大模型的SimCLR对比学习是一种通过“正样本拉近、负样本推远”的自监督学习范式,旨在让模型在无需人工标注的情况下,学会提取具有不变性的深层语义特征。
SimCLR的核心逻辑与工作原理
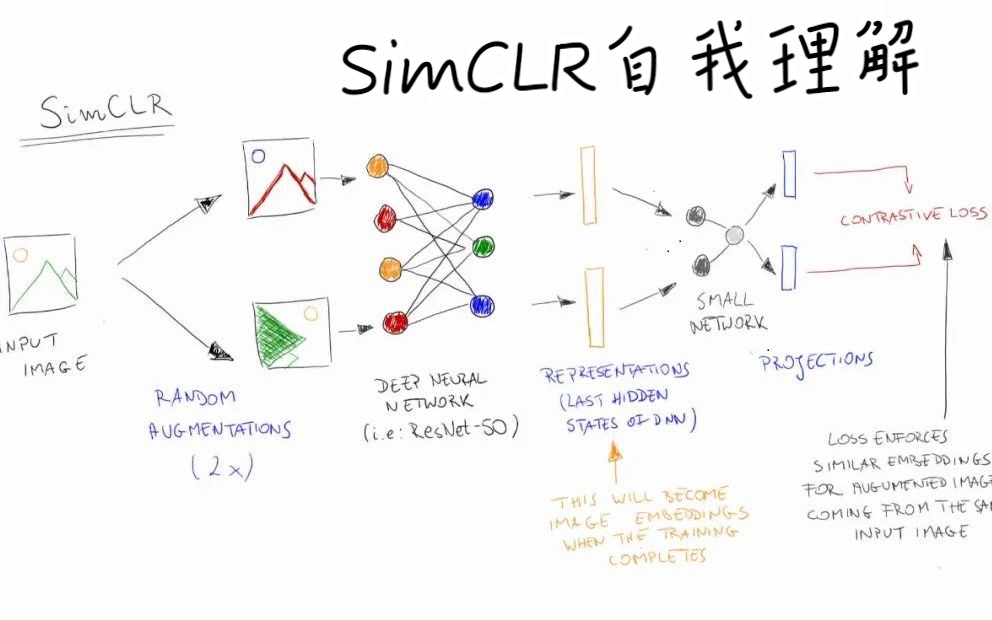
SimCLR(Simple Contrastive Learning of Visual Representations)并非一个复杂的黑盒,其核心思想非常直观:让模型理解“什么是同一个东西的不同面貌”,在预训练阶段,它不依赖标签,而是通过数据增强技术,将同一张原始图片生成两个不同的视图(View),这两个视图被视为“正样本对”,从批次(Batch)中随机选取其他图片的视图作为“负样本”。
数据增强的艺术
数据增强是SimCLR的灵魂,业内专家指出,简单的裁剪或颜色抖动不足以捕捉深层语义,因此SimCLR采用了一系列组合策略。
具体增强操作路径
- 随机裁剪与缩放:模拟不同距离和角度的观察。
- 高斯模糊:模拟失焦或低分辨率场景,迫使模型关注结构而非纹理。
- 颜色抖动:调整亮度、对比度和饱和度,消除光照影响。
- 随机灰度化:偶尔将图片转为黑白,增强对形状特征的依赖。
这些操作并非随意堆砌,而是为了构建一个“不变性约束”,模型需要学会:无论图片怎么变,只要本质内容没变,它在特征空间中的位置就应该接近。
对比损失的数学直觉
SimCLR使用InfoNCE损失函数来优化模型,它计算正样本对在特征空间中的余弦相似度,并将其与所有负样本对的相似度进行对比。
- 目标:最大化正样本对的相似度得分。
- 惩罚:最小化负样本对的相似度得分。
这种机制迫使编码器(Encoder)将同一内容的不同视图映射到特征空间的同一区域,而将不同内容映射到远离的区域,这种“聚类”效果使得模型能够学习到鲁棒的特征表示。
为什么SimCLR在大模型时代依然关键?
随着Transformer架构在多模态大模型中的普及,SimCLR的角色从“独立训练框架”转变为“特征对齐基石”,在2026年的技术语境下,理解SimCLR对于优化大模型的视觉编码器和跨模态对齐至关重要。

