GPU服务器深度学习环境的核心在于构建基于Linux系统的CUDA与PyTorch/TensorFlow双栈架构,通过Docker容器化隔离依赖,实现从驱动安装到模型训练的一站式稳定运行。
搭建高性能计算环境并非简单的软件堆砌,而是一场对硬件资源与软件生态的精细调度,对于许多初次接触GPU服务器深度学习环境设置的技术人员而言,最大的痛点往往不是代码逻辑,而是底层环境的兼容性冲突,本文将剥离繁杂的理论,直接切入实操核心,帮助你快速搭建一个稳定、高效且易于维护的训练平台。
硬件选型与驱动基础
在软件层面动手之前,硬件的兼容性是决定上限的关键,业内专家指出,NVIDIA显卡在深度学习领域的统治力源于其完整的CUDA生态闭环,选择搭载NVIDIA GPU的服务器是绝大多数场景下的最优解。
驱动版本匹配策略
驱动程序是连接操作系统与GPU硬件的桥梁,版本选择遵循“向下兼容”原则,但并非越新越好,需与CUDA Toolkit版本严格对应。
- 确认硬件型号:使用
nvidia-smi命令查看当前显卡型号及驱动版本,这是排查环境问题的第一步,也是确认GPU服务器配置推荐是否合理的依据。 - 下载对应驱动:访问NVIDIA官网,根据GPU架构(如Ampere、Hopper)选择对应的Linux驱动包,注意区分专有驱动(Proprietary)与开源驱动(Nouveau),深度学习必须使用专有驱动。
- 禁用冲突模块:在安装前,务必确保系统内核模块
nouveau已被禁用并加入黑名单,否则安装过程会因图形界面冲突而失败。
CUDA Toolkit的安装逻辑
CUDA Toolkit包含了编译器、库文件和开发工具,是深度学习框架的底层依赖。
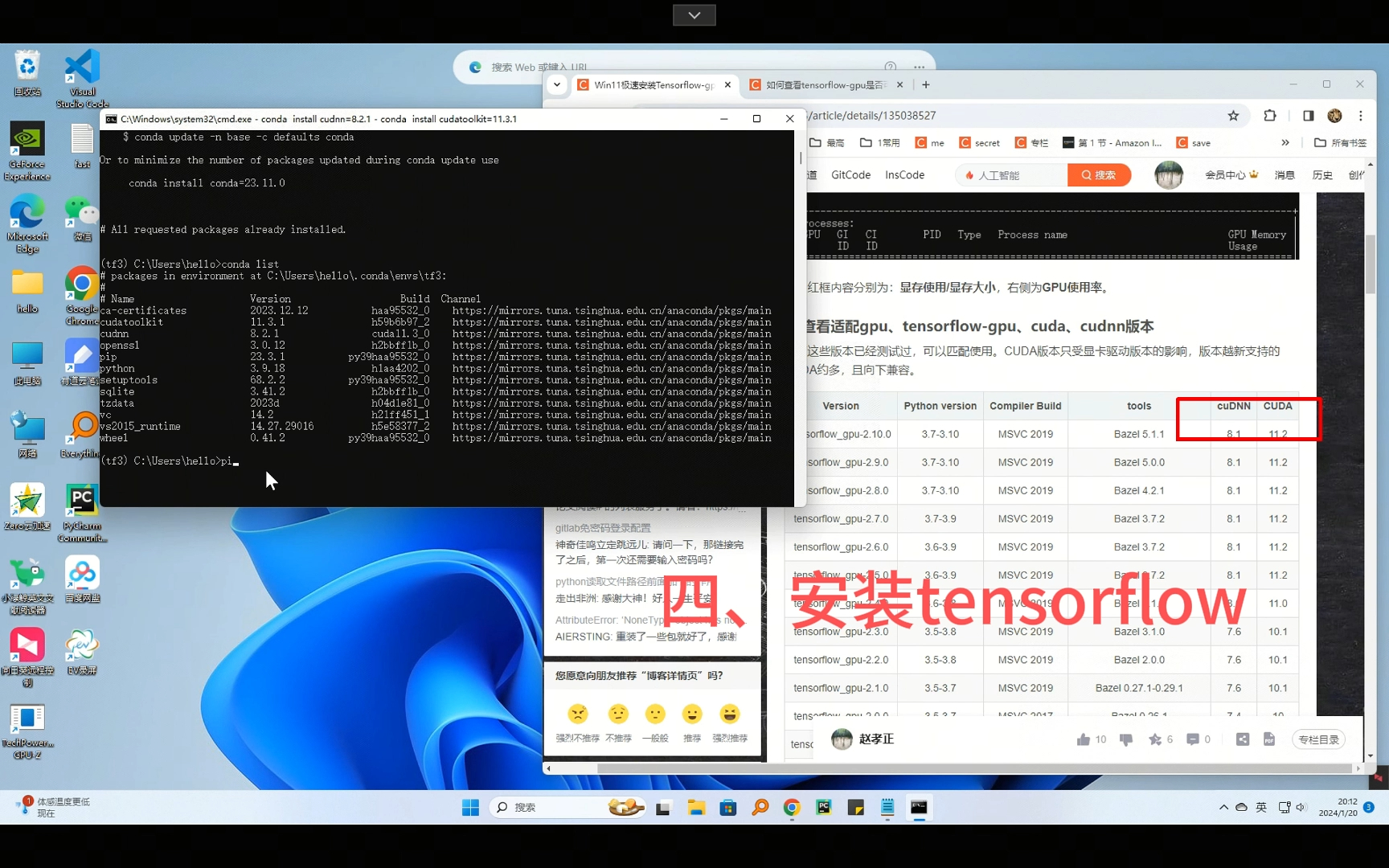
- 版本选择:PyTorch和TensorFlow对CUDA版本有明确支持列表,PyTorch 2.x通常支持CUDA 11.8或12.1+,建议优先选择框架官方推荐的稳定版本,避免使用最新但未经验证的Beta版。
-

安装方式
:推荐使用.run文件安装而非包管理器(apt/yum),因为.run安装能更灵活地控制路径,避免与系统预装库冲突,安装后,需将CUDA的bin和lib路径添加到~/.bashrc环境变量中,并执行source ~/.bashrc生效。
深度学习框架与依赖管理
有了底层驱动,接下来是构建上层应用,Python作为主流语言,其包管理器的混乱是新手最大的噩梦,解决之道在于虚拟环境隔离。
Conda虚拟环境的最佳实践
Conda不仅管理Python包,还能管理非Python依赖(如MKL库),是构建深度学习环境配置指南中的核心工具。
- 创建独立环境:为每个项目创建独立的Conda环境,避免依赖冲突,命令示例:
