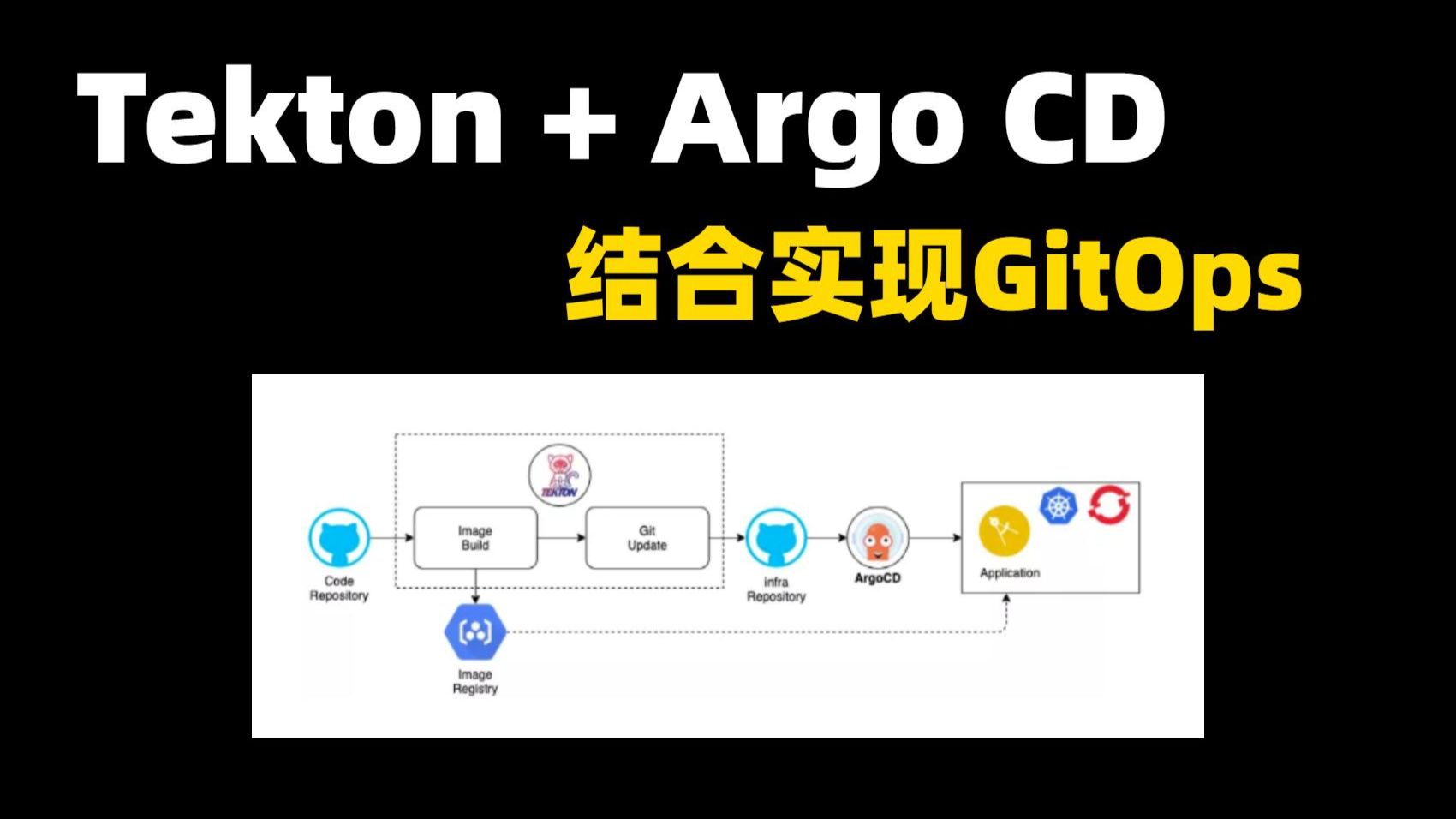
大模型部署采用Tekton流水线,能实现从代码提交到模型推理服务上线的全自动化闭环,显著降低运维复杂度并提升迭代效率。
在人工智能从实验走向生产的深水区,传统的“手动打包镜像+人工部署”模式已无法满足大模型快速迭代的需求,Tekton作为基于Kubernetes的云原生CI/CD框架,凭借其声明式API和强大的扩展性,成为大模型工程化落地的首选方案,它不仅仅是一个工具链,更是一套标准化的模型交付基础设施。
为什么选择Tekton构建大模型部署流水线
业内专家指出,大模型部署的核心痛点在于环境复杂性和资源调度难度,相比Jenkins等老牌工具,Tekton具有原生Kubernetes亲和力,能够更精细地控制GPU资源分配。
云原生架构的优势对比
传统CI/CD工具往往需要额外的服务器节点来运行构建任务,而Tekton直接在K8s集群内部署Pod执行任务,这种架构带来了几个关键优势:
- 资源隔离性:每个流水线任务(Task)运行在独立的Pod中,避免不同模型训练或部署任务之间的资源争抢。
- 弹性伸缩:依托K8s的调度能力,当需要大规模并行部署多个模型变体时,Tekton能自动创建对应的执行Pod。
- 状态无感:流水线执行状态存储在K8s API Server中,即使节点重启,任务状态也不会丢失,保证了生产环境的稳定性。
与Kubeflow Pipelines的选型考量
虽然Kubeflow也是MLOps的主流选择,但在纯部署场景下,Tekton更具灵活性,Kubeflow偏向于模型训练全流程管理,而Tekton专注于CI/CD环节,对于已经拥有成熟K8s基础设施的企业,引入Tekton无需额外部署庞大的Kubeflow组件栈,降低了系统耦合度。
Tekton大模型部署流水线实战架构
构建一个完整的大模型部署流水线,通常包含代码扫描、模型转换、镜像构建、安全扫描和部署发布五个核心阶段。