自监督学习的性价比优势
标注数据昂贵且稀缺,而互联网上存在海量的无标签图像和视频,SimCLR证明了仅需少量标签甚至零标签,就能训练出强大的视觉骨干网络。
- 数据利用率:利用未标注数据预训练,大幅降低对标注数据的依赖。
- 迁移学习效果:在ImageNet等基准测试中,SimCLR预训练的模型在下游任务(如分类、检测)上的表现,往往优于随机初始化或仅使用少量标签训练的模型。
与MAE、DINO等方法的对比
虽然Masked Autoencoders (MAE) 和 DINO 等自监督方法近年来热度极高,但SimCLR在特定场景下仍有不可替代的优势。
| 特性 | SimCLR (对比学习) | MAE (掩码自编码) | DINO (自蒸馏) |
|---|---|---|---|
| 核心机制 | 正负样本对比 | 重构丢失像素 | 教师-学生网络蒸馏 |
| 计算复杂度 | 中等(依赖Batch Size) | 高(需重构高分辨率图) | 高(需双网络前向传播) |
| 特征语义性 | 强(全局语义对齐) | 中(侧重局部重建) | 极强(细粒度语义) |
| 适用场景 | 通用视觉特征提取 | 图像修复、生成任务 | 细粒度分类、分割 |
对于追求SimCLR对比学习原理详解的开发者而言,理解其对比机制有助于更好地设计跨模态对齐模块,在训练图文匹配模型时,SimCLR的思想被广泛用于拉近“图片”与“描述该图片的文本”之间的距离。
SimCLR在大模型中的实际应用场景
SimCLR不仅仅是一个计算机视觉算法,其理念已渗透到多模态大模型的各个角落。

多模态特征对齐
在CLIP类模型中,视觉编码器和文本编码器需要共享一个特征空间,SimCLR式的对比损失被广泛用于优化这一过程。
- 操作路径:将图像和文本分别通过各自的编码器映射到向量空间。
- 损失计算:计算图像向量与对应文本向量的余弦相似度(正样本),与其他不匹配图文对的相似度(负样本)。
- 结果:模型学会理解“一只猫在草地上”不仅意味着视觉上的猫和草地,还意味着文本语义上的对应。
视频理解与动作识别
视频数据具有时间连续性,SimCLR通过时间维度的增强策略(如随机时间裁剪、帧顺序打乱),可以学习到对时间扰动鲁棒的特征。
- 场景描述:在监控视频中,即使摄像头轻微抖动或光线变化,模型仍能准确识别“跌倒”或“奔跑”等动作。
- 技术细节:通过对比同一视频片段的不同时间采样视图,模型学会忽略时间上的微小扰动,聚焦于动作的本质特征。
医疗影像分析
医疗数据标注成本极高,且存在隐私保护限制,SimCLR允许模型在无标签的医学影像上进行预训练,学习正常的解剖结构特征。
- 优势:预训练模型能够捕捉细微的病理变化,即使这些变化在视觉上非常隐蔽。
- 应用:在肺结节检测或视网膜病变分类任务中,SimCLR预训练的模型往往能提供更准确的初始特征表示,减少后续微调所需的数据量。
实施SimCLR的关键注意事项
想要在实际项目中成功应用SimCLR,开发者需要注意以下几个关键点,避免常见的陷阱。
Batch Size的重要性
SimCLR的性能对Batch Size极为敏感,较大的Batch Size意味着更多的负样本,从而提供更清晰的对比信号。
- 建议:在资源允许的情况下,尽量使用较大的Batch Size,如果显存有限,可以使用梯度累积技术模拟大Batch效果。
- 权衡:过小的Batch Size会导致负样本不足,模型难以区分细微差异,性能显著下降。
温度系数(Temperature)的调优

InfoNCE损失函数中的温度系数$tau$控制着分布的尖锐程度。
- 小$tau$:使分布更尖锐,模型更关注区分最难的负样本。
- 大$tau$:使分布更平滑,模型更关注整体分布。
- 经验法则:通常从0.5开始尝试,根据验证集表现进行调整,不同数据集可能需要不同的最优值。
数据增强的强度平衡
增强过度会导致正样本对差异过大,模型难以学习;增强不足则无法提供足够的不变性约束。
- 调试方法:逐步增加增强操作的强度,观察训练损失和验证集准确率的变化。
- 领域适配:对于特定领域(如卫星图像、显微镜图像),可能需要定制特定的增强策略,而非直接使用标准SimCLR配置。
SimCLR对比学习常见问题解答
SimCLR对比学习与监督学习的主要区别是什么?
SimCLR属于自监督学习,无需人工标注标签,而是通过数据增强生成伪标签(正样本对),利用对比损失函数优化模型,监督学习则依赖大量人工标注的数据,通过交叉熵等损失函数直接预测类别,SimCLR的优势在于能利用海量无标签数据,适合数据标注成本高的场景;监督学习在标注数据充足时,通常能获得更高的分类精度。
SimCLR对比学习在NLP领域有类似应用吗?
是的,SimCLR的理念在自然语言处理(NLP)中也有广泛应用,例如SimCSE(Simple Contrastive Learning of Sentence Embeddings),其核心思想相同:对同一句话进行Dropout或轻微扰动生成两个视图,视为正样本对,与其他句子视为负样本对,这种方法能显著提升句子嵌入向量的质量,在语义相似度计算和检索任务中表现优异。
SimCLR对比学习的训练成本是否高昂?
SimCLR的训练成本主要集中在显存占用上,因为需要较大的Batch Size来提供足够的负样本,与生成式模型(如Diffusion Models)相比,其计算复杂度相对较低,近年来,通过优化负样本采样策略(如使用内存库)或采用分布式训练,可以在有限的硬件资源下高效运行,对于大多数企业级应用,使用预训练的SimCLR模型进行微调,其成本效益远高于从头训练。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/405701.html











