大模型部署Helm Chart的核心价值在于通过标准化模板实现一键式容器化编排,大幅降低Kubernetes集群的管理复杂度,是2026年企业级AI基础设施落地的首选方案。
将大型语言模型(LLM)从代码仓库迁移到生产环境,往往伴随着复杂的依赖配置、资源调度以及版本迭代问题,Helm作为Kubernetes的包管理工具,通过Chart模板将应用定义、配置和依赖打包,解决了“环境不一致”这一痛点,对于运维团队而言,这意味着不再需要手动编写冗长的YAML文件,而是通过参数化模板快速部署模型服务。
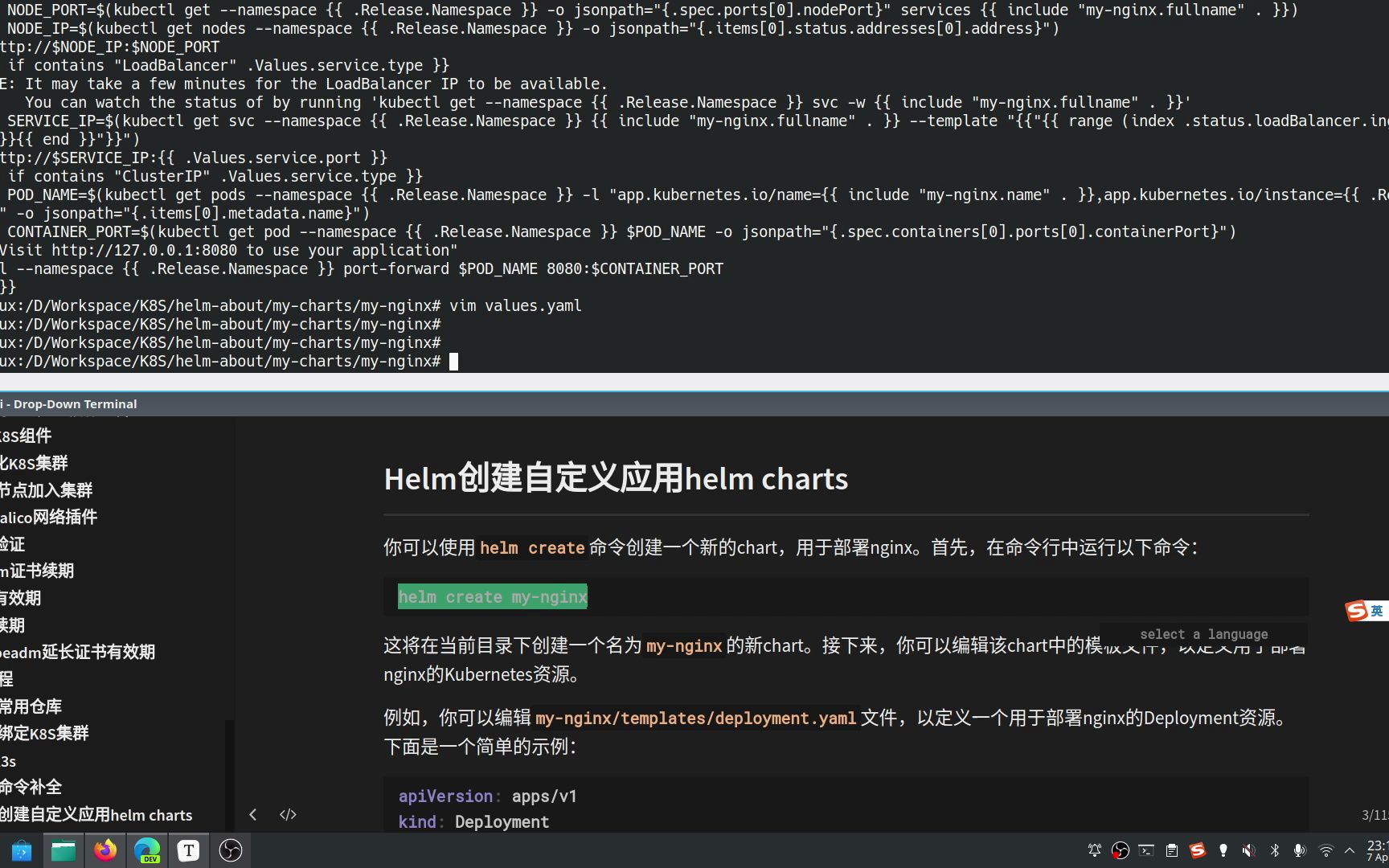
为什么选择Helm Chart进行大模型部署
在2026年的技术语境下,大模型推理服务的高并发和资源消耗特性,使得传统的手动部署方式难以维持稳定性,Helm Chart提供了一种声明式的部署架构,让基础设施即代码(IaC)的理念在AI领域得以落地。
标准化与可重复性优势
不同的大模型对GPU显存、CPU核心数以及网络带宽的要求差异巨大,Helm Chart通过Values文件将可变参数与固定逻辑分离。
- 参数解耦:模型权重路径、推理引擎版本、批处理大小等关键指标均可在Values文件中配置,无需修改底层模板。
- 版本控制:每一次Chart的更新都对应一个明确的版本号,便于回滚和审计。
- 环境一致性:开发、测试、生产环境使用同一套Chart,仅通过不同的Values文件区分,消除了“在我机器上能跑”的幽灵问题。
业内专家指出,采用标准化模板后,新模型上线的平均耗时从数天缩短至小时级,显著提升了迭代效率。
资源隔离与弹性伸缩
大模型推理服务对资源敏感度极高,Helm Chart能够精细定义Resource Requests和Limits,确保GPU资源不被其他任务抢占。
- GPU调度优化:通过注解(Annotations)指定NVIDIA GPU驱动版本及显存预留量,配合Kubernetes的设备插件,实现硬件资源的精准分配。
- HPA自动伸缩:结合Horizontal Pod Autoscaler,根据QPS(每秒查询率)或显存利用率自动增减Pod数量,应对流量高峰。
- 亲和性配置:通过Node Affinity将模型Pod调度到配备特定型号GPU的节点上,避免资源碎片化。

