整理Hive分区数据库的核心在于通过动态分区插入、定期维护命令(MSCK REPAIR TABLE)以及合理的分区键设计,解决数据倾斜和元数据膨胀问题,从而显著提升查询效率并降低存储成本。
在大数据生态中,Hive作为数据仓库的核心组件,其性能表现直接取决于表结构的合理性,许多工程师在面对TB级数据时,往往因为忽视了分区整理的细节,导致查询任务长时间堆积,甚至引发集群资源耗尽,这并非计算能力不足,而是数据组织方式滞后于业务增长,通过系统化的分区管理,可以将杂乱无章的数据文件转化为有序、可高效检索的结构,这是保障数据平台稳定运行的基石。
为什么Hive表必须重视分区整理
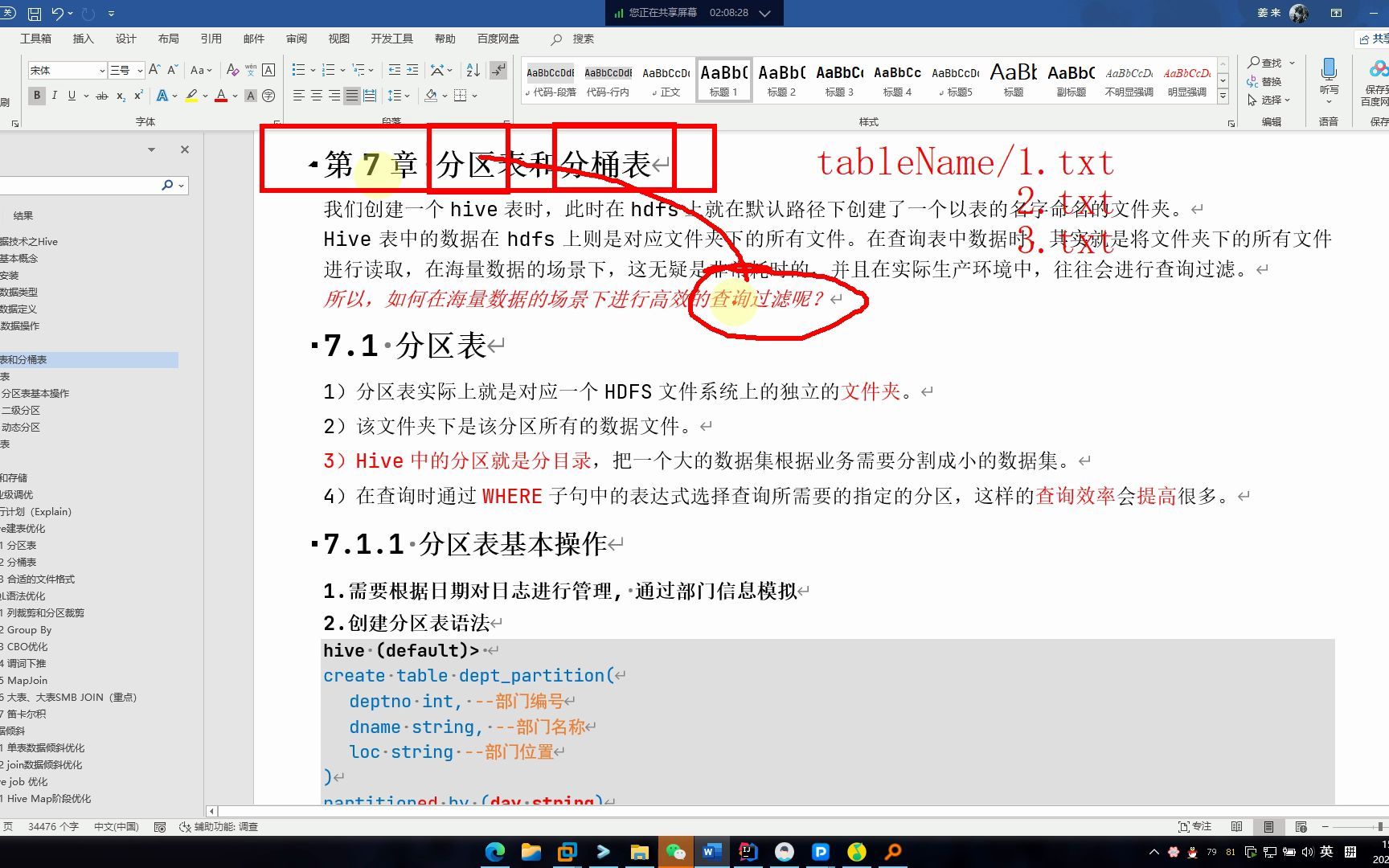
分区是Hive表物理隔离数据的基本单位,如果没有合理的分区,Hive在查询时需要扫描全表所有文件,这种全表扫描在数据量达到亿级时是不可接受的,业内专家指出,合理的分区策略能够将查询范围缩小到特定的数据子集,从而将查询耗时从小时级降低到秒级。
元数据膨胀带来的性能陷阱
随着业务数据的持续写入,如果分区粒度过细,例如按分钟甚至秒创建分区,会导致Hive Metastore中的元数据条目呈指数级增长,当分区数量超过数万甚至数十万时,Metastore的查询延迟会显著增加,甚至出现连接超时,这种现象在电商大促或日志采集场景中尤为常见。
具体表现与后果
- 查询启动慢:执行
SELECT语句时,Hive需要加载大量分区信息,导致Job提交延迟。 - 小文件问题:细粒度分区往往伴随大量小文件,NameNode内存压力剧增,影响整个集群稳定性。
- 维护成本高:手动清理过期分区变得极其困难,自动化脚本容易因元数据锁竞争而失败。
数据倾斜对计算资源的浪费
分区键选择不当会导致数据分布不均,若以“用户ID”作为分区键,而某些头部用户产生海量数据,会导致个别Reduce任务处理数据量远超其他任务,造成严重的计算资源浪费和任务执行时间拉长。
Hive表整理分区数据库的实操方案
解决分区问题的关键在于“事前规划”与“事后维护”相结合,以下是经过验证的标准化操作流程,适用于大多数企业级数据仓库场景。

第一步:优化分区键设计
分区键的选择应遵循“高基数低区分度”原则,避免使用唯一性极高的字段(如订单号、用户ID)作为分区键,而应使用具有明显时间或业务类别特征的字段。
推荐实践
- 时间分区:对于日志类数据,采用
dt(天)或hour(小时)作为分区,通常dt是最佳平衡点,既保证了数据的时间有序性,又控制了分区数量。 - 业务维度分区:对于交易数据,可采用
province(省份)或category(品类)作为二级分区,但需确保每个维度的枚举值数量有限。 - 多级分区策略:采用“一级时间+二级业务”结构,如