conda create -n my_project python=3.10。 - 激活与切换:使用
conda activate my_project激活环境,确保在激活状态下安装框架,这样PyTorch或TensorFlow才能正确链接到当前环境的CUDA版本。 - 导出与复用:使用
conda env export > environment.yml导出环境配置,便于团队协作或迁移至其他服务器,实现环境的一致性。
PyTorch与TensorFlow的安装差异
不同框架对CUDA的调用方式略有不同,安装时需精准匹配。
- PyTorch:推荐使用官方提供的pip或conda安装命令。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118,这种方式会自动下载预编译好的CUDA版本,省去手动编译的痛苦。 - TensorFlow:TensorFlow 2.10及以上版本开始支持GPU自动配置,但仍需确保系统级CUDA和cuDNN版本符合其要求,对于追求极致性能的用户,建议编译源码版本,但这对环境要求极高,多数场景下使用官方预编译包即可。
容器化部署与性能优化
当环境复杂度增加,单机多环境共存成为常态,Docker容器化技术成为提升效率的关键。
Docker在GPU环境中的应用

Docker提供了轻量级的虚拟化隔离,确保不同项目互不干扰。
- 安装NVIDIA Container Toolkit:这是Docker调用GPU的关键组件,安装后,Docker进程便能感知并分配宿主机的GPU资源。
- 拉取官方镜像:使用
nvidia/cuda:11.8.0-base-ubuntu22.04等基础镜像,或PyTorch官方提供的pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel镜像,这些镜像已预装好底层依赖。 - 挂载数据卷:通过
-v /host/data:/container/data挂载宿主机目录,避免在容器内重复存储海量训练数据,节省空间并提高I/O效率。
性能调优与监控
环境搭建完成后,性能调优是挖掘硬件潜力的最后一步。
- 显存优化:使用
nvidia-smi实时监控显存占用,对于显存不足的情况,可调整Batch Size或使用梯度累积技术。 - 多卡并行:对于多GPU服务器,需配置NCCL(NVIDIA Collective Communications Library)以优化卡间通信,在PyTorch中,使用
DistributedDataParallel进行多卡训练,能显著提升大规模模型的训练速度。 - 驱动更新策略:定期关注NVIDIA驱动更新日志,修复已知Bug并提升新框架的兼容性,但生产环境建议在测试充分后再进行升级。
常见问题排查与维护
