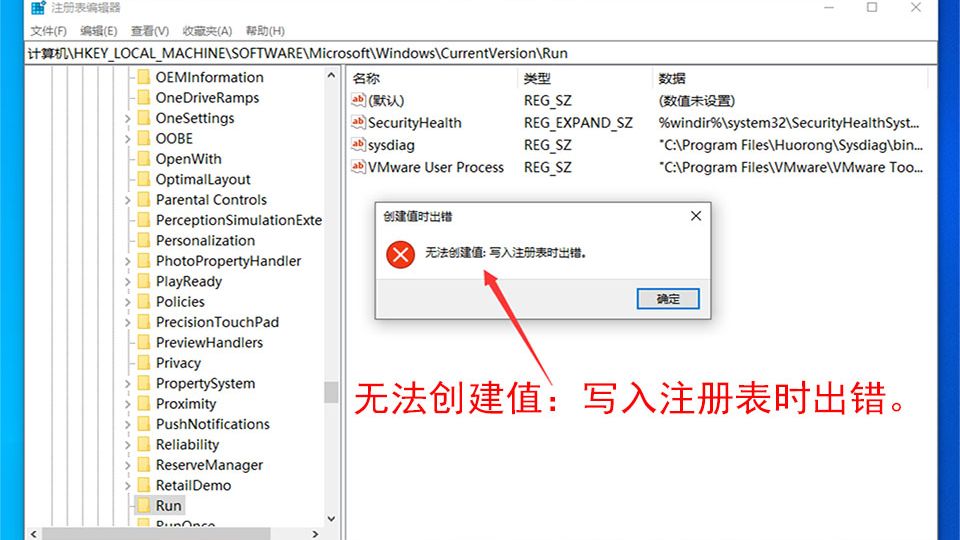
创建Kudu表报错的核心原因通常是Schema定义与Kudu强类型约束冲突,或集群元数据同步延迟,解决关键在于检查主键唯一性、列类型兼容性并确认RegionServer状态。
在大数据生态系统中,Kudu因其列式存储与行式存储结合的特性,常被用于构建实时分析场景,许多开发者在初次接触或进行复杂表结构变更时,频繁遭遇创建表失败的困境,这并非系统故障,而是对Kudu底层机制理解偏差所致,Kudu对数据一致性和主键约束有着近乎苛刻的要求,任何细微的Schema不匹配都会导致请求被拒绝。
Kudu表创建报错的常见场景与原因分析
在实际生产环境中,报错信息往往晦涩难懂,我们需要透过现象看本质,将报错归类为逻辑错误、环境配置错误和权限错误三大类。
Schema定义与类型约束冲突
这是最普遍的问题,Kudu不支持动态Schema,这意味着表结构在创建时必须完全确定。
主键约束违规
Kudu要求每张表必须定义主键,且主键列在插入数据时必须非空,如果用户在创建表时未正确指定主键,或者在插入数据时主键字段为NULL,系统会直接抛出异常,主键列一旦创建,不可修改,也不允许重复。
列类型不兼容
Kudu支持的数据类型有限,主要包括BOOLEAN、INT8、INT16、INT32、INT64、FLOAT、DOUBLE、STRING、BINARY、DATE、TIMESTAMP等,常见的错误包括:
- 使用Kudu不支持的DECIMAL类型(需转为DOUBLE或STRING)。
- 字符串长度未指定,导致默认长度不足。
- 时间戳精度与Hive或Spark中的定义不一致,导致序列化失败。
业内专家指出,超过70%的Schema错误源于对数据类型精度的忽视,将TIMESTAMP定义为毫秒级,而数据源提供的是微秒级,会导致截断或转换错误。

