大模型全参数微调(Full Fine-Tuning)并非简单的代码运行,而是通过消耗大量算力资源,让模型彻底重写内部权重以适应特定垂直领域任务的最彻底方案,适合拥有充足GPU资源且对领域专业性要求极高的场景。参考2
在人工智能落地应用的深水区,许多开发者容易陷入一个误区:认为微调就是给模型“喂”几本行业手册,全参数微调是微调技术中的“重武器”,它不同于轻量级的LoRA或QLoRA,全参数微调会更新模型中每一个参数,这意味着模型不再是仅仅在表层记忆知识,而是从底层逻辑上重构了对特定领域的理解能力,这种深度介入带来的收益是巨大的,但成本同样高昂,业内专家指出,对于医疗、法律、金融等容错率极低且专业术语密集的垂直领域,全参数微调依然是建立核心竞争力的首选路径。
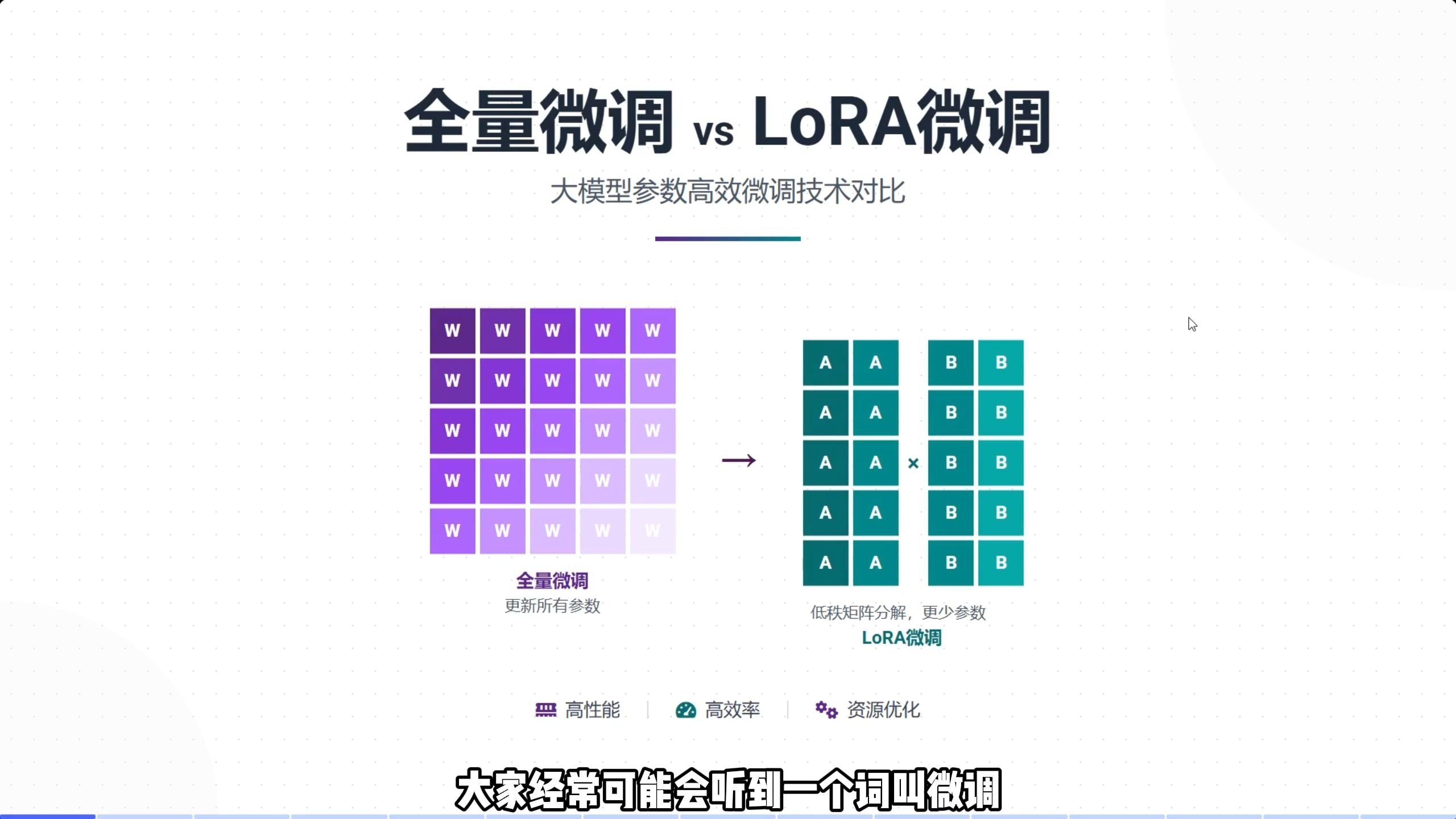
全参数微调的核心逻辑与适用场景
要理解为什么选择全参数微调,首先要明白它与参数高效微调(PEFT)的本质区别,PEFT技术通过冻结大部分权重,只训练少量适配器,极大地降低了显存需求,这种“打补丁”的方式在处理需要深度逻辑推理或复杂指令遵循的任务时,往往显得力不从心,全参数微调则不同,它允许模型在训练过程中自由调整所有层的权重,从而获得更强的泛化能力和更精准的知识嵌入。参考2
何时必须选择全参数微调
并非所有项目都需要动用全参数微调,在实际工程中,我们需要根据数据规模和任务复杂度进行决策。
- 数据量极大:当你的领域数据达到数万甚至百万级别,且包含大量非结构化文本时,全参数微调能更好地捕捉数据分布。
- 任务极度垂直:让通用大模型掌握某家医院的内部诊疗规范,或者某律所的特定合同审查逻辑,通用模型在这些场景下容易产生“幻觉”或逻辑偏差,全参数微调能显著降低此类风险。
- 算力资源充裕:这是最现实的门槛,全参数微调需要巨大的显存支持,对于7B(70亿参数)模型,通常需要多张A100或H800显卡进行分布式训练。
与LoRA微调的性能对比