在实际操作中,环境报错是常态,掌握常见的排查路径,能大幅缩短调试时间。
典型错误与解决方案
- CUDA版本不匹配:报错
RuntimeError: Found no NVIDIA driver on your system,首先检查nvidia-smi是否输出正常,其次确认nvcc --version与框架要求的CUDA版本一致。 - cuDNN缺失:报错
Could not find cudnn,需确保cuDNN库文件位于CUDA安装目录的lib64下,且环境变量LD_LIBRARY_PATH包含该路径。 - 权限问题:在Linux系统中,普通用户可能无法访问GPU设备文件,可通过将用户加入

video
render组,或使用sudo临时解决,但长期建议配置udev规则赋予特定用户永久访问权。
备份与恢复机制
环境配置耗时耗力,建立自动备份机制至关重要。
- 配置文件备份:定期备份
~/.bashrc、/etc/profile及Conda环境文件。 - 镜像备份:对于Docker环境,使用
docker save命令将关键镜像导出为tar包,存储在NAS或云端,防止服务器重置后重新构建的繁琐。
GPU服务器深度学习环境设置常见问题
Q: 如何判断我的GPU是否被深度学习框架正确识别?
在Python环境中导入框架后,执行检查命令,对于PyTorch,运行torch.cuda.is_available(),若返回True,则说明CUDA可用;运行torch.cuda.device_count()查看可用GPU数量,对于TensorFlow,运行tf.config.list_physical_devices('GPU'),若列表非空,则识别成功,这是验证环境设置是否到位的最直接方法。
Q: 多用户共用GPU服务器时,如何避免资源抢占?
通过配置cgroups或Slurm作业调度系统实现资源隔离,在单机场景下,可利用Docker的--gpus参数限制每个容器使用的GPU数量或显存大小。docker run --gpus '"device=0,1"'指定仅使用0号和1号显卡,设置用户级别的显存限制,防止单个进程占用全部资源导致其他用户任务失败。
Q: 为什么安装了CUDA和cuDNN,但训练速度依然很慢?
训练速度慢通常与数据I/O瓶颈或代码实现有关,而非环境配置问题,首先检查数据加载是否成为瓶颈,尝试使用DataLoader的num_workers参数增加并行加载线程,确认数据是否存放在高速SSD或NVMe硬盘上,机械硬盘的I/O延迟会严重拖慢训练进度,检查代码中是否存在不必要的CPU-GPU数据传输,尽量减少tensor.cpu()和tensor.cuda()的频繁切换。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/425368.html