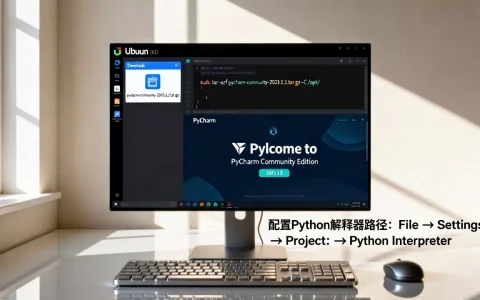
KoboldCpp 的下载与安装核心在于访问其 GitHub 官方仓库获取最新 Release 版本,解压后运行可执行文件即可,无需复杂配置即可在本地运行大语言模型。
对于许多希望将大语言模型(LLM)部署到个人电脑上的用户来说,KoboldCpp 是一个极具吸引力的选择,它以其轻量级、高兼容性和对多种后端(如 llama.cpp、Metal、CUDA)的支持而闻名,与复杂的服务器端部署不同,KoboldCpp 更像是一个“开箱即用”的桌面应用,让普通用户也能轻松体验本地 AI 的魅力。
KoboldCpp 下载渠道与版本选择策略
在开始安装之前,明确从哪里获取软件以及选择哪个版本至关重要,错误的来源可能导致安全风险,而错误的版本可能导致性能瓶颈。
官方渠道优先原则
业内专家指出,确保软件来源的安全性是第一步,KoboldCpp 是开源项目,其唯一的官方代码托管平台是 GitHub,请务必访问 KoboldAI/KoboldCpp 的 Releases 页面进行下载,任何第三方网站提供的安装包都可能被篡改,植入恶意代码或挖矿程序。
操作系统适配与版本对比
不同操作系统用户需要选择对应的构建版本,以下是主流平台的下载指南:
-
Windows 用户:
Intel/AMD 处理器用户
直接下载带有 `windows` 或 `win` 标识的压缩包,通常推荐下载 `KoboldCpp-win-x64.zip`,这类版本针对 x86_64 架构进行了优化,支持通过 llama.cpp 后端调用 CPU 或 NVIDIA GPU。
Apple Silicon (M1/M2/M3) 用户
如果你使用的是 Mac 电脑,务必寻找带有 `macos` 或 `apple` 标识的版本,特别是针对 Metal 后端优化的版本,Metal 是苹果芯片运行大模型最高效的方式,能显著降低延迟并减少内存占用。
Linux 用户:
通用 Linux 发行版
下载 `linux-x64` 版本,Linux 用户通常具备更强的命令行操作能力,因此官方也提供了编译好的二进制文件,确保你的系统安装了必要的依赖库,如 `libstdc++`。

版本迭代与稳定性权衡
在 GitHub Releases 页面,你会看到 Latest(最新)和 Pre-release(预发布)两个主要标签。
- Latest 版本:经过测试,稳定性较高,适合大多数日常使用场景。
- Pre-release 版本:包含最新的功能特性或对特定模型的支持,但可能存在未发现的 Bug,如果你是模型爱好者,喜欢尝试最新的 Llama 3.1 或 Qwen 2.5 等模型,建议优先关注 Pre-release 版本,因为它往往能更快适配新的量化格式。
KoboldCpp 安装步骤与运行环境配置
下载完成后,安装过程实际上非常简单,主要涉及解压和权限设置。
Windows 平台安装实操
- 解压文件:将下载的
.zip文件解压到一个路径中不包含特殊字符或过长中文的文件夹中。D:AIKoboldCpp是一个理想的路径。 - 首次运行:双击
KoboldCpp.exe,软件会自动检查并下载必要的依赖组件(如 llama.cpp 的核心库),如果网络不通畅,这一步可能会超时。 - 网络代理设置:对于国内用户,如果自动下载依赖失败,需要在软件设置中配置 HTTP 代理,或者手动从镜像源下载依赖包放入指定目录,这是许多新手遇到的第一个障碍,务必注意网络连通性。
macOS 平台安装实操
- 权限授予:由于 Apple 的安全机制,首次运行可能需要你前往“系统设置” -> “隐私与安全性”,允许从“已识别的开发者”或“KoboldAI”运行应用。
- Metal 后端启用:在启动界面或设置中,确保后端选择为
Metal,这能充分利用 Mac 的统一内存架构,实现高效的推理速度。
Linux 平台安装实操
Linux 用户通常需要通过终端进行操作。
- 赋予执行权限:解压后,在终端进入文件夹,运行