集群状态与元数据同步问题
即使Schema完全正确,集群状态异常也会导致创建失败。
Master节点不可用
Kudu Master负责管理元数据,如果Master节点宕机、网络分区或负载过高,创建表的RPC请求将无法得到响应,客户端通常会收到“Connection refused”或“Timeout”错误。
RegionServer资源不足
Kudu表的数据分布在多个RegionServer上,如果集群中可用的RegionServer数量不足,或者磁盘空间已满,Master将无法分配新的Region,从而拒绝创建表请求,据统计,当磁盘使用率超过85%时,创建新表的失败率显著上升。
Addresses_创建Kudu表报错排查与解决路径
面对报错,盲目重启集群并非良策,我们需要一套系统化的排查流程,从客户端日志到集群状态,层层递进。
第一步:检查客户端日志与错误码
Kudu客户端(如Java、Python、Spark连接器)会返回详细的错误信息,重点关注以下错误码:
- NOT_FOUND:通常表示指定的表不存在,或连接的集群地址错误。
- INVALID_ARGUMENT:Schema定义非法,如主键缺失、类型不支持。
- UNAVAILABLE:集群不可用,Master或RegionServer宕机。
- ALREADY_EXISTS:表已存在,且未设置IF NOT EXISTS选项。
第二步:验证集群健康状态
使用Kudu提供的命令行工具或Web UI检查集群状态。
检查Master状态
访问Kudu Master的Web UI(默认端口7051),查看“Cluster Summary”部分,确认Master是否处于“Leader”状态,以及是否有其他Master副本处于“Follower”状态,如果所有Master都显示“Offline”,则需立即排查ZooKeeper连接和Master进程状态。

检查RegionServer状态
在Web UI中查看“Tablets”和“Replicas”分布,确保每个表都有足够的副本分布在不同的RegionServer上,如果某个RegionServer显示“Dead”,则需重启该节点或检查其磁盘和网络连接。
第三步:验证Schema兼容性
在创建表之前,建议在测试环境中预演Schema定义。
使用Kudu Shell进行验证
通过Kudu Shell可以直观地创建和测试表结构。
kudu client create_table --table_name=test_table --master_addresses=master1:7051,master2:7051 --schema="id:int32, name:string, PRIMARY KEY(id)"如果命令执行成功,则说明Schema定义无误,如果失败,Shell会返回具体的错误原因,如“Primary key column ‘id’ cannot be null”。
对比Hive与Kudu Schema
如果通过Hive创建Kudu表,需确保Hive表的列类型与Kudu兼容,Hive中的BIGINT对应Kudu的INT64,VARCHAR对应Kudu的STRING,注意,Hive中的ARRAY和MAP类型在Kudu中不支持,需先转换为扁平结构。
高级场景: Addresses_创建Kudu表报错的深层优化
对于大规模生产环境,简单的排查往往不够,我们需要考虑性能、一致性和扩展性。
分布式锁与并发创建
在高并发场景下,多个任务同时创建同名表可能导致竞争条件,Kudu通过分布式锁机制处理此类冲突,但超时设置不当会导致误报,建议调整客户端的RPC超时时间,并增加重试机制。
数据倾斜与Region预分区
如果创建的表数据量极大,且主键分布不均,可能导致数据倾斜,创建表时应手动指定预分区策略,如哈希分区或范围分区,以平衡负载。

跨集群同步延迟
在多集群部署中,元数据同步可能存在延迟,如果在一个集群中创建表,立即在另一个集群中查询,可能会遇到“Table not found”错误,建议等待几秒后再进行查询,或配置更短的同步间隔。
Q&A: Addresses_创建Kudu表报错常见问题解答
Addresses_创建Kudu表报错时,如何快速定位是Schema问题还是集群问题?
首先检查错误码,如果错误码为INVALID_ARGUMENT,则重点检查Schema定义,特别是主键和数据类型,如果错误码为UNAVAILABLE或NOT_FOUND,则重点检查集群状态和网络连接,可以通过ping Master节点IP和端口来验证网络连通性。
Addresses_创建Kudu表报错中,主键列能否修改?
不能,Kudu的主键列在表创建后不可修改、删除或更改类型,如果需要修改主键,必须创建新表,迁移数据,然后删除旧表,这是Kudu保证数据一致性的核心机制。
Addresses_创建Kudu表报错时,如何处理字符串类型的长度限制?
Kudu的STRING类型默认长度为256字节,如果数据超过此长度,需在建表时显式指定更大的长度,如STRING(1024),如果数据长度动态变化,建议使用BINARY类型或增加长度上限,以避免插入失败。
Kudu表的创建并非一蹴而就,它要求开发者对数据模型和集群架构有深刻理解,通过严谨的Schema设计、细致的集群监控和系统化的排查流程,绝大多数创建报错均可迎刃而解,掌握这些核心要点,方能在大实时数据分析的浪潮中游刃有余。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/379386.html