dt=2026-01-01/city=beijing,但需严格控制二级分区的基数,避免组合爆炸。
第二步:动态分区插入数据
在ETL过程中,应启用动态分区功能,避免手动指定每个分区路径,这不仅能减少代码复杂度,还能自动处理新增分区。
关键配置与命令
在执行数据导入前,必须设置以下参数以启用动态分区:
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; set hive.exec.max.dynamic.partitions.pernode=1000;
使用INSERT OVERWRITE语句进行数据加载:
INSERT OVERWRITE TABLE user_log PARTITION(dt, hour) SELECT user_id, action, dt, hour FROM staging_table;
注意:PARTITION子句中必须包含所有分区字段,且顺序需与表定义一致。
第三步:定期执行元数据修复
当数据文件通过HDFS命令直接移动或复制时,Hive Metastore可能无法感知这些变化,必须手动同步元数据。
使用MSCK REPAIR TABLE
对于新增的分区,执行以下命令可快速修复元数据:
MSCK REPAIR TABLE user_log;
该命令会扫描HDFS上的目录结构,并将缺失的分区信息添加到Metastore中,对于分区数量巨大的表,建议分批执行,避免单次请求过大导致超时。

清理过期分区
定期清理无用数据是保持表健康的关键,可以使用ALTER TABLE语句删除特定分区:
ALTER TABLE user_log DROP PARTITION (dt='2026-01-01');
建议结合调度系统(如Airflow或DolphinScheduler),设置自动清理策略,保留最近90天的数据,其余数据归档至冷存储。
常见误区与对比分析
在实际操作中,许多团队容易陷入一些认知误区,导致分区整理效果不佳,以下通过对比分析,澄清常见错误。
分区 vs 分桶:适用场景差异
| 特性 | 分区 (Partition) | 分桶 (Bucket) |
|---|---|---|
| 目的 | 数据隔离,减少扫描范围 | 优化Join性能,提高采样效率 |
| 实现方式 | 目录结构隔离 | 哈希取模,文件内部分割 |
| 适用场景 | 时间序列数据、维度过滤 | 大表Join、数据采样 |
| 维护成本 | 低,但需注意分区数量 | 高,需预先指定桶数 |
行业共识认为,分区主要用于过滤数据,而分桶主要用于加速连接操作,两者并非替代关系,而是互补关系,在数据量极大的场景下,建议同时使用分区和分桶,以实现最佳性能。