大模型部署Helm Chart实战指南
构建一个高效的大模型Helm Chart需要遵循模块化设计原则,以下以部署一个基于vLLM框架的LLM推理服务为例,拆解核心步骤。
Chart目录结构设计
清晰的目录结构是维护性的基础,一个标准的LLM部署Chart应包含以下结构:
my-llm-chart/ ├── Chart.yaml # 元数据:名称、版本、依赖 ├── values.yaml # 默认配置参数 ├── templates/ │ ├── deployment.yaml # 部署模板 │ ├── service.yaml # 服务暴露模板 │ ├── hpa.yaml # 自动伸缩模板 │ └── configmap.yaml # 配置文件挂载 └── charts/ # 子依赖(如Redis缓存)
核心模板编写要点
在deployment.yaml中,需重点关注容器镜像、环境变量及存储卷挂载。
- 镜像管理:使用
{{ .Values.image.repository }}:{{ .Values.image.tag }}语法,确保镜像源和标签可配置。 - 环境变量注入:将模型加载路径、并发线程数等敏感或易变参数通过ConfigMap或Secret注入,避免硬编码。
- 健康检查:配置Liveness和Readiness探针,探针URL指向模型服务的健康检查接口,确保流量仅路由到就绪的Pod。
GPU资源限制配置示例
在YAML模板中,必须显式声明GPU资源,否则Kubernetes调度器无法正确分配节点。
resources:
requests:
nvidia.com/gpu: "1"
memory: "32Gi"
cpu: "4"
limits:
nvidia.com/gpu: "1"
memory: "32Gi"
cpu: "4"

常见部署场景与对比分析
在实际业务中,不同的业务场景对大模型部署的要求截然不同,选择合适的Chart配置策略至关重要。
高并发推理 vs 低延迟交互
| 场景特征 | 高并发推理(如客服批量处理) | 低延迟交互(如实时对话助手) |
|---|---|---|
| 核心指标 | 吞吐量(Throughput) | 首字延迟(TTFT) |
| Batch Size | 较大(如128/256) | 较小(如1/4) |
| 并发策略 | 多Pod横向扩展 | 单Pod高配,减少网络跳转 |
| 缓存机制 | 依赖KV Cache共享 | 本地内存缓存为主 |
| 推荐配置 | 增加Replicas,优化GPU利用率 | 预留更多显存,启用PagedAttention |
私有化部署 vs 混合云架构
对于数据敏感型企业,私有化部署Helm Chart是主流选择,通过配置私有镜像仓库地址和内部存储卷,确保模型权重和数据不出域,而在混合云场景下,Chart需支持动态挂载外部存储(如NFS或Ceph),并配置Service Mesh以实现跨云流量调度。
据统计,采用混合云架构的企业中,较大比例利用Helm Chart实现了多云环境的统一运维管理,降低了跨平台适配成本。

大模型部署Helm Chart常见问题解答
大模型部署Helm Chart价格如何计算?
Helm Chart本身是开源免费的,但其背后的基础设施成本高昂,主要费用包括GPU服务器租赁或购买成本、存储费用以及运维人力成本,对于中小企业,大模型部署Helm Chart价格往往集中在GPU实例费用上,单张A100显卡的月租金可能在数千元级别,而大规模集群则需要数十万级的月度支出,还需考虑高可用架构带来的冗余成本,通常建议预留20%-30%的资源余量以应对故障切换。
大模型部署Helm Chart与Docker Compose有何区别?
Docker Compose适用于单机开发环境,管理简单但缺乏弹性伸缩和故障自愈能力,Helm Chart基于Kubernetes,支持多节点集群管理、滚动更新、服务发现和自动重启,对于生产环境,尤其是需要处理高并发和大显存需求的大模型服务,大模型部署Helm Chart提供了必要的企业级特性,Docker Compose无法实现跨节点的资源调度,而Helm Chart可以精确控制Pod在哪个GPU节点上运行,这是两者最本质的区别。
如何解决大模型部署Helm Chart中的显存溢出问题?
显存溢出(OOM)是常见错误,检查values.yaml中的memory和nvidia.com/gpu限制是否设置合理,确保Request小于Limit,优化模型加载策略,使用量化版本(如INT8/FP16)减少显存占用,第三,调整批处理大小,过大的Batch Size会导致显存瞬间飙升,启用Kubernetes的Eviction机制,当节点资源紧张时,自动驱逐低优先级Pod,保护核心推理服务。
通过精心设计的Helm Chart,企业可以将大模型的部署复杂度降低一个数量级,实现从“人工运维”到“自动化编排”的跨越,在2026年的AI基础设施建设中,掌握Helm Chart不仅是技术能力的体现,更是降本增效的关键手段。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/396196.html