Hadoop服务器架构图的核心逻辑在于将计算资源与存储资源分离,通过Master/Slave架构实现海量数据的分布式处理,其本质是一套解决“存得下、算得快”问题的底层基础设施。
理解Hadoop架构,不能只看静态的拓扑图,而要把它想象成一个庞大的物流与加工工厂,在这个工厂里,数据是原材料,MapReduce或Spark是加工流水线,而HDFS则是巨大的原材料仓库,要搭建或优化这样一个系统,必须理清各个组件的职能及其协作方式。
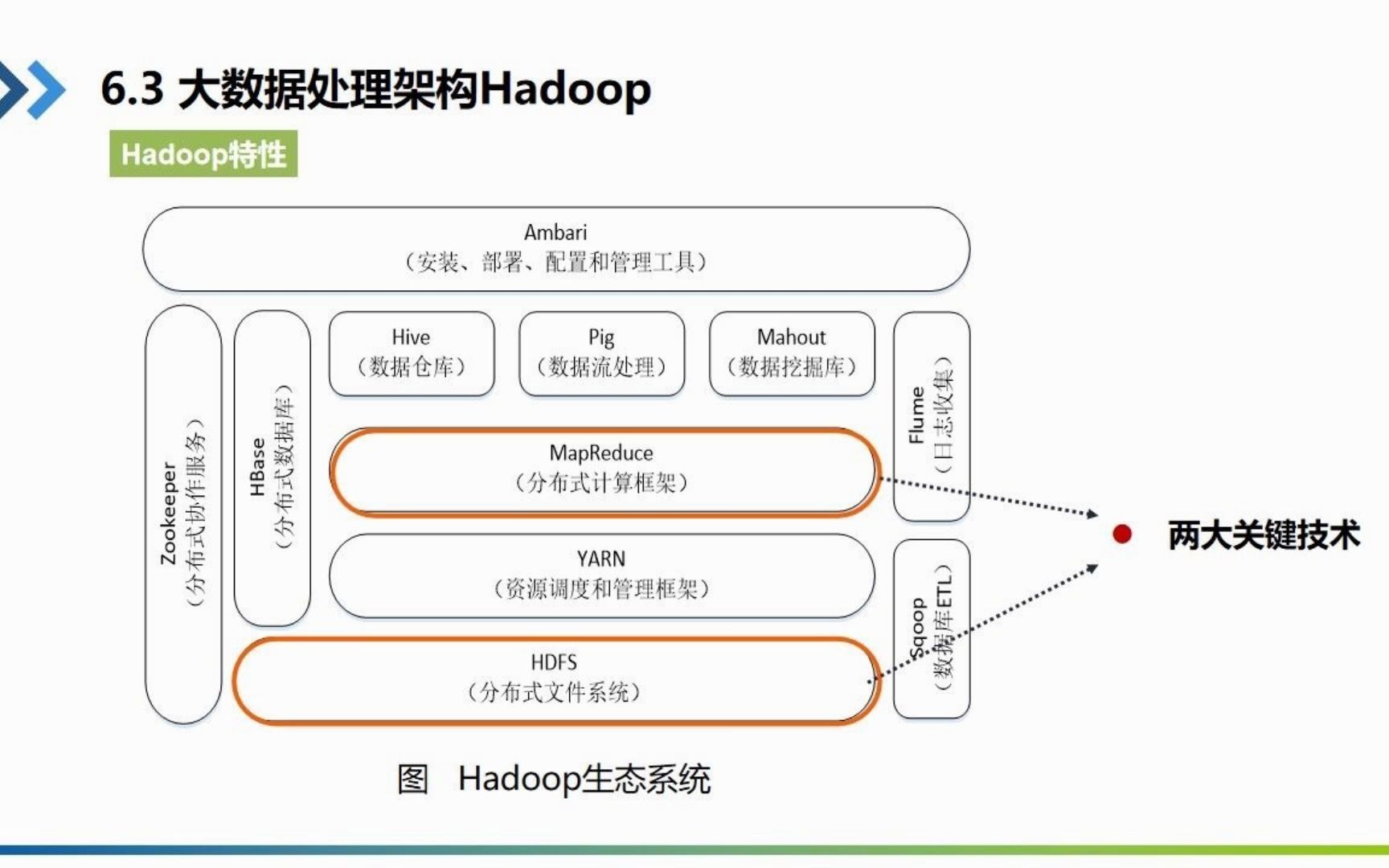
Hadoop核心架构的三大支柱解析
Hadoop生态系统的基石由三个主要部分组成:HDFS、YARN和MapReduce,这三者分工明确,共同构成了分布式计算的闭环。
HDFS:分布式文件系统的存储底座
HDFS(Hadoop Distributed File System)负责数据的持久化存储,它的设计哲学是“一次写入,多次读取”,因此对随机读写支持较差,但对高吞吐量的数据流访问非常友好。
NameNode与DataNode的角色分工
在HDFS中,节点分为两类,它们的职责截然不同:
- NameNode(主节点):它是整个文件系统的“大脑”,它不存储实际数据,而是维护文件系统的元数据(Metadata),包括文件目录树、文件与数据块的映射关系、数据块的位置信息等,NameNode通常采用双机热备(HA)模式,以防止单点故障导致整个集群瘫痪。
- DataNode(从节点):它是“体力劳动者”,实际的数据块(Block,默认128MB或256MB)存储在DataNode的本地磁盘上,它负责执行数据的读写操作,并定期向NameNode汇报自身状态和数据块的健康情况。
数据冗余与容错机制
为了确保数据安全,HDFS默认将每个数据块复制<3>份,这些副本通常分布在不同的机架甚至不同的数据中心,如果某个DataNode宕机,NameNode会检测到心跳丢失,并自动在其他节点上重新复制缺失的副本,保证数据的可用性。
YARN:资源调度的核心引擎
随着Hadoop生态的扩展,MapReduce不再唯一,Spark、Flink等计算框架也应运而生,YARN(Yet Another Resource Negotiator)的出现解决了资源统一调度的问题。
- ResourceManager:集群的全局资源管理者,负责分配资源给各个应用。
- NodeManager:单个节点上的资源管理者,负责启动和监控容器(Container)。
- ApplicationMaster:每个应用程序的“管家”,负责向ResourceManager申请资源,并与NodeManager协调任务的执行。

MapReduce:分布式计算模型
MapReduce是一种编程模型,用于大规模数据集的并行运算,它将计算过程分为两个阶段:
- Map阶段:将输入数据分割成小块,并行处理并输出键值对。
- Reduce阶段:对Map输出的键值对进行汇总和整理,生成最终结果。
