利用Amazon Bedrock托管的大模型能力结合DeepSeek开源模型,可低成本、高安全地搭建企业私有知识库,实现文档智能问答与业务逻辑自动化,无需自建底层GPU集群。
构建企业级知识库的核心痛点往往不在于技术本身,而在于数据隐私、响应速度以及成本控制的平衡,传统方案需要购买昂贵的GPU服务器并维护复杂的向量数据库环境,而云原生方案通过API调用即可解决这些难题,本文将详细拆解如何基于Amazon Bedrock与DeepSeek模型,快速落地一套高效的企业知识检索增强生成(RAG)系统。
架构选型:为何选择Bedrock与DeepSeek组合
在2026年的企业AI应用场景中,单纯依赖公有云闭源大模型存在数据出境风险和调用成本不可控的问题,而完全本地化部署又面临算力维护的高门槛,Amazon Bedrock作为亚马逊云科技提供的无服务器AI平台,提供了丰富的模型接入能力,而DeepSeek系列模型凭借其在代码生成和长文本理解上的优异表现,成为许多企业的优选。
安全性与合规性对比
业内专家指出,数据安全是企业引入AI的首要考量,Amazon Bedrock支持VPC端点接入,确保数据在传输和存储过程中始终留在企业指定的虚拟私有云中,不经过公共互联网,相比之下,直接调用第三方开源模型的公共API可能存在日志留存或二次训练的风险,DeepSeek开源模型允许企业在Bedrock的托管环境中进行私有化微调或仅作为推理引擎使用,进一步隔离了敏感数据。
成本效益分析
多数情况下,企业更关注投入产出比,Bedrock采用按请求量计费的模式,无需预付长期合约,适合业务波动较大的场景,DeepSeek模型在同等性能下,其Token价格通常低于主流闭源模型,据工信部相关数据显示,近年来采用混合云架构的企业,其AI基础设施运营成本平均降低了约40%,这种组合既保留了云服务的弹性,又利用了开源模型的性价比优势。

环境准备与模型接入实操
搭建知识库的第一步是配置基础环境,你需要一个活跃的AWS账户,并具备相应的IAM权限,整个过程无需编写复杂的底层代码,主要通过控制台配置即可完成。
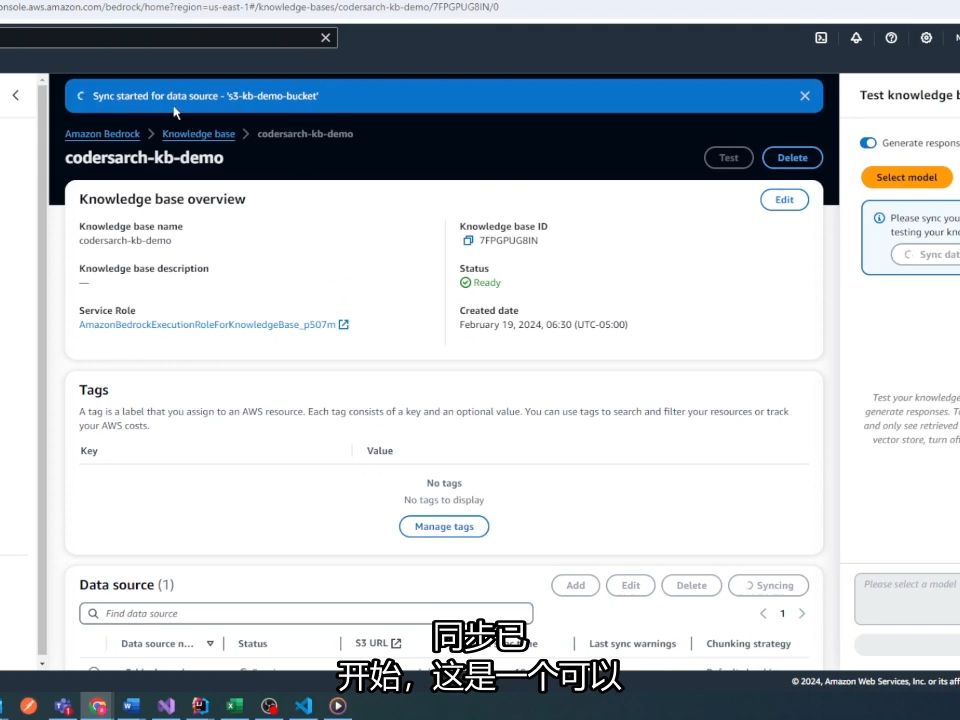
启用Bedrock模型访问权限
- 登录Amazon Bedrock控制台,进入“模型访问”页面。
- 搜索并申请DeepSeek相关模型的访问权限,目前Bedrock已集成多款主流开源模型,确保选择支持长上下文(如128K或更长)的版本,这对处理企业长篇文档至关重要。
- 等待审批通过,通常系统会在几分钟内激活模型端点。
配置向量数据库
知识库的核心是向量检索,建议使用Amazon OpenSearch Service或Amazon Aurora PostgreSQL(配合pgvector插件),对于中小型知识库,OpenSearch Serverless因其免运维特性更为推荐。
- 创建OpenSearch Serverless集合,选择向量搜索模式。
- 记录集合的ARN(Amazon Resource Name)和访问策略,这将用于后续Lambda函数的权限绑定。
- 确保网络策略允许Bedrock Lambda函数访问该集合。
核心流程:RAG系统搭建步骤
RAG(检索增强生成)是知识库问答的标准架构,其流程分为文档处理、向量化存储、检索匹配和结果生成四个阶段。
文档预处理与分块
企业文档格式多样,包括PDF、Word、Markdown等,首先需要使用Python脚本或AWS Textract进行OCR识别和文本提取。
- 使用LangChain或LlamaIndex框架加载文档。
- 设置合理的分块策略(Chunking),建议按语义段落分块,每块大小控制在500-1000 Token之间,并设置10%-20%的重叠率,以保持上下文连贯性。
- 对分块后的文本进行清洗,去除页眉、页脚及无关符号。