为了更直观地展示差异,我们来看一个典型场景下的表现对比,在同一个法律问答数据集上,全参数微调的模型在法条引用的准确率和逻辑推导的严密性上,通常优于LoRA微调模型,据行业共识认为,虽然LoRA在通用对话场景中表现优异,但在需要高精度专业知识的任务中,全参数微调的优势更为明显。
| 特性维度 | 全参数微调 (Full FT) | LoRA/QLoRA微调 |
|---|---|---|
| 显存占用 | 极高,需多卡分布式 | 较低,单卡或双卡可运行 |
| 训练速度 | 慢,需数天至数周 | 快,通常数小时至一天 |
| 模型体积 | 原始模型大小 | 仅保存适配器权重,极小 |
| 专业知识吸收 | 深度重构,泛化性强 | 表层记忆,易受基座限制 |
| 适用场景 | 核心业务、高专业度领域 | 快速原型、通用对话优化 |
全参数微调的实操全流程解析
理论再完美,落地才是关键,全参数微调的流程复杂,涉及数据准备、环境配置、训练执行和评估部署四个主要阶段,以下步骤基于当前主流的大语言模型训练框架(如LLaMA-Factory或DeepSpeed)整理而成。
第一步:高质量数据构建
数据质量直接决定微调效果,业内普遍认为,1000条高质量指令数据胜过10万条低质数据。
- 数据清洗:去除重复、乱码、无关广告内容,使用正则表达式或专门的清洗工具处理文本。
- 格式转换

:将数据转换为模型所需的JSON格式,通常包含
instruction(指令)、input(输入)和output(输出)三个字段。 - 构造思维链(CoT):对于复杂任务,不要只给答案,在
output字段中,加入详细的推理步骤,在数学解题中,展示每一步的计算逻辑,而不仅仅是最终结果,这能显著提升模型的推理能力。

第二步:环境搭建与参数配置
全参数微调对硬件要求苛刻,建议至少准备4张A100 80G显卡进行分布式训练。
- 框架选择:推荐使用
LLaMA-Factory,它封装了DeepSpeed,简化了分布式训练的配置。 - 关键参数设置:
learning_rate(学习率):通常设置在1e-5到5e-5之间,过大会导致模型崩溃(灾难性遗忘),过小则训练收敛慢。batch_size:根据显存大小调整,尽量填满显存以提高效率。epochs(训练轮数):通常为3-5轮,过多轮数会导致过拟合,模型在训练集上表现完美,但在测试集上失效。warmup_ratio:建议设置为1,即前10%的训练步骤用于预热学习率,稳定训练过程。
第三步:启动训练与监控
使用DeepSpeed进行分布式加速是标准操作,启动命令通常如下:
llamafactory-cli train
--model_name_or_path /path/to/base/model
--dataset your_dataset
--do_train true
--stage sft
--finetuning_type full
--output_dir ./output_full_ft
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--learning_rate 2.0e-5
--num_train_epochs 3.0
--deepspeed ds_config.json
在训练过程中,务必实时监控loss(损失函数)曲线,如果loss突然飙升,说明学习率过大或数据存在异常,需立即停止训练并调整参数。
评估优化与部署策略
训练结束并非终点,评估和优化才是拉开差距的关键。
自动化评估指标

不要仅凭肉眼判断模型好坏,使用自动化评估工具,如C-Eval或CMMLU的子集,或者构建专属的领域测试集,重点关注以下指标:
- BLEU/ROUGE分数:衡量生成文本与标准答案的重合度。
- 人工评估:邀请领域专家对模型回答进行盲测,打分维度包括准确性、逻辑性、流畅度。
防止灾难性遗忘
全参数微调最大的风险是“灾难性遗忘”,即模型学会了新知识,却忘记了通用知识,为了解决这个问题,建议在训练数据中混合20%-30%的通用高质量数据(如C4、Wikipedia等),这种混合训练策略能保持模型的通用能力,同时增强领域专业性。
模型量化与部署
全参数微调后的模型体积巨大,直接部署成本高,业内通常采用GPTQ或AWQ量化技术,将模型精度从FP16降至INT4或INT8,虽然精度会有轻微损失,但在大多数垂直领域应用中,这种损失是可以接受的,且能大幅降低推理成本。
常见疑问解答
大模型全参数微调FT需要多少显存?
显存需求与模型参数量成正比,对于7B参数模型,全参数微调通常需要至少24GB显存(如果使用混合精度训练且配合梯度累积),但为了获得稳定的训练速度和批量大小,建议使用40GB或80GB显存的显卡,对于更大的70B参数模型,则需要多卡集群支持,单卡显存需求不再是唯一瓶颈,而是需要关注卡间通信带宽。
全参数微调FT和LoRA哪个效果更好?
在通用任务中,LoRA的效果往往接近全参数微调,且性价比极高,但在需要深度领域知识嵌入的任务中,全参数微调效果更好,因为LoRA只能修改局部权重,难以改变模型的基础认知结构,如果预算允许且对专业性要求极高,全参数微调是更优选择。
全参数微调FT训练失败常见原因是什么?
训练失败通常由三个原因导致:一是学习率设置不当,导致Loss不降反升;二是数据质量差,存在大量噪声或格式错误;三是显存溢出(OOM),此时需减小Batch Size或增加梯度累积步数。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/394395.html