AI小模型调用大模型的核心在于利用小模型的低成本与高速度处理常规任务,通过API接口将复杂需求精准路由至大模型,从而实现性能与成本的最佳平衡。
这种架构并非简单的技术拼接,而是当前企业级AI应用落地的标准范式,随着算力成本的压力增大,单纯依赖千亿参数的大模型不仅昂贵,且响应延迟难以满足实时交互需求,通过构建“小模型+大模型”的协同体系,开发者能够在保证用户体验流畅度的同时,显著降低运营支出。

架构原理与核心优势解析
理解这一架构的关键,在于明确小模型与大模型在任务处理链条中的不同角色,小模型通常指参数量在7B至13B之间经过高度蒸馏或量化优化的模型,它们擅长执行分类、提取、格式化等确定性强的任务,大模型则负责逻辑推理、创意生成及复杂问题解决。
业内专家指出,这种分工协作能带来显著的效率提升,具体优势体现在以下三个维度:
- 成本优化:小模型单次推理成本极低,多数情况下可节省超过80%的算力费用。
- 响应速度:小模型推理延迟通常在毫秒级,能够即时处理用户输入,提升交互流畅感。
- 隐私安全:敏感数据可在本地小模型中完成初步清洗与脱敏,无需上传至云端大模型,降低数据泄露风险。
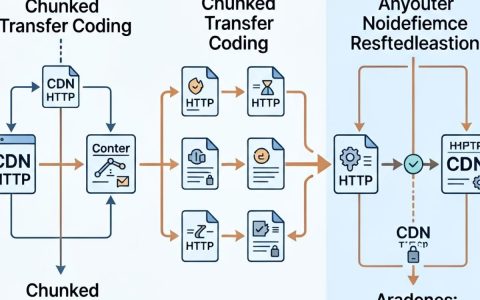
工作流路由机制详解
路由机制是连接小模型与大模型的桥梁,其核心逻辑是根据用户意图的复杂度,动态分配计算资源。
意图识别层
第一步由小模型承担,当用户发起请求时,小模型首先对输入内容进行语义分析,判断任务类型,区分用户是在询问天气、进行闲聊,还是要求撰写一份商业计划书。
决策分发层
根据识别结果,系统执行以下操作:

- 简单任务直接响应:若小模型判断任务简单(如“今天星期几”),直接由小模型生成答案并返回,无需调用大模型。
- 复杂任务向上路由:若任务涉及深层逻辑或创意生成,小模型将提取关键信息,封装为标准化的Prompt(提示词),通过API发送给大模型。
- 结果整合与格式化:大模型返回结果后,小模型可对输出进行二次校验、格式化或翻译,确保最终交付内容符合业务规范。
技术实现路径与API调用
在实际开发中,实现小模型调用大模型主要依赖标准化的API接口,开发者需要搭建一个中间件服务,负责协调两端模型的交互。
主流技术栈选择
目前行业内常见的技术组合包括:
- 小模型端:Llama-3-8B、Qwen-7B或经过量化处理的Phi-3,这些模型可通过vLLM或Ollama等框架高效部署。
- 大模型端:GPT-4o、Claude 3.5 Sonnet或通义千问Max,通过OpenAI API或国内云厂商的API接口接入。
- 路由框架:LangChain、LlamaIndex或自研的规则引擎。
代码实现逻辑示例
以下是一个简化的Python伪代码逻辑,展示如何构建路由判断:
def process_request(user_input):
# 1. 小模型意图识别
intent = small_model.predict(user_input)
# 2. 根据意图分发
if intent == 'simple':
return small_model.generate(user_input)
elif intent == 'complex':
# 3. 构建结构化Prompt
structured_prompt = small_model.extract_key_info(user_input)
# 4. 调用大模型
response = large_model_api.call(structured_prompt)
# 5. 后处理
return small_model.format_output(response)
这种模块化设计使得系统具备极强的扩展性,当小模型升级或大模型供应商变更时,只需替换对应模块,无需重构整个系统。

场景应用与成本控制策略
不同行业对AI调用的需求差异巨大,合理的场景划分是控制成本的关键。
审核场景
在电商客服场景中,约70%的咨询属于常见问题(如物流查询、退换货政策),若全部交由大模型处理,不仅成本高,且响应慢。
- 策略:使用小模型训练一个专用客服助手,处理标准化问答,仅当小模型置信度低于阈值,或用户情绪激动时,才路由至大模型进行人工辅助或高级安抚。
- 效果:据行业共识认为,此类场景下可大幅降低大模型调用频次,从而显著减少月度API账单。
代码生成与文档处理场景
对于程序员而言,代码补全、单元测试生成等任务对准确性要求极高,但上下文窗口需求有限。
- 策略:小模型负责代码片段提取、语法检查及初步补全,大模型仅在涉及架构设计、复杂算法优化时介入。
- 优势:这种分层处理既保证了代码的即时反馈,又确保了复杂逻辑的准确性。
价格敏感型部署方案
对于初创企业或预算有限的团队,混合部署是最佳选择。
| 部署模式 | 小模型角色 | 大模型角色 | 适用场景 |
|---|---|---|---|
| 纯云端API | 无 | 全量处理 | 流量极低,开发初期 |
| 混合云
|
本地部署,处理简单任务 | 云端API,处理复杂任务 | 数据敏感,需平衡成本与性能 |
| 全本地化 | 本地高性能推理 | 本地微调大模型 | 高隐私要求,算力充足 |

值得注意的是,混合云模式是目前多数中大型企业的选择,它允许企业在保证数据安全的前提下,利用云端的强大算力应对峰值流量。
常见问题解答
AI小模型调用大模型的具体操作流程是什么?
首先部署轻量级小模型作为前置过滤器,配置意图识别规则,当用户输入时,小模型判断任务复杂度,若为简单任务,直接返回结果;若为复杂任务,小模型提取关键参数并生成结构化Prompt,通过HTTP请求调用大模型API,大模型返回结果,小模型进行格式校验或后处理后呈现给用户。
小模型调用大模型相比直接调用大模型有哪些成本优势?
主要优势在于减少了大模型的高价调用次数,小模型推理成本通常仅为大模型的1%至5%,通过小模型拦截大量简单查询和预处理数据,可避免大模型被无效请求占用,从而在同等预算下支持更多用户并发,或显著降低月度API支出。
如何确保小模型路由到大模型时的数据一致性?
关键在于Prompt工程标准化与状态管理,小模型在路由时需将上下文、用户ID、任务类型等元数据完整封装至请求体中,大模型接收后,需基于这些元数据保持逻辑连贯,建议在中间件层引入会话状态追踪,确保多轮对话中上下文不丢失,并通过小模型对大模型输出进行二次校验,防止幻觉或格式错误。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/387065.html