代码与模型资产检查
在流水线启动初期,需要对模型权重文件和推理代码进行静态检查,这一步至关重要,因为大模型权重文件通常高达数十GB,任何细微的损坏都会导致后续步骤失败。
具体操作步骤
- 触发机制:通过GitLab或GitHub的Webhook触发流水线,监听
main分支的提交或Release标签创建事件。 - 代码扫描:使用
trivy或sonarqube扫描Python推理代码,检测依赖漏洞。 - 权重校验:编写自定义Task,使用Python脚本计算模型权重的SHA256哈希值,并与预置的基准值比对,确保模型未发生篡改。
模型格式转换与优化
大模型原始格式(如PyTorch的.pt或.bin)通常不适合直接部署,需要转换为ONNX或TensorRT格式,以提升推理速度。
转换流程细节
- 环境准备:创建一个包含CUDA、cuDNN和特定版本PyTorch的基础镜像。
- 转换执行:调用
optimum或transformers库中的转换脚本,将Llama-3模型转换为INT8量化版本,以减少显存占用。 - 资源控制:在Task定义中明确指定
resources.limits.nvidia.com/gpu: 1,确保转换任务只占用单卡资源,避免影响集群其他服务。
Docker镜像构建与安全加固
模型转换完成后,需要将推理代码、优化后的模型权重以及运行时环境打包成Docker镜像。
多阶段构建策略
为了减小镜像体积,建议采用多阶段构建(Multi-stage Build):
- 构建阶段:使用包含编译工具的大型镜像进行依赖安装和模型转换。
- 运行阶段:仅复制必要的二进制文件、模型权重和推理服务代码到一个精简的基础镜像(如

python:3.10-slim
vllm官方镜像)。 - 安全扫描:在镜像推送前,运行
trivy image命令,检查是否存在高危CVE漏洞,如果存在严重漏洞,流水线应自动中断,防止不安全的镜像流入生产环境。

流水线配置与关键参数调优
在实际操作中,Tekton的配置细节直接决定了部署的成功率和效率。
资源配额管理
大模型部署对显存和内存要求极高,在Task和Pipeline的定义文件中,必须精确设置资源请求(requests)和限制(limits)。
- 显存限制:设置
nvidia.com/gpu: 1或更高,具体取决于模型参数量。 - 内存限制:对于70B参数量的模型,建议设置至少
64Gi的内存限制,以防OOM(内存溢出)错误。
缓存机制的应用
为了加速流水线执行,可以利用Tekton的缓存功能,对于不常变化的基础镜像层或依赖包,启用缓存可以跳过重复下载步骤,据行业共识认为,合理使用缓存可将流水线平均执行时间缩短30%以上。
错误处理与重试机制
网络波动或GPU驱动临时故障可能导致任务失败,在Task定义中配置retries字段,设置自动重试次数(如3次)和退避策略,能提高流水线的鲁棒性。
常见部署场景与价格考量
不同规模的企业在部署大模型时,面临的挑战和成本结构差异巨大。
中小企业私有化部署
对于预算有限的中小企业,通常选择7B-13B参数量的开源模型,Tekton流水线可以自动化完成从HuggingFace拉取模型到本地K8s集群部署的全过程,这种方式避免了高昂的API调用费用,且数据完全私有化。
大型企业混合云部署
大型企业往往采用混合云架构,核心数据留在本地,推理服务可弹性扩展到公有云,Tekton的跨集群管理能力在此场景下发挥重要作用,通过配置不同的

ClusterTask,实现模型在本地和云端的一致性部署。
成本优化策略
- Spot实例利用:在构建和测试阶段,使用K8s的Spot实例(竞价实例),可大幅降低计算成本。
- 模型量化:通过INT8或INT4量化,减少显存需求,从而允许在更低配置的GPU上运行,直接降低硬件投入。
大模型部署Tekton流水线Q&A
大模型部署Tekton流水线如何实现自动回滚?
Tekton本身不直接管理K8s资源的版本,但可以通过与Argo Rollouts或Flagger集成实现自动回滚,在流水线最后阶段,部署任务不仅执行kubectl apply,还触发渐进式发布策略,如果监控指标(如错误率、延迟)超过阈值,Argo会自动将流量切回上一版本,并通知Tekton流水线记录失败原因,触发人工审核或自动修复流程。
大模型部署Tekton流水线如何处理大体积模型权重?
直接通过Git传输大权重文件效率极低且容易超时,最佳实践是将模型权重存储在对象存储(如MinIO、AWS S3)或模型仓库(如HuggingFace Hub)中,Tekton流水线中的下载Task通过挂载Volume或使用云原生存储驱动(如CSI)直接拉取权重,而非通过Git克隆,这种方式支持断点续传和并行下载,显著提升了大文件传输的稳定性。
大模型部署Tekton流水线与Jenkins相比有何核心区别?
核心区别在于执行环境和资源调度方式,Jenkins基于Master-Agent架构,Agent节点需要预先配置好所有依赖环境,扩展性受限且维护成本高,Tekton基于Kubernetes原生Pod,每个任务都是独立的、无状态的容器,随用随建,用完即毁,这种差异使得Tekton在处理大模型部署这种需要动态GPU资源、环境隔离要求高的场景时,具备更高的灵活性和资源利用率。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/396026.html