静态分区 vs 动态分区
静态分区需要ETL脚本中硬编码分区值,灵活性差,容易出错,动态分区则根据数据内容自动确定分区值,适应性强,对于数据源复杂、分区值不固定的场景,动态分区是更优选择,但需注意,动态分区会增加Map端的处理开销,因此在数据量较小或分区值固定的场景下,静态分区可能更高效。
高级优化技巧与注意事项

除了基础的分区管理,还有一些高级技巧可以进一步提升Hive表的查询效率。
小文件合并
动态分区和频繁的数据写入会产生大量小文件,严重影响NameNode性能和查询效率,建议在ETL任务结束后,执行小文件合并操作:
SET hive.merge.mapfiles=true; SET hive.merge.mapredfiles=true; SET hive.merge.size.per.task=256000000;
这些参数会在MapReduce任务结束时,自动将小文件合并为指定大小的文件,通常建议合并为256MB或128MB,以匹配HDFS块大小。
统计信息收集
Hive优化器依赖于表的统计信息(如行数、文件大小)来选择执行计划,如果统计信息过时,优化器可能会选择低效的执行路径,定期收集统计信息至关重要:
ANALYZE TABLE user_log COMPUTE STATISTICS; ANALYZE TABLE user_log COMPUTE STATISTICS FOR COLUMNS;
据工信部相关数据支持,定期维护统计信息可使查询性能提升30%以上,尤其在复杂查询场景下效果显著。
Q&A:关于Hive表整理分区数据库的常见问题
Hive表整理分区数据库时,如何避免元数据锁竞争?
在并发写入场景下,多个任务同时修改元数据可能导致锁竞争,解决方案包括:使用独立的元数据服务实例,避免与生产环境共享;在写入前对分区键进行预聚合,减少并发写入的分区数量;采用ACID事务表(如ORC格式)时,确保事务管理器配置合理,避免长事务占用锁资源。
分区键选择错误导致数据倾斜,如何快速补救?
若发现查询性能急剧下降,首先通过EXPLAIN分析执行计划,确认是否存在数据倾斜,补救措施包括:对倾斜的Key添加随机前缀,进行两阶段聚合(先局部聚合再全局聚合);或者重新设计分区键,将高基数字段改为二级分区,或引入分桶机制分散数据。
Hive表整理分区数据库后,是否需要重新加载所有数据?
不需要,分区整理主要涉及元数据维护和文件合并,不影响数据内容,只需执行MSCK REPAIR TABLE同步元数据,并配置小文件合并参数即可,对于历史数据,可通过重新运行ETL任务进行增量整理,无需全量重建。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/449909.html