大模型的对数似然(Log Likelihood)是衡量模型预测概率分布与真实数据分布之间差异的核心指标,数值越高代表模型对数据的拟合度越好,即模型越“确信”其生成的答案是正确的。
在理解大语言模型(LLM)时,我们常听到“损失函数”或“准确率”这些词,但对数似然才是模型在训练底层真正优化的目标,它回答了这样一个问题:当模型看到某个输入时,它认为下一个词出现的概率有多大?如果模型给出的概率接近真实情况,对数似然值就会很高。
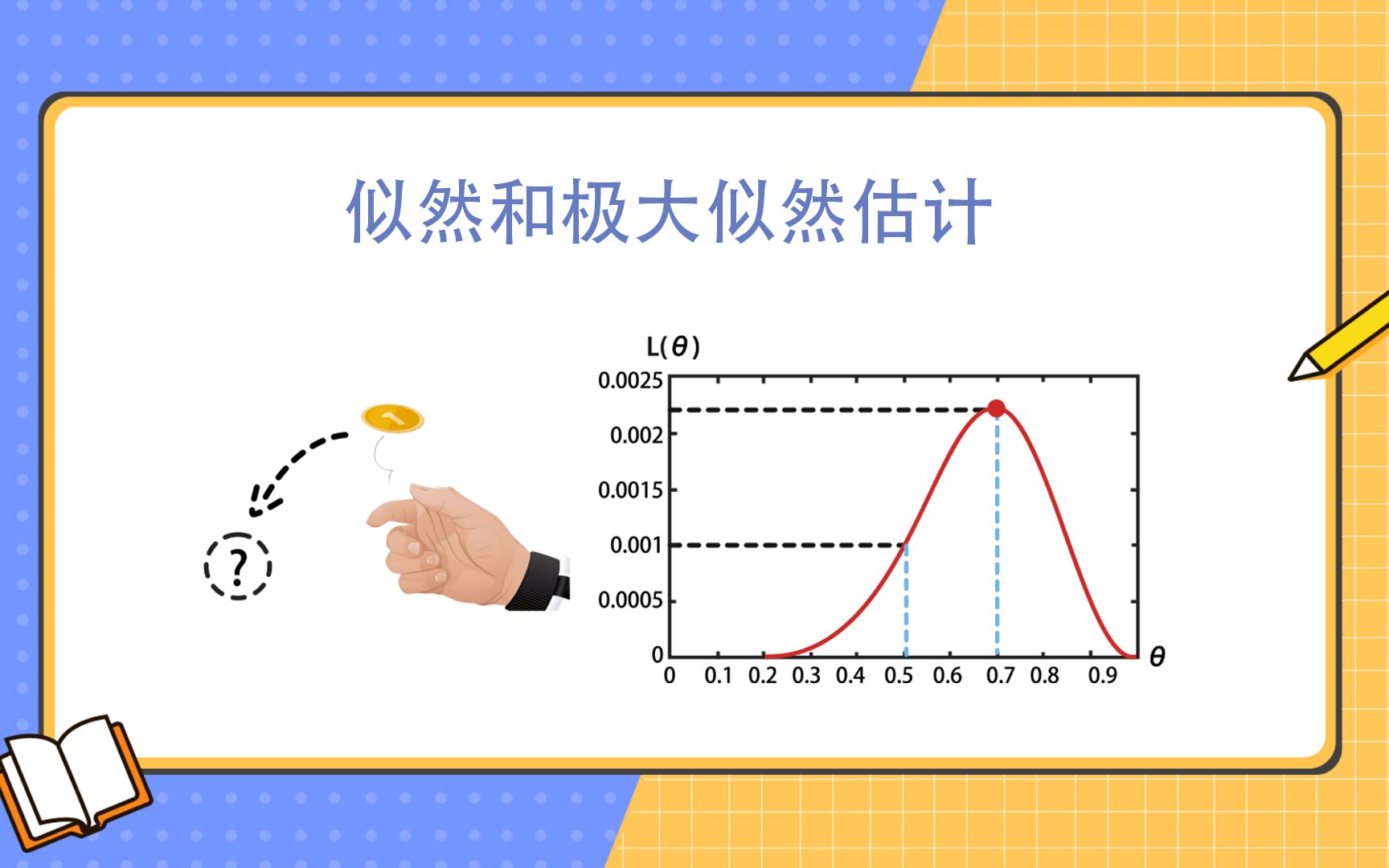
什么是对数似然及其核心逻辑
对数似然并非一个孤立的概念,它是统计学中极大似然估计在机器学习领域的具体应用,在大模型训练初期,模型就像一个刚出生的婴儿,完全随机地猜测下一个字是什么,随着训练进行,它通过调整数以千亿计的参数,逐渐学会预测。
从概率到对数的演变
想象你在猜拳,第一次你完全瞎猜,第二次你根据对手的习惯调整策略,对数似然就是那个量化你“猜得准不准”的尺子。
- 似然值(Likelihood):模型预测当前词的概率连乘积,由于概率值通常在0到1之间,连乘会导致数值极小,甚至溢出计算机的浮点数限制。
- 对数变换(Log):为了解决数值过小问题,数学家引入了对数运算,对数函数是单调递增的,这意味着似然值越大,对数似然值也越大,且能将乘法转化为加法,极大简化计算。
- 负对数似然(NLL):在优化过程中,我们通常希望最小化损失,实际训练中常用的是负对数似然,NLL越小,模型表现越好;反之,对数似然越大,模型越优。
业内专家指出,这种转换不仅解决了数值稳定性问题,还使得梯度下降算法能够更平稳地收敛。
为什么它比准确率更重要?
很多人误以为“准确率”是衡量大模型的唯一标准,但在训练阶段,对数似然才是王道。
- 概率信息的保留:准确率只关心“猜对”还是“猜错”,忽略了“猜得有多准”,模型以99%的概率猜对,和以51%的概率猜对,在准确率上都是1,但在对数似然上差异巨大。
- 平滑的梯度信号:对数似然提供了连续的梯度信号,帮助模型在参数空间中微调,准确率是离散的,无法直接用于反向传播。
- 捕捉不确定性:对数似然能反映模型的不确定性,当模型对答案犹豫不决时,对数似然值会下降,这为后续的温度参数(Temperature)调整提供了依据。