虽然Spark等新技术在速度上更具优势,但MapReduce依然是理解分布式计算逻辑的基础,尤其在处理批处理任务时依然广泛使用。
Hadoop集群部署架构对比与选型建议
在实际生产环境中,架构的选择直接决定了系统的稳定性、扩展性和维护成本,不同的部署模式适用于不同的业务场景。
单机模式与伪分布式模式
- 单机模式:所有进程运行在同一个JVM中,不使用HDFS,仅用于本地调试代码,这是学习Hadoop API的第一步。
- 伪分布式模式:所有守护进程运行在同一台机器上,但模拟了分布式环境,适合开发者在本地测试HDFS读写和MapReduce作业流程。
完全分布式模式:生产环境的主流选择
这是企业级应用的标准架构,NameNode、DataNode、ResourceManager、NodeManager等组件分布在多台物理服务器或虚拟机上。
高可用(HA)架构的关键配置
在生产环境中,NameNode的单点故障是致命风险,业内专家指出,构建高可用集群是必然趋势。
- 双NameNode方案:部署两个NameNode,一个处于Active状态,另一个处于Standby状态。
- ZooKeeper集成:利用ZooKeeper实现故障自动切换(Failover),当Active NameNode宕机时,ZooKeeper会自动将Standby NameNode提升为Active,整个过程对上层应用透明。
- 共享存储(QJM):通过Quorum Journal Manager(QJM)或NFS实现两个NameNode之间的元数据同步,确保数据一致性。

混合部署与资源隔离
对于同时运行Hadoop、Spark、HBase等多种组件的大集群,资源隔离至关重要。
- Cgroups技术:利用Linux的Cgroups对CPU和内存进行限制,防止某个任务占用过多资源导致其他任务饥饿。
- 多租户调度:通过YARN的队列管理,为不同部门或业务线分配独立的资源池,确保关键业务优先获得计算资源。
Hadoop运维中的常见痛点与优化策略
架构搭建只是开始,长期的稳定运行依赖于细致的运维管理,许多企业在构建大数据平台时,往往忽视性能调优和监控,导致集群效率低下。
小文件问题:HDFS的“癌症”
HDFS不适合存储大量小文件,因为每个文件、目录和数据块都会占用NameNode约150字节的内存,如果集群中有数百万个小文件,NameNode的内存压力将急剧增加,甚至导致集群崩溃。
解决方案
- HAR(Hadoop Archive):将小文件打包成HAR归档文件,减少NameNode的元数据负担。
- SequenceFile/Avro:在写入数据时,使用二进制格式将多个小文件合并为大文件。
- MapFile:在MapReduce作业中,通过设置Reduce任务数量为1,强制合并输出文件。
数据倾斜:计算任务的瓶颈
在MapReduce或Spark作业中,如果某个Key的数据量远大于其他Key,会导致个别Reduce任务处理时间过长,拖累整个作业进度。
优化手段