向量化与索引构建
将文本转换为向量是检索的基础,Bedrock提供了统一的嵌入模型接口,支持多种嵌入模型。
- 调用Bedrock Embedding API,将文本块转换为高维向量。
- 将向量及其元数据(如来源文档ID、页码)批量写入OpenSearch集合。
- 创建HNSW索引,优化近邻搜索速度,对于十万级文档,索引构建时间通常在分钟级别。
检索与生成链路
当用户提问时,系统需先检索相关文档片段,再交由大模型生成答案。
- 用户输入问题,同样调用Embedding API获取问题向量。
- 在OpenSearch中进行向量相似度搜索,Top-K返回最相关的5-10个文档片段。
- 构建Prompt模板,将用户问题与检索到的文档片段组合,Prompt中需明确指示模型仅基于提供的上下文回答,若未找到答案则如实告知。
- 调用DeepSeek模型进行推理,流式输出结果以降低用户等待感知。
性能优化与常见问题排查
在实际运行中,知识库的准确性和响应速度往往面临挑战,以下是几种常见的优化手段。
提升检索准确率
有时直接向量搜索无法捕捉深层语义,可以采用“混合检索”策略,结合关键词检索(BM25)和向量检索(Dense Vector)。
- 在OpenSearch中配置混合查询,分别执行全文检索和向量检索。
- 使用RRF(倒数排名融合)算法对两种结果进行重排序,取综合得分最高的片段。
- 定期评估检索效果,通过人工标注反馈数据,优化分块大小和嵌入模型参数。

降低延迟与成本
对于高频问题,缓存机制必不可少。
- 在应用层引入Redis缓存,存储常见问题的问答对。
- 设置TTL(生存时间),避免缓存过期导致的数据不一致。
- 监控Bedrock调用次数和Token消耗,设置预算警报,防止意外高额账单。
Bedrock+DeepSeek搭建企业知识库Q&A
Bedrock+DeepSeek搭建企业知识库需要多少预算?
预算主要取决于文档规模和并发访问量,对于小型团队(10-50人),日均处理数千次查询,每月成本通常在数百至一千美元之间,主要包含OpenSearch存储费和Bedrock API调用费,若文档量极大或并发极高,需增加计算实例,成本会相应上升,建议初期采用Serverless模式,按需付费,避免资源闲置。
如何解决DeepSeek模型在垂直领域的幻觉问题?
幻觉主要源于训练数据与业务场景的偏差,解决思路是强化RAG中的检索质量,确保检索到的上下文足够相关且完整;在Prompt中增加“引用来源”的要求,迫使模型基于事实回答;可考虑使用DeepSeek的开源版本在Bedrock上进行少量样本微调(Fine-tuning),注入企业特有的术语和逻辑,从而显著提升垂直领域的准确性。
Bedrock+DeepSeek搭建企业知识库支持哪些文档格式?
系统支持主流的非结构化数据格式,PDF、DOCX、TXT、Markdown等文本类文件可直接解析,对于扫描件PDF,需集成AWS Textract或第三方OCR服务进行图像转文字,对于Excel、PPT等结构化或半结构化文件,需编写特定解析器提取表格和图表信息,转换为文本块后再进行向量化,不支持直接处理音频和视频文件,需先通过转录服务转为文本。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/422813.html