对数似然在模型评估中的实战应用
理解概念后,我们需要知道如何在实际场景中利用这一指标,它不仅是训练时的监控工具,更是评估模型能力的关键维度。
训练过程中的监控指标
在微调或预训练大模型时,开发者会实时观察训练集和验证集的对数似然变化。
- 过拟合判断:如果训练集的对数似然持续上升(损失下降),而验证集的对数似然开始下降(损失上升),说明模型开始死记硬背训练数据,失去了泛化能力。
- 学习率调整:当对数似然出现剧烈波动时,通常意味着学习率过大,需要降低步长以稳定训练。
- 早停机制(Early Stopping):当验证集的对数似然在连续N个epoch内不再提升时,停止训练,保存最佳模型。
模型选择与对比分析
面对众多开源模型,如何判断哪个更适合你的业务场景?对数似然提供了客观的量化依据。
| 模型类型 | 对数似然表现特征 | 适用场景 |
|---|---|---|
| 基础预训练模型 | 数值极高,泛化能力强 | 作为基座,用于各种下游任务 |
| 指令微调模型 | 数值略低于基座,但指令遵循性好 | 客服、问答、内容生成 |
| 强化学习模型 | 数值可能波动,但人类偏好得分高 | 需要高度对齐人类价值观的场景 |

据工信部数据,近年来国内大模型评测中,单纯依赖困惑度(Perplexity,即对数似然的指数形式)的排名与实际用户体验的相关性正在减弱,但它在底层能力评估中仍具参考价值。
具体场景下的优化策略
如果你发现模型在特定领域表现不佳,可以通过调整对数似然相关的参数来优化。
- 数据清洗:低质量数据会导致对数似然无法有效收敛,使用去重、过滤低质文本等手段,能显著提升训练效率。
- 上下文长度调整:过长的上下文可能导致注意力分散,降低对数似然,尝试分段处理或优化注意力机制。
- 温度参数调节:在推理阶段,降低温度(Temperature)可以提高高概率词的权重,从而在特定任务中提升对数似然表现。
常见误区与专业解读
尽管对数似然至关重要,但公众和部分开发者对其存在误解,澄清这些误区,有助于更准确地评估大模型。
对数似然越高,模型越智能
这是一个典型的线性思维误区,对数似然衡量的是“概率拟合度”,而非“逻辑正确性”。
- 幻觉问题:模型可能以极高的置信度(高对数似然)生成错误的事实,一本正经地胡说八道。
- 安全性对齐:经过RLHF(人类反馈强化学习)的模型,其原始对数似然可能不如未经对齐的模型,因为它学会了拒绝回答某些问题,这在统计上表现为对某些答案的概率降低。
行业共识认为,对数似然应作为辅助指标,结合人工评估、基准测试(Benchmark)等多维度指标综合判断。
不同模型间的对数似然可直接比较
直接比较不同架构、不同训练数据的模型的对数似然值是没有意义的。
- 数据分布差异:训练数据的质量和分布直接影响对数似然,在通用语料上表现好的模型,在专业领域(如医疗、法律)的对数似然可能较低。
- 评估集偏差:评估集的选择至关重要,使用与训练数据重叠的评估集会导致对数似然虚高,产生“数据泄露”假象。

未来趋势:超越对数似然
随着大模型技术的发展,对数似然的地位也在演变。
从概率到语义理解
未来的评估可能不再仅仅关注词级别的概率,而是转向语义级别的匹配,评估模型生成的答案是否在语义上与标准答案一致,而不仅仅是字面匹配。
多模态对数似然
在多模态大模型中,对数似然的概念扩展到图像、音频等模态,如何统一不同模态的概率空间,是当前的研究热点。
动态评估机制
静态的对数似然可能无法反映模型在动态交互中的表现,未来的评估将更注重实时交互中的概率变化,以及模型在长对话中的注意力分配效率。
Q&A:关于对数似然的常见问题
如何计算大模型的对数似然?
计算过程通常分为三步:将文本分词并转换为模型可接受的ID序列;通过模型前向传播,获取每个token的条件概率分布;取所有token概率的对数并求和,具体公式为:$LL = sum_{i=1}^{n} log P(xi | x{<i})$,在代码实现中,可使用PyTorch或TensorFlow的交叉熵损失函数,并取负值来近似计算。
对数似然与困惑度(Perplexity)有什么关系?
困惑度是对数似然的指数形式,公式为 $PPL = 2^{-LL}$(以2为底)或 $e^{-LL}$(以e为底),困惑度更直观地表示模型在预测下一个词时的“不确定性”,困惑度越低,模型越确定,表现越好,两者本质相同,困惑度在自然语言处理领域更为常用,因为它具有更直观的解释性,如“困惑度为10”意味着模型在10个词中均匀随机选择正确答案。
为什么我的模型对数似然很高,但回答质量很差?
这通常是因为模型过拟合了训练数据,或者评估集与训练集存在重叠,对数似然仅衡量词级概率,不衡量逻辑连贯性或事实准确性,建议结合人工评估和自动化基准测试(如MMLU、C-Eval)来全面评估模型质量,而非单一依赖对数似然指标。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/406600.html