- 加盐(Salting):在Map阶段,给Key加上随机前缀,将数据打散到不同的Reduce节点,处理完成后再去除前缀进行二次聚合。
- 调整并行度:增加Reduce任务的数量,分散负载。
- 使用Combiner:在Map端进行局部聚合,减少网络传输的数据量。
监控与告警体系
没有监控的集群是盲目的,必须建立完善的监控体系,实时掌握集群健康状态。
- JMX监控:通过Java Management Extensions暴露Hadoop组件的指标,如CPU使用率、内存占用、GC频率等。
- Prometheus + Grafana:将JMX指标采集到Prometheus,并使用Grafana进行可视化展示,设置阈值告警(如磁盘使用率超过80%时发送邮件通知)。
- 日志分析:集中收集Hadoop组件的日志,使用ELK(Elasticsearch, Logstash, Kibana)栈进行快速检索和故障排查。

Hadoop架构在2026年的演进趋势
尽管云原生技术兴起,Hadoop架构依然是许多企业数据湖的基石,其形态正在发生深刻变化。
存算分离架构的普及
传统Hadoop是存算耦合的,扩展存储必须同时扩展计算资源,2026年的主流趋势是存算分离,将HDFS迁移到对象存储(如AWS S3、阿里云OSS),计算资源按需弹性伸缩,这种架构降低了存储成本,提高了资源利用率。
与云原生技术的深度融合
Kubernetes(K8s)正在逐步接管Hadoop的资源调度,通过Operator模式,可以在K8s上部署和管理Hadoop组件,实现更细粒度的资源隔离和更快的故障恢复。
实时计算与批处理的统一
随着Flink等流处理引擎的成熟,批流一体的架构成为现实,Hadoop不再仅仅是批处理平台,而是通过集成流处理组件,支持实时数据分析和历史数据回溯的统一平台。
关于Hadoop服务器架构的常见问题解答
Hadoop集群中NameNode内存不足该如何扩容?
NameNode的内存主要用于存储元数据,扩容方案包括:1. 升级硬件,增加物理内存;2. 优化元数据管理,如使用Namenode的Image合并策略,减少内存占用;3. 采用分布式元数据管理方案,如Sharded NameNode,将元数据分散存储。
HDFS与传统NAS存储在性能上有何本质区别?
HDFS专为高吞吐量的顺序读写设计,适合大数据分析场景,但不支持低延迟的随机访问,NAS(网络附加存储)基于文件级访问,延迟低,适合小文件频繁读写和共享存储场景,两者互补,而非替代。
搭建一个高可用的Hadoop集群需要哪些最低硬件配置?
最低配置取决于数据量和并发需求,对于小型集群,建议NameNode节点配备<32GB>内存和SSD硬盘,DataNode节点配备<128GB>内存和多块大容量HDD,网络带宽建议至少<10Gbps>,以避免网络成为瓶颈,具体配置需根据数据增长预测进行动态调整。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/445946.html