chmod +x KoboldCpp
- 启动命令:直接运行
./KoboldCpp。 - CUDA 支持:如果你拥有 NVIDIA 显卡并希望使用 CUDA 加速,请确保系统中已安装对应版本的 NVIDIA 驱动和 CUDA Toolkit,KoboldCpp 通常会自动检测并链接系统库。
核心参数配置与性能优化指南
安装只是第一步,如何配置参数以获得最佳体验才是关键,KoboldCpp 提供了丰富的 Web UI 界面,让用户无需编写代码即可调整模型行为。
模型加载与显存管理
加载模型时,选择合适的量化格式(Quantization)至关重要,常见的格式包括 Q4_K_M、Q5_K_M 和 Q8_0。
- Q4_K_M:平衡了体积和精度,适合显存较小的用户(如 8GB 显存)。
- Q8_0:精度最高,但体积大,需要至少 16GB 以上的显存或较大的 CPU 内存。
- 操作建议:初次使用建议从 Q4_K_M 开始,如果感觉模型回答不够智能,再尝试更高精度的版本。
上下文窗口(Context Window)设置
上下文窗口决定了模型能记住多少前文信息。
- 默认设置:通常为 2048 或 4096 tokens。
- 优化建议:如果你的硬件资源充足(如 32GB 内存或 24GB 显存),可以将此值提升至 8196 或更高,但需注意,过大的上下文会显著增加推理延迟和内存占用,对于大多数对话场景,4096 已经足够。
并发与线程数调整
在“Settings”或“Advanced”选项卡中,你可以调整线程数(Threads)和批处理大小(Batch Size)。
- 线程数:建议设置为你的 CPU 物理核心数,6 核 CPU 设置为 6,过多的线程会导致上下文切换开销,反而降低速度。
- 批处理大小:较小的批处理(如 512)适合低显存环境,较大的批处理(如 2048)适合高显存环境,能提升吞吐量。

常见问题排查与故障排除
在使用 KoboldCpp 的过程中,用户可能会遇到一些常见问题,以下是基于行业共识的解决方案。
模型加载失败或崩溃
- 原因:显存不足或模型文件损坏。
- 解决:检查任务管理器中的显存占用,如果显存溢出,尝试加载更小量化版本的模型(如从 Q8 降至 Q4),确保模型文件完整,重新下载 GGUF 格式的文件。
推理速度缓慢
- 原因:未启用 GPU 加速或后端选择错误。
- 解决:确认在启动界面选择了正确的后端(如 CUDA、Metal 或 Vulkan),如果是 CPU 推理,确保开启了 AVX2 或 AVX-512 指令集支持(如果硬件支持)。
Web UI 无法访问
- 原因:端口被占用或防火墙拦截。
- 解决:检查默认端口(通常是 5000 或 8080)是否被其他程序占用,尝试在启动命令中添加
--port 8081指定新端口。
KoboldCpp 下载和安装常见问题解答
KoboldCpp 下载与安装中遇到依赖缺失怎么办?
KoboldCpp 设计为自动下载依赖,但如果网络受限,手动下载 llama.cpp 核心库并放置在软件目录下的 models 或指定文件夹中是可行的替代方案,确保核心库版本与 KoboldCpp 版本兼容。
KoboldCpp 与 Ollama 相比哪个更适合新手?
Ollama 以极简的命令行体验著称,适合快速测试;而 KoboldCpp 提供了更丰富的 Web UI 和细粒度的参数控制,适合希望深度定制模型行为、进行角色扮演或长文本创作的用户,对于需要高度自定义场景的用户,KoboldCpp 是更优选择。
KoboldCpp 支持哪些格式的模型文件?
KoboldCpp 主要支持 GGUF 格式的模型文件,这是目前本地大模型最通用的量化格式,它也兼容部分 GGML 格式,但 GGUF 是未来趋势,建议优先下载 GGUF 文件以确保最佳兼容性和性能。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/398474.html